
- Configuring Account Server - Openstack
- Installing OpenStack Dashboard
- OpenStack Object Storage Tutorial
- OpenStack Interview Questions
- OpenStack Tutorial
- Attaching volumes to an instance – OpenStack
- Automating OpenStack Installations of Opscode Chef Server and Chef Client - OPENSTACK
- Automatically assigning and modifying fixed networks of tenants – OpenStack
- Checking OpenStack Services
- Configuring Object Server - OpenStack
- Configuring OpenStack Compute for Cinder volume - Openstack
- Creating containers - Openstack
- Creating and Deleting a Neutron network – OpenStack
- Creating an external Neutron network – OpenStack
- Creating and Managing Keypairs - OpenStack
- Creating an OpenStack Object Storage sandbox environment
- Creating a sandbox Compute server with VirtualBox and Vagrant - OpenStack
- Creating a sandbox Network server for Neutron with VirtualBox and Vagrant – OpenStack
- How to Create the Service Tenant and Service Users - Openstack
- OpenStack – Detaching volumes from an instance
- Downloading objects In OpenStack
- Configuring OpenStack Keystone user & Role Management - OpenStack
- How to Configure Ubuntu Cloud Archive in OpenStack
- How to Create Sandbox Environment for the OpenStack
- Create Tenant Users and Roles in OpenStack
- Install and Configure Compute Node – OpenStack
- How to Install Compute Controller Services – OpenStack
- Installing and configuring OVS and API server for Neutron - OpenStack
- Installing and setting up Pacemaker and Corosync - Highly Available OpenStack
- Managing Images with OpenStack Image Service
- Manually associating and dissociating floating IPs of instances – OpenStack
- Monitoring Compute services with Munin – OpenStack
- Monitoring OpenStack services with Nagios
- OpenStack Networking
- Registering a remotely stored image – OpenStack Cloud
- OpenStack – Removing nodes from a cluster
- Setting up a Chef Environment for OpenStack
- Troubleshooting OpenStack
- Troubleshooting OpenStack Authentication and Networking
- Troubleshooting OpenStack Compute Services
- Uploading Large Objects In OpenStack
- Using OpenStack Dashboard to Launch and Terminate Instances
- Using OpenStack Object Storage
- Starting OpenStack Block Storage
- Stopping and starting Nova services - Openstack
- Why OpenStack is Popular?
This tutorial gives you a complete description and steps to create an OpenStack sandbox environment. OpenStack Sandbox is an easy way to use OpenStack cloud software.
OpenStack Advanced Tutorial for Beginners
Create Sandbox Environment
Creating a sandbox environment by using VirtualBox and Vagrant allows us to discover and experiment with the OpenStack Compute service. VirtualBox gives us the ability to spin up virtual machines and networks without affecting the rest of our working environment and is freely available at https://www.virtualbox.org for Windows, Mac OS X, and Linux. Vagrant allows us to automate this task, which means we can spend less time creating our test environments and more time using OpenStack. Vagrant can be installed using Ubuntu’s package management, but for another operating system, visit https://www.vagrantup.com/. This test environment is then used for the rest of this tutorial. It is assumed that the computer you will be using to run your test environment has enough processing power, including hardware virtualization support (for example, Intel VT-X and AMD-V have support with at least 8 GB RAM).
Note that we’re creating a virtual machine which in turn is used to spin up virtual machines, so the more RAM you have, the better it would be.
| To gain in-depth knowledge and be on par with practical experience, then explore the OpenStack Training course. |
Getting started: To begin with, we must download VirtualBox from https://www.virtualbox.org/ and then follow the installation procedure once it is downloaded. We also need to download and install Vagrant, which will be covered in the later section. The steps throughout the book assume the underlying operating system that will be used to install OpenStack on Ubuntu 12.04 LTS release. We don’t need to download an Ubuntu 12.04 ISO as we use our Vagrant environment for this purpose.
How to achieve it: To create a sandbox environment within VirtualBox, we will use Vagrant to define a single virtual machine that allows us to run all of the OpenStack Compute services required to run cloud instances. This virtual machine, which we will refer to as the OpenStack Controller, will be configured with at least 2 GB RAM and 20 GB of hard drive space and have three network interfaces. Vagrant automatically sets up an interface on our virtual machine, that is, NAT (Network Address Translate), which allows our virtual machine to connect to the network outside of VirtualBox to download packages. This NAT interface is not mentioned in our Vagrant file but will be visible on our virtual machine as ‘eth0’. We configure our first interface for use in our OpenStack environment, which will be the public interface of our OpenStack Compute host, a second interface will be for our private network that OpenStack Compute uses for internal communication between different OpenStack Compute hosts, and a third interface will be used when we look at Neutron networking in Chapter 8, “OpenStack Networking, as an external provider network”.
| Related Article: OpenStack Object Storage |
Carry out the following steps to create a virtual machine with Vagrant that is in turn used to run OpenStack Compute services:
- Install VirtualBox from https://www.virtualbox.org/. You will encounter issues if you are using the version shipped with Ubuntu 12.04 LTS
Tip: The book was written using VirtualBox Version 4.2.16.
