
- Advanced OpenStack Tutorial
- Configuring Account Server - Openstack
- Installing OpenStack Dashboard
- OpenStack Interview Questions
- OpenStack Tutorial
- Attaching volumes to an instance – OpenStack
- Automating OpenStack Installations of Opscode Chef Server and Chef Client - OPENSTACK
- Automatically assigning and modifying fixed networks of tenants – OpenStack
- Checking OpenStack Services
- Configuring Object Server - OpenStack
- Configuring OpenStack Compute for Cinder volume - Openstack
- Creating containers - Openstack
- Creating and Deleting a Neutron network – OpenStack
- Creating an external Neutron network – OpenStack
- Creating and Managing Keypairs - OpenStack
- Creating an OpenStack Object Storage sandbox environment
- Creating a sandbox Compute server with VirtualBox and Vagrant - OpenStack
- Creating a sandbox Network server for Neutron with VirtualBox and Vagrant – OpenStack
- How to Create the Service Tenant and Service Users - Openstack
- OpenStack – Detaching volumes from an instance
- Downloading objects In OpenStack
- Configuring OpenStack Keystone user & Role Management - OpenStack
- How to Configure Ubuntu Cloud Archive in OpenStack
- How to Create Sandbox Environment for the OpenStack
- Create Tenant Users and Roles in OpenStack
- Install and Configure Compute Node – OpenStack
- How to Install Compute Controller Services – OpenStack
- Installing and configuring OVS and API server for Neutron - OpenStack
- Installing and setting up Pacemaker and Corosync - Highly Available OpenStack
- Managing Images with OpenStack Image Service
- Manually associating and dissociating floating IPs of instances – OpenStack
- Monitoring Compute services with Munin – OpenStack
- Monitoring OpenStack services with Nagios
- OpenStack Networking
- Registering a remotely stored image – OpenStack Cloud
- OpenStack – Removing nodes from a cluster
- Setting up a Chef Environment for OpenStack
- Troubleshooting OpenStack
- Troubleshooting OpenStack Authentication and Networking
- Troubleshooting OpenStack Compute Services
- Uploading Large Objects In OpenStack
- Using OpenStack Dashboard to Launch and Terminate Instances
- Using OpenStack Object Storage
- Starting OpenStack Block Storage
- Stopping and starting Nova services - Openstack
- Why OpenStack is Popular?
OpenStack Object Storage (OOS) is a highly available, distributed, eventually consistent object/blob store. OpenStack Object Storage (swift) is a service that provides software, which stores and retrieves data over HTTP. For a brief summary of it, go through its Introduction.
OpenStack Object Storage
Introduction
Now that we have an OpenStack Object Storage environment running, we can use it to store our files. To do this, we can use a tool provided, named swift. This allows us to operate our OpenStack Object Storage environment by allowing us to create containers, upload files, retrieve them, and set required permissions on them, as appropriate.
So in these particular subsequent fields, you are going to get a clear idea about various usages of OOS
| If you would like to become an OpenStack Certified professional, then visit Mindmajix - A Global online training platform:" OpenStack Certification Training Course ". This course will help you to achieve excellence in this domain. |
Creating an OpenStack Object Storage sandbox environment
OpenStack Object Storage, also known as Swift, is the service that allows massively scalable and highly redundant storage on commodity hardware. This service is analogous to Amazon’s S3 storage service and is managed in a similar way under OpenStack. With OpenStack Storage, we can store many objects of virtually unlimited size—restricted by the available hardware—and grow our environment as needed, to accommodate our storage. The highly redundant nature of OpenStack Object Storage is ideal for archiving data (such as logs) as well as providing a storage system that OpenStack Compute can use for virtual machine instance templates.
In this chapter, we will set up a single virtual machine that will represent a multi-node test environment for OpenStack Object Storage. Although we are operating on a single host, the steps involve mimic a four-device setup, so we see a lot of duplication and replication of our configuration files.
