- Home
- Blog
- SQL Server
- What is PolyBase in SQL Server

- SQL Server Cluster
- SQL Server Constraints with Example
- Error Handling in SQL Server
- SQL Server Joins
- R Data Tables Tutorial with Examples
- SQL Server 2019: New Features
- SQL Server DBA Interview Questions
- SQL Server Interview Questions
- SQL Server Interview Questions for 2-5 Years Experienced
- Top 10 SQL Server Interview Questions for 5 years Experienced
- SQL Server Tutorial
- Creating a PowerPivot Data Model in Excel 2013
- How to Implement In-Memory OLTP SQL Server
- Creating a Power View Report in Excel
- SQL Server In-Memory OLTP Architecture Overview
- In-Memory OLTP integration and application migration In SQL Server
- SQL Server In-Memory OLTP Investments
- Introducing Power BI for Office 365 – SQL Server
- Creating a Power Map Reporting Content from SQL Server
- Platform For Hybrid Cloud
- Database Testing Interview Questions
- Magento Interview Questions
- What is Magento - A Complete Tutorial Guide
- SQL Joins Interview Questions
- T-SQL Tutorial
- DBMS Interview Questions
- SQL Server Architecture - Detailed Explanation
- RDBMS Interview Questions
- BigQuery Interview Questions
- DB2 Interview Questions
- Testing Connection to SQL Server
- How to Install Microsoft SQL Server?
One of the more intriguing features included with SQL Server is PolyBase, a transparent access layer that facilitates connectivity between the database engine and external data sources containing unstructured or semi-structured data. PolyBase is optimized for data warehouse workloads and analytical query processing, making it easier than ever to merge big data into the SQL Server universe. It is a technology that accesses and combines both non-relational and relational data, all from within SQL Server. In this article, we are going to talk all about What is PolyBase.
If you want to learn how to use SQL Server, from beginner to advanced techniques, then visit Mindmajix- A Global online training platform: “SQL Server Training” Course. This course will help you to achieve excellence in this domain!
What is PolyBase
PolyBase was developed at the Microsoft Jim Gray Systems Lab at the University of Wisconsin-Madison under the direction of Dr. David DeWitt, a Microsoft Technical Fellow. It provides an interface that allows you to work with data stored in HDFS by using SQL syntax in PDW queries—in a manner similar to querying a linked server from SQL Server rather than MapReduce jobs. You can even use PolyBase to join relational data in PDW with data in HDFS, as shown in Figure 6.7. In addition, you can use PolyBase to move data from PDW to HDFS or vice versa. Furthermore, you can use Power Query or Power Pivot to connect to PDW and use PolyBase to import data from HDFS into Excel.
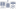
FIGURE 6.7: PolyBase as an HDFS bridge between Hadoop and PDW.

Benefits of PolyBase
The most obvious benefit of the availability of PolyBase in PDW is the ability to combine both relational and nonrelational data into a single result set, but there are several others. In particular, database professionals already familiar with developing SQL queries to retrieve data from PDW for reporting and analytical applications have nothing new to learn when they need to query non-relational data. There is no need to learn MapReduce, nor is there any need to learn how to use the other tools in the Hadoop ecosystem, such as HiveQL, Pig, or Sqoop. Existing SQL skills are sufficient.
Another benefit is faster results from queries to HDFS. PolyBase is able to perform read and write operations in parallel much faster by taking advantage of the massively parallel processing (MPP) of PDW. Whereas using Sqoop is effective for moving data in and out of a relational database, it processes data serially and interfaces with the PDW control node. By contrast, PolyBase not only parallelizes data transfers but also moves data directly from Hadoop data nodes to PDW compute nodes, as shown in Figure 6.8.
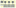
FIGURE 6.8: Parallel data transfer between PDW compute nodes and Hadoop data nodes.
Lastly, PolyBase is highly flexible. It is not limited to a single operating system or Hadoop distribution. In addition, it supports any type of HDFS file format. This means that you can use PolyBase to deliver data from all types of unstructured sources across the entire Microsoft BI stack. You can connect to PDW with ad hoc analysis tools like Excel and Power BI or distribute standard reports by using Reporting Services. You can even use data from PDW in Analysis Services multidimensional or tabular models to enrich it with business logic and other BI features.
Frequently Asked SQL Server Interview Questions & Answers
Accessing HDFS data from PDW
The work that PolyBase performs to retrieve data from HDFS is transparent during queries. The only requirement is that you create an external table to define the schema that PDW can then query. You can then interact with data in HDFS files in multiple ways, either by moving data between systems or by querying both systems and joining the results.
Let’s say you want to export data from a PDW table called FactInventory and store the results in a text file on your on-premises Hadoop cluster. You use Create Table As Select syntax to create an external table and transfer data from PDW into a file in HDFS, like this:
You can then write queries that reference both PDW and external tables pointing to HDFS, as shown here:
SELECT sl.machineName, m.machineDescription, m.machineStartDate, sl.eventDat FROM ServerLogs sl
JOIN DimMachine m
ON sl.machineName = m.machineNameList of Related Microsoft Certification Courses:
| SSIS | Power BI |
| SSRS | SharePoint |
| SSAS | SQL Server DBA |
| SCCM | BizTalk Server |
| Team Foundation Server | BizTalk Server Administrator |
 On-Job Support Service
On-Job Support Service
Online Work Support for your on-job roles.

Our work-support plans provide precise options as per your project tasks. Whether you are a newbie or an experienced professional seeking assistance in completing project tasks, we are here with the following plans to meet your custom needs:
- Pay Per Hour
- Pay Per Week
- Monthly
| Name | Dates | |
|---|---|---|
| SQL Server Training | Aug 01 to Aug 16 | View Details |
| SQL Server Training | Aug 04 to Aug 19 | View Details |
| SQL Server Training | Aug 08 to Aug 23 | View Details |
| SQL Server Training | Aug 11 to Aug 26 | View Details |

Arogyalokesh is a Technical Content Writer and manages content creation on various IT platforms at Mindmajix. He is dedicated to creating useful and engaging content on Salesforce, Blockchain, Docker, SQL Server, Tangle, Jira, and few other technologies. Get in touch with him on LinkedIn and Twitter.