- Install Vagrant from https://www.vagrantup.com/. You will encounter issues if you are using the version shipped with Ubuntu 12.04 LTS.
Tip: The book was written using Vagrant Version 1.2.7.
- Once installed, we can define our virtual machine and networking in a file called Vagrant file. To do this, we will create a working directory (for example, creates ~/ cookbook and edit a file in here called Vagrantfile as shown in the following command snippet:
.png&w=16&q=75)
- We can now proceed to configure Vagrant by editing this file with the following code:
.PNG&w=16&q=75)
- We are now ready to power on our controller node. We do this by simply running the following command:
vagrant up controllerNote: Hurray! We have successfully created the VirtualBox virtual machine running on Ubuntu 12.04 which is now able to run OpenStack Controller services.
| Related Article: OpenStack Network |
How it works: What we have done here is create a virtual machine within VirtualBox by defining it in Vagrant. Vagrant then configures this virtual machine, based on the settings given in Vagrantfile in the directory where we want to store and run our VirtualBox virtual machines from. This file is based on Ruby syntax, but the lines are relatively self-explanatory. We have specified some of the following:
- The hostname is called “controller”
- The VM is based on Precise64, an alias for Ubuntu 12.04 LTS 64-bit
- We have specified 2GB RAM, 1 CPU, and an extra hard disk attached to our VM called “controller-cinder.vdi” that we will utilize later in our book.
We then launch this VirtualBox VM using Vagrant with the help of the following simple command:
vagrant upThis will launch all VMs listed in the Vagrantfile. As we have only one, this VM is the only one that has been started. To log in to this new virtual machine, we use the command as below:
vagrant ssh controllerA Vagrant and VirtualBox are not the only products for setting up a test environment. There are several numbers of other virtualization products available that are suitable for trying OpenStack, for example, VMware Server, VMware Player, and VMware Fusion, etc.
| Related Article: OpenStack Authentication |
Create a Sandbox Compute Server
Creating a sandbox server for running the OpenStack Compute services is very easy using VirtualBox and Vagrant. It allows us to discover and experiment with the OpenStack services.
VirtualBox gives us the ability to spin up virtual machines and networks without affecting the rest of our working environment and is freely available for Windows, Mac OSX, and Linux. Vagrant allows us to automate this task, meaning we can spend less time creating our test environments and more time using OpenStack. A Vagrant is installable using Ubuntu’s package management. This test environment is being used for the rest of this section.
It is assumed that the computer you will be using to run your test environment in has enough processing power that includes hardware virtualization support (modern AMDs and Intel IX processors) with at least 8 GB RAM. Remember, we’re creating a virtual machine that itself will be used to spin up other virtual machines, so the more RAM you have, the better it would be.

Getting started: To begin with, ensure that VirtualBox and Vagrant are installed and networking is set up as described in the Previous Post, Keystone OpenStack Identity Service.
How to achieve it: To create our sandbox server for running OpenStack Compute within VirtualBox, we will use Vagrant to define a second virtual machine that allows us to run OpenStack Cloud instances. This virtual machine, which we will refer to as the OpenStack Compute node, will be configured with at least 3 GB RAM, 2 CPUs, and 20 GB of hard drive space, and has three network interfaces. The first will be a NAT interface that allows our virtual machine to connect to the network outside of VirtualBox to download packages, the second interface which is the public interface of our OpenStack Compute host, and the third interface will be in our private network that OpenStack Compute uses for internal communication between different OpenStack Compute hosts.
| Related Article: OpenStack Dashboard to launch instances |
Carry out the following steps to create the virtual machine with Vagrant that will be used to run OpenStack Compute services:
- Execute the steps mentioned in the ‘Creating a sandbox environment’ with a VirtualBox recipe of Previous Post, Keystone OpenStack Identity Service.
- We are now editing the Vagrant file we have been working with, it looks like the following to add in our compute node:
-*- mode: ruby -*-
vi: set ft=ruby :
nodes = { => [1, 200],
‘controller’
‘compute’ => [1, 201],
}
Vagrant.configure(“2”) do |config| config.vm.box = “precise64” config.vm.box_url
=”https://files.vagrantup.com/precise64.box”
nodes.each do |prefix, (count, ip_start)| count.times do |i|
hostname = “%s” % [prefix, (i+1)]
config.vm.define “#{hostname}” do |box| box.vm.hostname = “#{hostname}.book” box.vm.network :private_network, ip:
“172.16.0.#{ip_start+i}”, :netmask => “255.255.0.0”
box.vm.network :private_network, ip: “10.10.0.#{ip_start+i}”, :netmask =>
“255.255.0.0”
# If using VirtualBox
box.vm.provider :virtualbox do |vbox| vbox.customize [“modifyvm”, :id,
“–memory”, 1024]
if prefix == “compute”
vbox.customize [“modifyvm”, :id, “–memory”, 3172]
vbox.customize [“modifyvm”, :id, “–cpus”, 2]
end
end
end
end
end
end- We are now ready to power on our compute node. We do this by simply running the following command:
vagrant up computeNote: Congratulations! We have successfully created the VirtualBox virtual machine running Ubuntu 12.04, which is able to run OpenStack Compute.