Creating a sandbox environment using VirtualBox and Vagrant allows us to discover and experiment with the Open Stack Compute service. VirtualBox gives us the ability to spin up virtual machines and networks without affecting the rest of our working environment and is freely available for Windows, Mac OSX, and Linux. Vagrant allows us to automate this task, meaning we can spend less time in creating our test environments and more time in using OpenStack. A vagrant is installable using Ubuntu’s package management. This test environment can then be used for the rest of this chapter.
| Related Article: Networking in OpenStack |
It is assumed that the computer you will be using to run your test environment has enough processing power, with hardware virtualization support (modern AMDs and Intel IX processors) and at least 8 GB of RAM. The virtual machine we will be creating will have all components installed to get you familiar with the OpenStack Object Storage services.
In this section, we will use Vagrant to create an additional virtual machine. This new virtual machine will mimic a four-node Open Stack Object Storage environment. To provide identity services, we will use the existing keystone installation as built-in Chapter 1, Keystone OpenStack Identity Service.
Getting started: Before beginning this section we assume that you have all completed horecipes from Chapter 1, Keystone OpenStack Identity Service.
How to achieve an Object Storage sandbox environment
To create our sandbox environment within VirtualBox we will use Vagrant to define an additional virtual machine with three network interfaces. The first will be a NAT interface that allows our virtual machine to connect to the network outside of VirtualBox to download packages, a second interface which will be the Public interface of our OpenStack Compute host, and the third interface will be for our Private network that OpenStack Compute uses for internal communication between different OpenStack Compute hosts. This swift virtual machine will be configured with at least 1 GB RAM, and two 20 GB hard disks.
- Execute the steps mentioned in Creating a sandbox environment with VirtualBox recipe of Chapter 1, Keystone OpenStack Identity Service.
- We are now editing the Vagrant file we have been working with, thus making it look like the following:
.PNG&w=16&q=75)
Vagrant.configure(“2”) do |config| config.vm.box = “precise64” config.vm.box_url =“https://files.vagrantup.com/precise64.box”
# If using Fusion uncomment the following line #config.vm.box_url =“https://files.vagrantup.com/precise64_vmware.box”
nodes.each do |prefix, (count, ip_start)| count.times do |i|
hostname = “%s” % [prefix, (i+1)]
config.vm.define “#{hostname}” do |box| box.vm.hostname = “#{hostname}.book” box.vm.network
:private_network, IP: “172.16.0.#
{ip_start+i}”, :netmask => “255.255.0.0”
box.vm.network :private_network, IP: “10.10.0.# {ip_start+i}”, :netmask => “255.255.0.0”
# If using Fusion
box.vm.provider :vmware_fusion do |v| v.vmx[“memsize”] = 1024
end
# Otherwise using VirtualBox box.vm.provider :virtualbox do |vbox|
vbox.customize [“modifyvm”,
:id, “–memory”, 1024]if prefix == “swift”vbox.customize [“modifyvm”, :id, “–memory”, 1024]
vbox.customize [“modifyvm”,:id, “–cpus”, 1]
vbox.customize [“createhd”,“–filename”, ‘swift_disk2.vdi’, “–size”, 2000 * 1024]
vbox.customize [‘storageattach’, :id, ‘–storagectl’,‘SATA Controller’, ‘–port’, 1, ‘–device’, 0, ‘–type’, ‘hdd’,‘–medium’, ‘swift_disk2.vdi’]
end
end
end
end
end
end vagrant up
Note: Congratulations! We have successfully created the VirtualBox virtual machine running Ubuntu, which is able to run OpenStack Storage.
How it works: What we have done is create a virtual machine that will be the basis of our OpenStack Storage host. It has the necessary disk space and networking in place to allow you to access this virtual machine from your host personal computer and any other virtual machines in our OpenStack sandbox environment.
Still more: You’ll notice the preceding Vagrant file example, we have provided for a VMware Fusion configuration. Additionally, there are other virtualization products that can work outside of the Vagrant environment.
| Related Article: OpenStack Network Troubleshooting |
Administering OpenStack Object Storage
Day-to-day administration of our OpenStack Object Storage cluster involves ensuring the files within the cluster are replicated to the right number of nodes, reporting on usage within the cluster, and dealing with the failure of the cluster. This particular field builds upon the work in Using OpenStack Object Storage., to show you the tools and processes required to administer OpenStack Object Storage.