How it works: What we have done here is create a virtual machine within VirtualBox by defining it in Vagrant. Vagrant then configures this virtual machine, based on the settings given in the Vagrant file in the directory where we want to store and run our VirtualBox virtual machines from. This file is based on Ruby syntax, but the lines are relatively self-explanatory. We have specified the following:
- The hostname is called to compute
- The VM is based on Precise64, an alias for Ubuntu 12.04 LTS 64-Bit. We have specified 3GB Ram and two CPUs.
- We then launch this VirtualBox VM using Vagrant with the help of the following simple command:
vagrant up computeStill more: There are a number of virtualization products available that are suitable for trying OpenStack, for example, VMware Server, VMware Player, and VMware Fusion, etc.
| Related Article: OpenStack Tutorial |
Creating Containers in OpenStack
A container can be thought of as a root folder under our OpenStack Object Storage. In the OpenStack dashboard, you can only manage containers and objects.
In OpenStack Object Storage, containers provide storage for objects in a manner similar to a Windows folder or Linux file directory, though they cannot be nested. An object in OpenStack consists of the file to be stored in the container and any accompanying metadata.
They allow for objects to be stored within them. Creating objects and containers can be achieved in a number of ways. A simple way is by using the swift client tool. We run this client tool against our OpenStack Identity Service, which in turn has been configured to communicate to our OpenStack Object Storage Proxy Service and allows us to create, delete, and modify containers and objects in our OpenStack Object Storage environment.
Getting started: Log into a computer or a server that has the swift client package installed.
How to do it: Carry out the following steps to create a container under OpenStack Object Storage:

How it works: The creation of containers using the supplied swift tool is very simple. The syntax is as follows:

This authenticates our user through OpenStack Identity Service using Version 2.0 authentication, which in turn connects to the OpenStack Object Storage endpoint configured for this tenant and executes the required command to create the container.
Making Rings in Openstack
The rings determine where data should reside in the cluster. There is a separate ring for account databases, container databases, and individual object storage policies but each ring works in the same way. These rings are externally managed, in this the server processes themselves, but do not modify the rings, they are instead provided with new rings modified by other tools.
The final step is to create the Object ring, Account ring, and Container ring in which, each of our virtual nodes exists.
Getting started: Ensure that you are logged in to your swift virtual machine. To accomplish this, run:.PNG&w=16&q=75)
How to do it: The OpenStack Object Storage ring keeps track of where our data exists in our cluster. There are three rings that OpenStack Storage understands, and they are the Account, Container, and Object rings. To facilitate quick rebuilding of the rings in our cluster, we will create a script that performs the necessary steps.
- The most convenient way to create the rings for our OpenStack Storage environment is to create a script. Create /usr/loca/bin/remakerings :
#!/bin/bash
cd /etc/swift
rm -f *.builder *.ring.gz backups/*.builder backups/*.ring.gz
# Object Ringswift-ring-builder object.builder create 18 3 1
swift-ring-builder object.builder add z1-127.0.0.1:6010/sdb1 1
swift-ring-builder object.builder add z2-127.0.0.1:6020/sdb2 1
swift-ring-builder object.builder add z3-127.0.0.1:6030/sdb3 1
swift-ring-builder object.builder add z4-127.0.0.1:6040/sdb4 1
swift-ring-builder object.builder rebalance
# Container Ring
swift-ring-builder container.builder create 18 3 1
swift-ring-builder container.builder add z1-127.0.0.1:6011/sdb1 1
swift-ring-builder container.builder add z2-127.0.0.1:6021/sdb2 1
swift-ring-builder container.builder add z3-127.0.0.1:6031/sdb3 1
swift-ring-builder container.builder add z4-127.0.0.1:6041/sdb4 1
swift-ring-builder container.builder rebalance
# Account Ring
swift-ring-builder account.builder create 18 3 1
swift-ring-builder account.builder add z1-127.0.0.1:6012/sdb1 1
swift-ring-builder account.builder add z2-127.0.0.1:6022/sdb2 1
swift-ring-builder account.builder add z3-127.0.0.1:6032/sdb3 1
swift-ring-builder account.builder add z4-127.0.0.1:6042/sdb4 1
swift-ring-builder account.builder rebalance- Now we can run the script as follows:
sudo chmod +x /usr/local/bin/remakerings
sudo /usr/local/bin/remakerings- You will see output similar to the following:
Device z1-127.0.0.1:6010/sdb1_”” with 1.0 weight got id 0
Device z2-127.0.0.1:6020/sdb2_”” with 1.0 weight got id 1
Device z3-127.0.0.1:6030/sdb3_”” with 1.0 weight got id 2
Device z4-127.0.0.1:6040/sdb4_”” with 1.0 weight got id 3
Reassigned 262144 (100.00%) partitions. Balance is now 0.00.
Device z1-127.0.0.1:6011/sdb1_”” with 1.0 weight got id 0
Device z2-127.0.0.1:6021/sdb2_”” with 1.0 weight got id 1
Device z3-127.0.0.1:6031/sdb3_”” with 1.0 weight got id 2
Device z4-127.0.0.1:6041/sdb4_”” with 1.0 weight got id 3
Reassigned 262144 (100.00%) partitions. Balance is now 0.00.
Device z1-127.0.0.1:6012/sdb1_”” with 1.0 weight got id 0
Device z2-127.0.0.1:6022/sdb2_”” with 1.0 weight got id 1
Device z3-127.0.0.1:6032/sdb3_”” with 1.0 weight got id 2
Device z4-127.0.0.1:6042/sdb4_”” with 1.0 weight got id 3
Reassigned 262144 (100.00%) partitions. Balance is now 0.00.How it works: In Swift, a ring functions just like a cereal box decoder ring. That is, it keeps track of where various bits of data reside in a given swift cluster. In our example, we have provided details for creating the rings as well as executed a rebuild of said rings. Creation of the rings is done using the swift-ring-builder command and involves the
following steps, repeated for each ring type (Object, Container, and Account):
1. Creating the ring (of type Object, Container, or Account): To create the ring, we use the following syntax:
.PNG&w=16&q=75)
The creation of the ring specifies a builder file to create three parameters:
part_power, replicas, and min_part_hours. This means 2^part_power (18 is used in this instance) is the number of partitions to create, replicas are the number of replicas (3 is used in this case) of the data within the ring, and min_part_hours (1 is specified in this case) is the time in hours before a specific partition can be moved in succession.
2. Assigning a device to the ring: To assign a device to a ring, we use the following syntax:.PNG&w=16&q=75)
Adding a node to the ring specifies the same builder_file created in the first step. We then specify a zone (for example, 1, prefixed with z) that the device will be in, ip (127.0.0.1) is the IP address of the server that the device is in, port (for example, 6010) is the port number that the server is running on, and device_name is the name of the device on the server (for example, sdb1). The weight is a float weight that determines how many partitions are put on the device, relative to the rest of the devices in the cluster.
3. Rebalancing the ring: A balanced Swift ring is one where the number of data exchanges between nodes is minimized while still providing the configured number of replicas. To rebalance the ring, we use the following syntax within the /etc/swift directory:.PNG&w=16&q=75)
This command will distribute the partitions across the drives in the ring. The previous process is run for each of the rings: object, container, and account.
Removing nodes from a cluster
Converse to adding capacity to our OpenStack Object Storage cluster, there may be times where we need to scale back or remove a failed node for service. You may need to remove a compute node from a cluster for troubleshooting or maintenance reasons.
We can do this by removing nodes from the zones in our cluster. In the following example, we will remove node 172.16.0.212 in z5, which only has one storage device attached, /dev/sdb1.
Getting started: Log in to the OpenStack Object Storage Proxy Server. To log on to our OpenStack Object Storage Proxy host that was created using Vagrant, issue the following command:
How to achieve it: Carry out the following to remove a storage node from a zone:
Proxy Server
To remove a node from OpenStack Object Storage, we first set its weight to be 0, so that when the rings get rebalanced, data is drained away from this node:
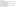
We then rebalance the rings as follows:

Once this is done, we can remove the node in this zone from the ring, as follows:
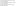
We then copy the resultant ring.gz, container.ring.gz, and object.ring.gz files over to the rest of the nodes in our cluster. We are now free to decommission this storage node by physically removing this device.
How it works: Manually removing a node from our OpenStack Object Storage cluster is done in three steps:
- Setting the node’s weight to be 0, so the data isn’t being replicated to it, by using the swift-ring-builder set-weight command.
- Rebalancing the rings to update the data replication.
Removing the node from OpenStack object storage cluster, using the swift-ring-builder remove command. Once done, we are then free to decommission that node. We repeat it for each node (or device) in the zone.
| Related Article: Creating a sandbox Network server for Neutron with VirtualBox |
Creating the Service Tenant and Service Users
After you install the Identity service, create tenants (projects), users, and roles for your environment to authenticate against. Without users, the OpenStack cloud does not have much value as they allow access to services and endpoints.
With the service endpoints already created, we can now configure them so that our OpenStack services can utilize them. To do this, each service is configured with a username and password within a special service tenant. Configuring each service to have its own username and password allows for greater security, troubleshooting and, auditing within our environment. For each service that uses an OpenStack Identity service for authentication and authorization, we specify these details in their relevant configuration file, when setting up that service. Each service itself has to authenticate with keystone in order for it to be available within OpenStack. The configuration of that service is then done using these credentials. For example, for ‘glance’ we specify the following in /etc/ glance/glance-registry-api.ini, when used with OpenStack Identity service, which matches what we have created previously:
[filter:authtoken]
paste.filter_factory =
keystone.middleware.auth_token:filter_factory
service_protocol = http
service_host = 172.16.0.200
service_port = 5000
auth_host = 172.16.0.200
auth_port = 35357
auth_protocol = http
auth_uri = https:// 172.16.0.200: 5000/
admin_tenant_name = service
admin_user = glance
admin_password = glanceGetting started: To begin with, ensure you’re logged into our OpenStack Controller host— where OpenStack Identity service has been installed— or an appropriate Ubuntu client that has access to where OpenStack Identity service is installed.