Preparing drives for OpenStack Object Storage
OpenStack Object Storage doesn’t have any dependencies on any particular filesystem, as long as that filesystem supports extended attributes (xattr). It has been generally acknowledged that the XFS filesystem yields the best all-around performance and resilience.
Getting started: Before we start, we need to add a disk to our swift node. To do this, edit your Vagrant file to include the following section:
.PNG&w=16&q=75)
Next, start your Swift node:
vagrant up swiftLog in to a swift node that has a disk ready to be formatted for use with OpenStack Object Storage:
vagrant ssh swiftHow to do it…
Carry out the following steps to prepare a hard drive for use within an OpenStack Object Storage node. For this, we will assume our new drive is ready for use, has been set up with an appropriate partition, and is now ready for formatting. Take for example the partition /dev/sdb1.
| Related Article: OpenStack Dashboard Demo |
1. To format it for use, using XFS, we run the following command:
sudo mkfs.xfs-i size=1024/dev/sdb12. This produces a summary screen of the new drive and partition, as follows:
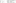
3. Once formatted, we set the mount options in our /etc/fstab file, as follows:
/dev/sdb1/srv/node/sdb1 xfs noatime, nodiratime, nobarrier, logbufs=8 0 04. Create the mount point, and mount the filesystem as follows:
mkdir-p/srv/node/sdb1 mount/srv/node/sdb1How it works: While it is recommended, you do thorough testing of OpenStack Object Storage for your own environments, it is generally recommended that you use the XFS filesystem. OpenStack Object Storage requires a filesystem that supports extended attributes (xattr) and it has been shown that XFS offers good all-round performance in all areas.
In order to accommodate the metadata used by OpenStack Object Storage, we increase the inode size to 1024. This is set at the time of the format with the -i size=1024 parameter.
Further performance considerations are set at mount time. We don’t need to record file access times (noatime) and directory access times (nodiratime). Barrier support flushes the write-back cache to the disk at an appropriate time. Disabling this yields a performance boost, as the highly-available nature of OpenStack Object Storage allows for the failure of a drive (and therefore, write of data), so this safety net in our filesystem can be disabled (with the nobarrier option), to increase speed.
| Related Article: Getting Started with OpenStack |
Register the Remotely Stored Image
Images are predominantly standard installation media such as ISO images. Several pre-made images exist and can easily be imported into the Image service.
The OpenStack Image Service (also termed as Glance) provides a mechanism to remotely add an image that is stored at an externally accessible location. It allows you to register, discover and retrieve virtual machine images for use in our OpenStack environment. This allows for a convenient method of adding images we might want to use for our private cloud that has been uploaded to an external third-party server.
Getting started: To begin with, ensure that you are logged into our Ubuntu client, where we can run the glance tool. This can be installed using the following command:
sudo apt-get update
sudo apt-get -y install glance-clientEnsure that you have your environment variable set up correctly using ‘admin’ user and password, which has been created in the previous chapter as follows:
export OS_TENANT_NAME=cookbook
export OS_USERNAME=admin
export OS_PASSWORD=openstack
export OS_AUTH_URL=https://172.16.0.200:5000/v2.0/
export OS_NO_CACHE=1How to achieve it: Carry out the following steps to remotely store an image into our OpenStack Image Service:
1. To register a remote virtual image into our environment, we add a location parameter instead of streaming the image through a pipe on our glance command line:
glance image-create
–name=’Ubuntu 12.04 x86_64 Server’
–disk-format=qcow2–container
-format=bare–public–location https://webserver/precise-server- cloudimg-amd64- disk1.img2. This returns information similar to the following which is then stored in our OpenStack Image Service:
How it works: Usage of glance tool for specifying remote images directly provides a quick and convenient way to add images to our OpenStack Image Service repository. This happens with the location parameter which we add in our usual meta information to accompany this, as we would generally do with a locally specified image.