To log on to our OpenStack Controller host that was created using Vagrant, issue the following command:
vagrant ssh controllerIf the keystone client tool isn’t available, this can be installed on an Ubuntu client to manage our OpenStack Identity service, by issuing the following command:
sudo apt-get update
sudo apt-get -y install python-keystoneclientEnsure that we have our environment set correctly to access our OpenStack environment:
export ENDPOINT = 1172.16.0.200
export SERVICE_TOKEN = ADMIN
export
SERVICE_ENDPOINT = https:// ${ ENDPOINT}: 35357/ v2.0To configure an appropriate service tenant, carry out the following steps:
1) Create the service tenant (these are the organizational units in cloud to which you can assign users) as follows:
keystone tenant-create
–name service
–description “Service Tenant”
–enabled trueThis produces output similar to what is shown as follows:.png&w=16&q=75)
2) Record the ID of the service tenant, so that we can assign service users to this ID, as follows:
SERVICE_TENANT_ID = $( keystone tenant-list | awk ‘/ service / {print $ 2}’)3) For each of the services in this section, we will create the user accounts to be named the same as the services and set the password to be the same as the service name too. For example, we will add a user called a nova, with a password nova in the service tenant, using the user-created option, as follows:
keystone user-create
–name nova –pass nova
–tenant_id $ SERVICE_TENANT_ID
–email nova@ localhost
–enabled trueThis will produce output similar to what is shown as follows:
.png&w=16&q=75)
4) We then repeat this for each of our other services that will use the OpenStack Identity service:
keystone user-create
–name glance
–pass glance
–tenant_id $ SERVICE_TENANT_ID
–email glance@ localhost
–enabled true
keystone user-create
–name keystone
–pass keystone
–tenant_id $ SERVICE_TENANT_ID
–emailkeystone@ localhost
–enabled true
keystone user-create
–name cinder
–pass cinder
–tenant_id $ SERVICE_TENANT_ID
–email cinder@ localhost
–enabled true5) We can now assign these users the admin role in the service tenant. To do this, we use the user-role-add option after retrieving the user ID of the nova user. For example, to add the admin role to the nova user in the service tenant, we do the following:
# Get the nova user id
NOVA_USER_ID = $( keystone user-list | awk ‘/ nova / {print $ 2}’)
# Get the admin role id
ADMIN_ROLE_ID = $( keystone role-list | awk ‘/ admin / {print $ 2}’)
# Assign the nova user the admin role in service tenant
keystone user-role-add
–user $ NOVA_USER_ID
–role $ ADMIN_ROLE_ID
–tenant_id $ SERVICE_TENANT_ID# Get the nova user id
NOVA_USER_ID = $( keystone user-list | awk ‘/ nova / {print $ 2}’)
# Get the admin role id
ADMIN_ROLE_ID = $( keystone role-list | awk ‘/ admin / {print $ 2}’)
# Assign the nova user the admin role in service tenant
keystone user-role-add
–user $ NOVA_USER_ID
–role $ ADMIN_ROLE_ID
–tenant_id $ SERVICE_TENANT_ID6) We then repeat this for our other service users, glance, keystone, and cinder:
# Get the glance user id
GLANCE_USER_ID = $( keystone user-list | awk ‘/ glance / {print $ 2}’)
# Assign the glance user the admin role in service tenant
keystone user-role-add
–user $ GLANCE_USER_ID
–role $ ADMIN_ROLE_ID
–tenant_id $ SERVICE_TENANT_ID
# Get the keystone user id
KEYSTONE_USER_ID = $ (keystone user-list | awk ‘/ keystone / {print $ 2}’)
# Assign the keystone user the admin role in service tenant
keystone user-role-add
–user $ KEYSTONE_USER_ID
–role $ ADMIN_ROLE_ID
–tenant_id $ SERVICE_TENANT_ID
# Get the cinder user id
CINDER_USER_ID = $ (keystone user-list | awk ‘/ cinder / {print $ 2}’)
# Assign the cinder user the admin role in service tenant
keystone user-role-add
–user $ CINDER_USER_ID
–role $ ADMIN_ROLE_ID
–tenant_id $ SERVICE_TENANT_IDProjects, roles, and tenants can be managed independently from each other.
| Related Article: Configuring Ubuntu Cloud |
How it works: Creation of the service tenant, populated with the services required to run OpenStack, is no different from creating any other users on our system that requires the admin role. We create the usernames and passwords and ensure they exist in the service tenant with the admin role assigned to each user. We then use these credentials while configuring the services to authenticate with the OpenStack Identity service.