Configuring OpenStack Object Storage proxy server
A proxy server is a component that accepts OpenStack Object storage API and raw HTTP files to accept upload files, modify data, and create containers. Clients connect to OpenStack Object Storage via a proxy server. This allows us to scale out our OpenStack Object Storage environment as needed, without affecting the front-end to which the clients connect.
Proxy servers can also use the optional cache that is used to deploy Memcache.
Getting started
vagrant ssh swiftHow to do it…
To configure the OpenStack Object Storage proxy server, we simply create the /etc/swift/proxy-server.conf file, with the following contents:
Assure that you are logged in to your swift virtual machine. To accomplish this, run:
[DEFAULT] bind_port = 8080 user = swift
swift_dir = /etc/swift
[pipeline: main]
# Order of execution of modules defined below
pipeline = catch_errors healthcheck cache authtoken keystone proxy-server
[app:proxy-server] use = egg:swift#proxy
allow_account_management = true account_autocreate = true
set log_name = swift-proxy set log_facility = LOG_LOCAL0 set log_level = INFO
set access_log_name = swift-proxy set access_log_facility = SYSLOG set access_log_level = INFO
set log_headers = True
[filter:Healthcheck]
use = egg:swift#healthcheck
[filter:catch_errors]
use = egg:swift#catch_errors
[filter:cache]
use = egg:swift#memcache set log_name = cache
[filter:authtoken] paste.filter_factory =
keystoneclient.middleware.auth_token:filter_factory auth_protocol = http
auth_host = 172.16.0.200 auth_port = 35357 auth_token = ADMIN service_protocol = http service_host = 172.16.0.200 service_port = 5000
admin_token = ADMIN admin_tenant_name = service admin_user = swift admin_password = openstack delay_auth_decision = 0
signing_dir = /tmp/keystone-signing-swift
[filter:keystone]
use = egg:swift#keystoneauth operator_roles = admin, swift operator.How it works: The contents of the proxy-server.conf file define how the OpenStack Object Storage proxy server is configured.
For our purposes, we will run our proxy on port 8080, as the user swift, and it will log to SYSLOG, using the log level of LOCAL1 (this allows us to filter against these messages).
We configure our swift proxy server health check behavior to handle caching (by use of Memcached) and TempAuth (local authentication meaning our proxy server will handle basic authentication).
The [filter:authtoken] and [filter:keystone] sections connect our OpenStack Object Storage proxy to our Controller virtual machine.
The endpoint_ URL option is useful when there is a requirement for a specific URL to be returned which differs from the default.
This is used in scenarios where the endpoint URL comes back on an address that is inaccessible on the network or you want to present this differently to the end-user to fit your network.
Benchmarking OpenStack Object Storage
Understanding the capabilities of your OpenStack Object Storage environment is crucial to determining limits for capacity planning and areas for performance tuning. OpenStack Storage provides a tool named swift-bench capabilities.
Getting started: Log in to the OpenStack Object storage Proxy server. To log on to our OpenStack Object Storage Proxy host that was created using Vagrant, issue the following command:
vagrant ssh swiftHow to achieve it…
Carry out the following to benchmark an OpenStack Object Storage cluster:
- First, create a configuration file named /etc/swift/swift-bench.conf, containing the following contents:
.PNG&w=16&q=75)
- With this in place, we can simply execute swift-bench, specifying our configuration file:
.PNG&w=16&q=75)
This produces the following output:
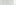
How it works…
OpenStack Object Storage comes with a benchmarking tool named swift-bench. This runs through a series of puts, gets, and deletions, calculating the throughput and reporting of any failures in our OpenStack Object Storage environment. The configuration file contains the following content:
.PNG&w=16&q=75)
The user-specified must be capable of performing the required operations in our environment, including the creation of containers.
| Related Article: Sandbox Network Server for VirtualBox |
Testing OpenStack Object Storage
The OpenStack Object Store is a facility that lets applications store and retrieves binary objects using the RESTful methods of the Swift API — this scales better than OS-level access to block storage and conventional file systems.
OpenStack Object Storage can be installed either on one server or multi-server for development or testing purposes, a multiple-server installation enables the higher availability and redundancy you want in a production distributed object storage system. Accounts, containers, and objects in the Object Storage system can be managed.
To know more details about its installation procedure, refer to Installing OpenStack Object Storage
We are now ready to test our installation of OpenStack Object Storage, and we can achieve this in a couple of ways—by using curl and using the swift command-line utility.
Getting ready: Ensure that you are logged in to your swift virtual machine. To accomplish this, run:
vagrant ssh swiftHow to achieve it: In this recipe, we will use the swift command to test connectivity with OpenStack Object Storage.
Using a swift command to test OpenStack Object Storage:
The swift client is the command-line interface (CLI) for the Object Storage service API and its extensions. The Swift engine is the default back-end for the Object Store, and is also used by Glance for storing images in HA deployments.
Rather than seeing the web service output, we can use the command-line tool swift (previously known as st) to ensure that we have a working setup. Note that the output matches the reply headers seen, when queried using curl.
swift -A https://172.16.0.200:5000/v2.0 -U service:swift -K swift -V 2.0 statYou should see the following output:
Account: AUTH_test
Containers: 0
Objects: 0
Bytes: 0
Accept-Ranges: bytesHow it works: OpenStack Object Storage is a web service, so we can use traditional command-line web clients to troubleshoot and verify our OpenStack Object Storage installation. This becomes very useful for debugging OpenStack Object Storage at this low level, just as you would debug any web service.
The swift command uses the credentials, we supplied while building the proxy-server.conf. In turn, this command authenticates us against the keystone and then lists the statistics of that container.
| Related Article: Configuring Ubuntu Cloud in OpenStack |
Terminating your instance
Instances are nothing but running virtual machines within the Openstack cloud. Cloud environments are designed to be dynamic and this implies that Cloud instances are being spun up and terminated as required. Terminating a cloud instance is easy to do, but equally, it is important to understand some basic concepts of cloud instances.
Cloud instances, such as the instance we have used are not persistent. This means that the data and work you do on that instance only exist for the time that it is running. A Cloud instance can be rebooted, but once it has been terminated, all data is lost.
Tip: To ensure no loss of data, an Open Stack Compute service named nova-volume provides persistent data store functionality that allows you to attach a volume to it that doesn’t get destroyed on termination but, allows you to attach it to running instances. A volume is like a USB drive attached to your instance.
How to do it: From our Ubuntu machine, list the running instances to identify the instance you want to terminate:
1. We first identify the instance that we want to terminate by issuing the following command from our client:
nova list
2. To terminate an instance, we can either specify the name of our instance or use the UUID:
nova delete myInstance
nova delete 6f41bb91-0f4f-41e5-90c3-7ee1f9c39e5aYou can re-run the nova list again to ensure your instance is terminated.
How it works: We simply identify the instance we wish to terminate by its UUID or by name while using the nova list. Once identified, we can specify this as the instance to terminate using nova delete. Once terminated, that instance, no longer exists—it has been destroyed. So if you had any data in there it will be deleted along with the instance.
Deleting volumes
At some point, you will no longer need the volumes you have created. To remove the volumes from the system permanently, so that they are no longer available, we simply pull out another tool from Nova Client, the volume-delete.
Getting started: Ensure that you are logged into that Ubuntu host where Nova Client is installed and have sourced in your OpenStack environment credentials.
How to achieve it: Be aware, this is a one-way deletion of data. It’s gone. Unless you’ve good backups, you will want to ensure you really want it to be gone.
To delete a volume using Nova Client, carry out the following steps:
- First, we list the volumes available to identify the volume we want to delete, as follows:
nova volume-list- We now simply use the volume ID to delete this from the system, as follows:
nova volume-delete - On deletion, the volume you have deleted will be printed on the screen.
How it works: Deleting images removes the LVM volume from use within our system. To do this, we simply specify the volume ID as a parameter to nova volume-delete (when using Nova Client), first ensuring that the volume is not in use.