Configure Database Services
Each of the core OpenStack services (Compute, Identity, Networking, Block Storage) stores state and configuration information in databases. The Database service provides a scalable and reliable Cloud Database-as-a-Service functionality for both relational and non-relational database engines. Users can quickly and easily use database features without the burden of handling complex administrative tasks.
OpenStack supports a number of database backends—an internal SQLite database (the default), MySQL, and Postgres. Many OpenStack services maintain a database to keep track of critical resources, usage, and other information. By default, individual SQLite databases are specified for this purpose and are useful for the single-node configuration. For multi-node configurations, a MySQL database is recommended for storing this information.
SQLite is used only for testing and is not supported in an nt, whereas MySQL or Postgres usage is down to the experience of the database staff. For the remaining fields of this tutorial, we shall use MySQL.
Setting up MySQL is easy and allows you to grow this environment as you progress through the chapters of this tutorial.
Getting started: We will configure our OpenStack Controller services to use MySQL as the database backend, so this needs to be installed prior to configuring our OpenStack Compute environment.
Tip: Refer to the recipe Installing OpenStack Identity Service in Chapter 1, and also Keystone OpenStack Identity Service, for instructions on setting up MySQL.
If you are not already on the OpenStack Controller, ssh into this using Vagrant as follows:
vagrant ssh controllerHow to achieve it: To use OpenStack Compute (Nova), we first need to assure that our backend database has been equipped with the required nova database. To create this, follow the steps below on our controller host running MySQL:
1. With MySQL running, we configure an appropriate database user, called Nova, and privileges for use by OpenStack Compute:
MYSQL_ROOT_PASS=openstack
mysql -uroot -p$MYSQL_ROOT_PASS -e ‘CREATE DATABASE nova;’
MYSQL_NOVA_PASS=openstack
mysql -uroot -p${MYSQL_ROOT_PASSWORD}
-e “GRANT ALL PRIVILEGES ON nova.* TO ‘nova’@’%’ IDENTIFIED BY ‘${MYSQL_NOVA_PASSWORD}’;”
mysql -uroot -p${MYSQL_ROOT_PASSWORD}
-e “GRANT ALL PRIVILEGES ON nova.* TO ‘nova’@’localhost’ IDENTIFIED BY ‘${MYSQL_NLOVA_PASSWORD}’;”2. We now simply refer our MySQL server in our /etc/nova/nova.conf file to use MySQL by adding in the sql_connection flag:
sql_connection=mysql://nova:openstack@172.16.0.200/novaHow it works: MySQL is an essential service to OpenStack as a number of services rely on it. Configuring MySQL appropriately assures that your servers operate smoothly. We added a database called Nova that will eventually be populated by tables and data from the OpenStack Compute services and grant all privileges to the Nova database user so that the user can use it.
Finally, we configured our OpenStack Compute installation to specify these details so that they can use the Nova database.
| Related Article: OpenStack Interview Questions |
Installing OpenStack Identity service
The OpenStack identity service performs the following functions:
- Tracking users and their permissions.
- Providing a catalog of available services with their API endpoints.
When installing the OpenStack Identity service, you must register each service in your OpenStack installation. Identity service can then track which OpenStack services are installed, and where they are located on the network.
Here in this article, we will be knowing about the installation and configuration of the OpenStack Identity service, known as Keystone, using the Ubuntu Cloud Archive. Keystone is an identity service that manages user databases and OpenStack service catalogs and their API endpoints. It integrates with existing backend directory services like LDAP and supports multiple authentication mechanisms, such as username-and-password, token-based systems, and AWS-style logins. Once configured, connecting to our OpenStack cloud environment will be performed through our new OpenStack Identity service.
The backend data store for our OpenStack Identity service will be a MySQL database.
Getting started: To ensure that running Ubuntu Cloud Archive is running, we must first configure our Ubuntu 12.04 installation to use this service.
We will configure Keystone to use MySQL as the database backend, so this needs to be installed prior to installing Keystone. If MySQL is not installed, execute the following steps to install and configure MySQL:
MYSQL_ROOT_PASS = openstack
MYSQL_HOST = 172.16.0.200# To enable non-interactive installations of MySQL, set the following
.PNG&w=16&q=75)
.PNG&w=16&q=75)
.PNG&w=16&q=75)
Successively ensure that you're logged into the nominated OpenStack Identity server or OpenStack Controller host where OpenStack Identity service must be installed and the rest of the OpenStack hosts can have access to.