Security groups in OpenStack
A security group is one of the greatest features of OpenStack. A common new-user issue with OpenStack is failing to set an appropriate security group when launching an instance. As a result, the user is unable to contact the instance on the network. Security groups are sets of IP filter rules that are applied to an instance’s networking. They are project-specific, and project members can edit the default rules for their group and add new rule sets. All projects have a “default” security group, which is applied to instances that have no other security group defined. Unless changed, this security group denies all incoming traffic.
Security groups are also known as firewalls for your instances, and they’re mandatory in our cloud environment. The firewall actually exists on our OpenStack Compute host that is running the instance and not as portable rules within the running instance. They allow us to protect our hosts by restricting or allowing access to specified service ports and also protect our instances from other users’ instances running on the same hosts. Security groups are the only way to separate a tenant’s instances from another user’s instance in another tenant when running under the Flat network modes and where VLAN or tunnel separation isn’t available.
Virtual firewalls are provided by the advanced neutron service known as firewall as a service- FWaas.
All projects have a default security group which is applied to any instance that has no other defined security group. Unless you change the default, this security group denies all incoming traffic and allows only outgoing traffic to your instance. The number of maximum rules per security group are controlled by security_group_rules.
Getting started
The nova command-line interface provides facilities for adding rules to security groups. To begin with, assure that you’re logged into a client that has access to the Nova Client tools. These packages can be installed using the following commands:
sudo apt-get update
sudo apt-get –y install python-novaclientAnd assure that you have set the following credentials :
export OS_TENANT_NAME=cookbook
export OS_USERNAME=admin
export OS_PASSWORD=openstack
export OS_AUTH_URL=https://172.16.0.200:5000/v2.0/
export OS_NO_CACHE=1How to achieve it: The following sections describe how to create and modify security groups in our OpenStack environment.
Creating security groups:
Recall that we have already created, a default security group that opened TCP port 22 from anywhere and allowed us to ping our instances. To open another port, we simply run our command again, assigning that port to a particular group.
For example, to open TCP port 80 and port 443 on our instances using Nova Client, a grouping that under a security group called webserver we can do the following:
nova secgroup-create webserver “Web Server Access” nova secgroup-add-rule webserver tcp 80 80 0.0.0.0/0 nova secgroup-add-rule webserver tcp 443 443 0.0.0.0/0The reason why we specified a new group, rather than assigning these to the default group, is that we might not want to open up our webserver to everyone, which would happen every time we spin up a new instance. Putting it into its own security group allows us to open up access to our instance to port 80 by simply specifying this security group when we launch an instance.
For example, we specify the –security_groups option w boot an instance:
nova boot myInstance
–image 0e2f43a8-e614-48ff-92bd-be0c68da19f4 –flavor 2
–key_name demo
–security_groups default,webserver
Removing a rule from a security groupTo remove a rule from a security group, we run the nova sec group -delete command. For example, suppose we want to remove the HTTPS rule from our webserver group, we do this using Nova Client, by running the following command:
nova secgroup-delete-rule webserver tcp 443 443 0.0.0.0/0
Deleting a security groupTo delete a security group, for example, a webserver, we run the following command:
nova secgroup-delete webserverHow it works: The creation of a security group is done in two steps as follows:
- The first is that we add a group using the nova sec group-create
- Following the creation of a security group, we can define rules in that group using the nova secgroup-add-rule. With this command, we can specify destination ports that we can open up on our instances and the networks that are allowed access.
Defining groups and rules using Nova ClientThe nova secgroup-create command has the following syntax:
nova secgroup-create group_name “description”The nova secgroup-add-rule command has the following basic syntax:
nova secgroup-add-rule group_name protocol port_from port_to sourceRemoving rules from a security group is done using the nova secgroup-delete-rule command and is analogous to the nova secgroup-add-rule command. Removing a security group altogether is done using the nova secgroup-delete command is analogous to the nova secgroup-create command.
Chef Server
Now that we have installed both CHEF SERVER and its Knife utility, we need to download the Chef cookbooks to support the remainder of our installation.