| Related Article: How to progress with OpenStack? |
To log on to our OpenStack Controller host that was created using Vagrant, issue the following command:
vagrant ssh controllerHow to achieve it: Carry out the following simple instructions to install the OpenStack Identity service:
1) Installation of OpenStack Identity service is achieved by specifying the keystone package in Ubuntu, and we perform it as follows:
sudo apt-get update
sudo apt-get -y install keystone python-keyring2) Once installed, we need to configure the backend database store, for that we must first create the keystone database in MySQL. We do this as shown (it has a user in MySQL called root, with password OpenStack, that is able to create databases):
MYSQL_ROOT_PASS = openstack
mysql -uroot -p $ MYSQL_ROOT_PASS -e “CREATE DATABASE
keystone;”3) It is a good practice to create a user which is specific to our OpenStack Identity service, so we create this as follows:
.PNG&w=16&q=75)
4) We then need to configure an OpenStack Identity service to use this database by editing the /etc/ keystone/ keystone.conf file, and then change the sql_connection line to match the database credentials. We do this as follows:
.PNG&w=16&q=75)
5) A super-user admin token resides in the /etc/ keystone/ keystone.conf file. To configure this we do the following:
.png&w=16&q=75)
6) As of the Grizzly release, Keystone supports PKI infrastructure to cryptographically sign the tokens. To disable this feature, for now, we edit the /etc/ keystone/ keystone.conf file to use non-
.PNG&w=16&q=75)
7) We can now restart the keystone service with the help of the following commands:
sudo stop keystone
sudo start keystone8) With Keystone already started, we can now populate the keystone database with the required tables, by issuing the below command:
sudo keystone-manage db_syncNote: Hurray! We now have the OpenStack Identity service installed and ready to use in our OpenStack environment.
How it works: A convenient way to install OpenStack Identity service ready for instant use in our OpenStack environment, is by using the Ubuntu packages. Once installed, we configure our MySQL database server with a keystone database and set up the keystone. conf configuration file to use this. After starting the Keystone service, running the keystone-manage db_sync command populates the keystone database with the appropriate tables ready for us to add in the required users, roles, and tenants required in our OpenStack environment.
Downloading objects In OpenStack
Now that we have configured OpenStack Object Storage, we can also retrieve the stored objects using our swift client.
Getting ready: Log in to a computer or server that has the Swift Client Package Installed.
How to achieve it: We will download objects from our OpenStack Object Storage environment using the different swift client options:
Downloading objects: To download the object tmp/test/test1, we issue the following command:

This downloads the object to our filesystem. As we downloaded a file with the full path, this directory structure is preserved, so we end up with a new directory structure of tmp/test with a file in it called test1.
Downloading objects with the -o parameter
To download the file without preserving the file structure, or to simply rename it to something else, we specify the -o parameter, as follows:
Downloading all objects from a container
We are also able to download complete containers to our local file system. To do this, we simply specify the container we want to download, as follows:

This will download all objects found under the test container.
Downloading all objects from our OpenStack Object Storage account
We can download all objects that reside under our OpenStack Object Storage account. If we have multiple containers, all objects from all containers will be downloaded. We do this with the parameter, as follows:

This will download all objects with full paths preceded by the container name, for example:
.png&w=16&q=75)
How it works: The swift client is a basic but versatile tool that allows us to do many of the things we want to do with files. Downloading objects and containers is achieved using the following syntax:
.PNG&w=16&q=75)
To download all objects from our account (for example, from all containers), we specify the following syntax:
| Related Article: OpenStack Block Storage |
Collecting usage statistics – OpenStack Cloud
OpenStack Object Storage can report on usage metrics by using the swift-recon middleware added to our object-server configuration. By using a tool, also named swift-recon, we can then query these collected metrics.
Getting started: Log in to an OpenStack Object Storage node as well as the proxy server.
How to achieve it: To collect usage statistics from our OpenStack Object Storage cluster, carry out the following steps:
- We first need to modify our /etc/swift/object-server.conf configuration file to include the swift-recon middleware, so that it looks similar to the following:
.PNG&w=640&q=75)
Once this is in place, we simply restart our object-server service, using SWIFT-INIT, as follows:
.PNG&w=16&q=75)
Now that the command is running, we can use the swift-recon tool on the proxy server to get usage statistics, as follows:
Disk usage
swift-recon -dThis will report on disk usage in our cluster.
swift-recon -d -z5This will report on disk usage in zone 5.
Load average
swift-recon -lThis will report on, the load average in our cluster.
swift-recon -l -z5This will report on the load average of the nodes in zone 5.
Quarantined statistics
swift-recon -qThis will report on any quarantined containers, objects, and accounts in the cluster.
swift-recon -q -z5This will report on this information just for zone 5.
Check for unmounted devices
swift-recon -uThis will check for any unmounted drives in our cluster.
swift-recon -z5 -uThis will do the same just for zone 5.
Check replication metrics
swift-recon -rThis will report on the replication status within our cluster.
swift-recon -r -z5This will just perform this for nodes in zone 5.
We can perform all these actions with a single command to get all telemetry data back about our cluster, as follows:
swift-recon --allWe can just get this information for nodes within zone 5 by adding -z5 at the end, as follows:
swift-recon --all -z5How it works: To enable usage statistics within an OpenStack Object Storage, we add in the swift-recon middleware, so metrics are collected. We add this to the object server by adding the following lines to /etc/swift/object-server.conf, on each of our storage nodes:
.PNG&w=16&q=75)
With this in place and our object servers restarted, we can query this telemetry data by using the swift-recon tool. We can collect the statistics from the cluster as a whole, or from specific zones with the -z parameter.