Getting started: Log into the Chef Server
vagrant ssh chefHow to achieve it: On the Chef Server, execute the following commands to download, configure, and install the cookbooks and roles to support the rest of our installation efforts. To perform this, execute the following commands:
# Create chef Repo
sudo apt-get install –y git
sudo git clone git://github.com/opscode/chef-repo.git /root/cookbooks
# Download the DHCP Cookbook
sudo knife cookbook site install dhcp sudo knife data bag create dhcp_networks sudo mkdir -p /root/databags/dhcp_networks
sudo cat > /root/databags/dhcp_networks/razor_dhcp.json <<eof {="" "id":="" "172-16-0-0_24="" ″="" ,="" "routers":="" [="" "172.16.0.2"="" ],="" "address":="" "172.16.0.0="" "netmask":="" "255.255.255.0="" "broadcast":="" "172.16.0.255="" "range":="" "172.16.0.50="" 172.16.0.59="" "options":="" "next-server="" 172.16.0.101"="" ]="" }="" eof="" sudo="" knife="" data="" bag="" from="" file="" dhcp_networks="" root="" databags="" razor_dhcp.json="" #="" download="" the="" puppetlabs="" razor="" cookbooks="" cookbook="" site="" install="" razor_ip="172.16.0.101" sed="" -i="" "s="" node['ipaddress']="" $razor_ip="" g"="" attributes="" default.rb="" upload="" -o="" --all="" rackspace="" openstack="" git="" clone="" https:="" github.com="" rcbops="" chef-cookbooks.git="" cd="" chef-cookbooks="" checkout="" v4.0.0="" submodule="" init="" sync="" update="" -a="" role="" roles="" *rb="" How it works: The first thing we need to do, is creating a Chef cookbook repo. This provides the git structure that lets the Chef Server version our cookbooks. Next we have to download the DHCP cookbook and create a Chef “Databag”, or set of configuration values, to contain the configuration of our DHCP Scope, such as IP address range and critically, the next server. After that we download both the Razor and OpenStack Cookbooks. Finally, we add the IP address of the Razor Server to its configuration and then upload all of our cookbooks and roles.
| Related Article: OpenStack Interview Questions |
Node installation
Once you have created and enabled the policy, nodes will begin to install. This may or may not take a long time depending on the size of your system. Razor provides a basic set of monitoring commands so you can tell when nodes have finished installing.
Getting started: Log into the razor node and sudo to root.
vagrant ssh razor sudo su -How to achieve it: To monitor the install progress of a node, execute the following command:
watch razor active_model logviewHow it works: The razor active_model logview command will report on the activity of nodes as they progress through the various stages of an installation. You will know your first node has finished when you see “Broker Success”.
Using Chef to install OpenStack
At this stage, we have a node with Ubuntu 12.04 installed by RAZOR. Additionally, that node has 11.4.4 installed. At this stage, we need to tell Chef that this node will be an “all in one”, for example, that it will run Keystone, Nova Compute, Horizon, Glance, and a number of other services.
Getting ready: To install OpenStack onto our node, log into the Chef Server as root:
-
vagrant ssh chef sudo su -
How to do it: To tell Chef that our node is an all in one, execute the following command:
EDITOR=vim knife node edit node1.cook.bookChange the following line:
"chef_environment": "cookbook",Add these lines:
"run_list": [ "role[allinone]"]Then exit vim with ‘:wq’.
Next, log into the node and execute chef-client.
How it works: Once logged into the Chef Server, we modified the definition of the node to place it into our OpenStack environment. Additionally, we assigned the node the “all in one” role, which contains all of the other roles and services necessary to build a self-contained OpenStack environment. Finally, we execute CHEF-CLIENT, which pushes everything into motion.
Automatically assigning and modifying fixed networks of tenants
OpenStack Networking provides a rich tenant-facing API for defining network connectivity and addressing in the cloud. The OpenStack Networking project gives operators the ability to leverage different networking technologies to power their cloud networking. It is a virtual network service that provides a powerful API to define the network connectivity and addressing used by devices from other services, such as OpenStack Compute. It has a rich API that consists of the following components.