Note that we can also collect all or multiple statistics by specifying the –all flag or appending multiple flags to the command line. For example, to collect a load average and replication statistics from our nodes in zone 5, we would execute the following command:
.PNG&w=16&q=75)
Installing PuppetLabs Razor and DHCP
There are a number of provisioning systems, such as Cobbler, Kick-start, and Ubuntu’s own MAAS, to provide an operating system such as Ubuntu to bare-metal. In this instance, we are switching from Ubuntu’s Metal as a Service to the PuppetLabs Razor service to allow you more flexibility within your deployment. PuppetLabs Razor, like MAAS, provides a PXE boot environment for your OpenStack nodes. Additionally, when a node PXE boots, it boots into the Razor MicroKernel environment which in turn runs PuppetLabs Factor and reports back lots of details about the physical node. From there, you can use the Razor CLI or Razor API to query inventory details about a machine or set of machines and provision an OS to them. An additional feature is the “broker”, which allows for a hand-off to a DevOps framework. In this section, we will cover using the Razor cookbooks to install Razor onto the node.
Getting started: To get started, we need to log into our Chef Server:
vagrant ssh chefHow to achieve it: On the Chef Server, we need to configure a number of attributes for both the DHCP service as well as the Razor service before we can log into the Razor node and apply the configuration. To do this, execute the following commands:
sudo cat > ~/.chef/razor.json <<eof {="" "name":="" "razor.book",="" "chef_environment":="" "_default",="" "normal":="" "dhcp":="" "parameters":="" "next-server":="" "172.16.0.101="" ″="" },="" "networks":="" [="" "172-16-0-0_24"="" ],="" "networks_bag":="" "dhcp_networks"="" "razor":="" "bind_address":="" ,="" "images":="" "razor-mk":="" "type":="" "mk",="" "url":="" "https:="" downloads.puppetlabs.com="" razor="" iso="" dev="" rz_mk_dev-image.0.12.0.iso",="" "action":="" "add"="" "precise64="" :="" "http:="" mirror.anl.gov="" pub="" ubuntu-iso="" cds="" precise="" ubuntu-12.04.2-server-amd64.iso",="" "version":="" "12.04="" }="" "tags":="" []="" "run_list":="" "recipe[razor]",="" "recipe[dhcp::server]"="" ]="" eof="" knife="" node="" from="" file="" ~="" .chef="" razor.json=""Now that we have configured our environment, we can log into the Razor node and finish our installation:
vagrant up razor vagrant ssh razor
sudo mkdir -p /etc/chef
sudo scp user@host:/location/of/chef-validator.pem /etc/chef/validation.pem
sudo echo "172.16.0.100 chef.book" >> /etc/hosts
# Install chef client
curl -L https://www.opscode.com/chef/install.sh | sudo bash
# Make client.rb
sudo cat > /etc/chef/client.rb <
| Explore OpenStack Sample Resumes! Download & Edit, Get Noticed by Top Employers! |
How it works: In this particular section, there are a number of things happening. First, we logged into our Chef Server and created a node definition file that specifies how our Razor node should be configured. Specifically, in the “dhcp”: section we specified the “next-Server” as being the Razor node.
Additionally, configure the DHCP service to use the networking parameters we specified in the databag earlier. In the “Razor” section, we tell the Razor service to bind to our private network address. Additionally, we tell it about what images to be used and where they can be downloaded from. The last thing we configured in the node definition file was the “run_list”, or recipes to apply to the node. In this case, we specified that we want to install Razor as well as the dhcp::Server components. Once we completed our configuration on the Chef Server, we switched over to the Razor node, copied in the Chef validation certificate. This allows the Chef Client to register with the Chef Server. Next, we put an entry into the /etc/hosts file to allow our Razor Server to identify where the Chef Server is. Next, we installed and configured the Chef Client using the same curl script we did when setting up the Chef Server. Finally, we executed the Chef Client which performed a number of actions such as registering with the Chef Server and executing the recipes in our run-list.
 On-Job Support Service
On-Job Support Service
Online Work Support for your on-job roles.

Our work-support plans provide precise options as per your project tasks. Whether you are a newbie or an experienced professional seeking assistance in completing project tasks, we are here with the following plans to meet your custom needs:
- Pay Per Hour
- Pay Per Week
- Monthly
| Name | Dates | |
|---|---|---|
| OpenStack Training | Jul 18 to Aug 02 | View Details |
| OpenStack Training | Jul 21 to Aug 05 | View Details |
| OpenStack Training | Jul 25 to Aug 09 | View Details |
| OpenStack Training | Jul 28 to Aug 12 | View Details |

Ravindra Savaram is a Technical Lead at Mindmajix.com. His passion lies in writing articles on the most popular IT platforms including Machine learning, DevOps, Data Science, Artificial Intelligence, RPA, Deep Learning, and so on. You can stay up to date on all these technologies by following him on LinkedIn and Twitter.