When using VlanManager to separate tenants, we can manually assign VLANs and network ranges to them by creating a secure multi-tenant environment. We can also have OpenStack to manage this association for us, so that when we create a project it automatically gets assigned to these details.
Getting started: To begin with, ensure you’re logged in to the Controller server (our OpenStack VirtualBox Virtual Machine, controller, created in, Starting Openstack Compute). If this was created using Vagrant, you can log into this box using the following command:
vagrant ssh controllerHow to achieve it: Carry out the following steps to configure networking in OpenStack to automatically assign new tenants’ individual VLANs and private (fixed) IP ranges:
In the file /etc/nova/nova.conf, ensure there is a flag called vlan_start with a VLAN ID, for example:
vlan_start=100- We can now create a range of networks, each with 256 addresses available, by issuing the following command:
.PNG&w=16&q=75)
- This creates 10 networks, with 256 IP addresses starting from 0.0.0/24 to 10.0.9.0/24 and starting from VLAN ID 100 to VLAN ID 110.
Tip: You can specify an alternative VLAN start ID on the command line by adding in the —vlan=id option, where id is a number.
How it works… By specifying the —num_networks option and specifying the —network_size option (the number of IPs in each of the created networks), we can tell our OpenStack environment to create multiple networks within the range specified by — fixed_range_v4. When projects are created now, rather than having to manually associate an address range with a tenant, they are automatically assigned a VLAN, starting from the –vlan_start ID, as specified in /etc/nova/nova.conf.
| Related Article: OpenStack Block Storage |
Modifying a tenant’s fixed network
To ensure that our OpenStack environment is able to separate traffic from one tenant to another, we assign different fixed ranges to each. When a fixed network is no longer required, or we want to assign a particular tenant to a specific network, we can use the nova-manage command to modify these details.
Getting ready: To begin with, ensure you’re logged in to the OpenStack API server as well as to a client that can access the keystone environment.
How to do it: To assign a particular network to a tenant, carry out the following steps:
On a client that has access to the keystone command, run the following commands to list the projects available:
.PNG&w=16&q=75)
An example of running the previous commands is as follows:
.png&w=16&q=75)
- To view the list of networks and ranges available, issue the following command on an OpenStack API host:
-
sudo nova-manage network list
An example of running the previous commands is as follows:

- The output shown lists network ranges and their associated project IDs. From this, we can see that we have 10.0.3.0/24 not assigned to a project (where it says None under the project column). To assign this network range to the development tenant, we issue the following commands:
.PNG&w=16&q=75)
- When we view the output now for that network range, we will have this project ID assigned to it and any instances spawned under this tenant will be assigned an address in this range.
How it works: When configuring tenants in our OpenStack environment, it is recommended (although not a requirement) to have their own private (fixed) range assigned to them. This allows for those instances in each particular tenant to be kept separated through their different ranges along with appropriately set security group rules.
| Explore OpenStack Sample Resumes! Download & Edit, Get Noticed by Top Employers! |
The syntax to modify a network is as follows:
.PNG&w=16&q=75)
 On-Job Support Service
On-Job Support Service
Online Work Support for your on-job roles.

Our work-support plans provide precise options as per your project tasks. Whether you are a newbie or an experienced professional seeking assistance in completing project tasks, we are here with the following plans to meet your custom needs:
- Pay Per Hour
- Pay Per Week
- Monthly
| Name | Dates | |
|---|---|---|
| OpenStack Training | Jul 25 to Aug 09 | View Details |
| OpenStack Training | Jul 28 to Aug 12 | View Details |
| OpenStack Training | Aug 01 to Aug 16 | View Details |
| OpenStack Training | Aug 04 to Aug 19 | View Details |

Ravindra Savaram is a Technical Lead at Mindmajix.com. His passion lies in writing articles on the most popular IT platforms including Machine learning, DevOps, Data Science, Artificial Intelligence, RPA, Deep Learning, and so on. You can stay up to date on all these technologies by following him on LinkedIn and Twitter.














