
- Advanced OpenStack Tutorial
- Configuring Account Server - Openstack
- Installing OpenStack Dashboard
- OpenStack Object Storage Tutorial
- OpenStack Interview Questions
- Attaching volumes to an instance – OpenStack
- Automating OpenStack Installations of Opscode Chef Server and Chef Client - OPENSTACK
- Automatically assigning and modifying fixed networks of tenants – OpenStack
- Checking OpenStack Services
- Configuring Object Server - OpenStack
- Configuring OpenStack Compute for Cinder volume - Openstack
- Creating containers - Openstack
- Creating and Deleting a Neutron network – OpenStack
- Creating an external Neutron network – OpenStack
- Creating and Managing Keypairs - OpenStack
- Creating an OpenStack Object Storage sandbox environment
- Creating a sandbox Compute server with VirtualBox and Vagrant - OpenStack
- Creating a sandbox Network server for Neutron with VirtualBox and Vagrant – OpenStack
- How to Create the Service Tenant and Service Users - Openstack
- OpenStack – Detaching volumes from an instance
- Downloading objects In OpenStack
- Configuring OpenStack Keystone user & Role Management - OpenStack
- How to Configure Ubuntu Cloud Archive in OpenStack
- How to Create Sandbox Environment for the OpenStack
- Create Tenant Users and Roles in OpenStack
- Install and Configure Compute Node – OpenStack
- How to Install Compute Controller Services – OpenStack
- Installing and configuring OVS and API server for Neutron - OpenStack
- Installing and setting up Pacemaker and Corosync - Highly Available OpenStack
- Managing Images with OpenStack Image Service
- Manually associating and dissociating floating IPs of instances – OpenStack
- Monitoring Compute services with Munin – OpenStack
- Monitoring OpenStack services with Nagios
- OpenStack Networking
- Registering a remotely stored image – OpenStack Cloud
- OpenStack – Removing nodes from a cluster
- Setting up a Chef Environment for OpenStack
- Troubleshooting OpenStack
- Troubleshooting OpenStack Authentication and Networking
- Troubleshooting OpenStack Compute Services
- Uploading Large Objects In OpenStack
- Using OpenStack Dashboard to Launch and Terminate Instances
- Using OpenStack Object Storage
- Starting OpenStack Block Storage
- Stopping and starting Nova services - Openstack
- Why OpenStack is Popular?
In this OpenStack tutorial, we will learn completely about the basic needs and necessities of OpenStack along with the tutorial to install and get started with OpenStack.
What is OpenStack?
OpenStack is an open-source platform, which offers powerful virtual servers and required services for cloud computing. It is mostly deployed as Infrastructure-as-a-service (IaaS), which aims to provide hardware tools and components for processing, storage, and networking resources throughout a data center.
OpenStack can be understood as a software platform that uses pooled virtual resources to build and manage clouds, both public and private ones.
By default, OpenStack offers a couple of cloud-related services like networking, storage, image services, identity, etc., and can be clubbed with a few more to get a customized cloud optimization to support the cloud-native apps.
| If you would like to build your career with an OpenStack certified professional, enroll in our “OpenStack Online Training” Course. This course will help you to achieve excellence in this domain. |
Why OpenStack?
First of all, let's address the elephant in the room.
Why should we adopt OpenStack? How does it fit our requirements?
Here are a few reasons which answer our questions!
- OpenStack is most importantly an open-source environment that gives complete control over cloud computation. Most of the platforms available in the market, which helps in virtualization and cloud computation, are all expensive and licensed.
- OpenStack can be installed free of cost and can be customized with the required services to suit the need. Hence many corporations own their own version of OpenStack.
- Moreover, it can be scaled to any extent possible, making the jobs of the server admins easier.
- The OpenStack API is made robust and more flexible with improvements contributed by many developers across the world. This also ensures good community support.
- Many big-shot companies in the IT world like Huawei, Intel, Red Hat have adopted OpenStack on their cloud management.
Who is OpenStack for?
Well, most of us are unknowingly users of OpenStack. Many cloud platforms have integrated OpenStack in their cloud toolkit by default. The OpenStack backend is ever-growing with many companies joining in every day
| Related Article: OpenStack Interview Questions for Experienced |
Terminologies in OpenStack
The important terminologies that are repeatedly used in the rest of the module are discussed below in brief. These terminologies are important components of OpenStack architecture.
By default, OpenStack has many different moving parts. Besides, because of the open-source nature of OpenStack, many developers can contribute to the addition of new components for the personalized application. But to clarify, the OpenStack community has declared around 9 components to be an integral part of OpenStack. They are:
- Nova: This is the fundamental computing engine of OpenStack. It manages a large number of Virtual machines and other instances, which handle computing tasks.
- Swift: Swift is the storage system of OpenStack. It is used to store objects and files. Instead of referring to the file and objects through the path, developers can instead refer to them through a unique identifier, which points to a file or piece of information and thereby allow OpenStack to manage where to store the files. This reduces the effort of the developers to understand and worry about storage distribution. This also ensures that the data is being backed up, if in case of any failure of the machine or network loss.
- Cinder: Cinder is known as the block storage component of OpenStack. This functions in a way, analogous to the traditional ways of locating and accessing specific locations on a disk or a drive.
- Neutron: As the name suggests, Neutron is the component that enables networking in OpenStack. It ensures that each component within the OpenStack is well connected with other components, to establish good communication amongst them.
- Horizon: Horizon is the dashboard of the OpenStack system. It provides all the possibilities for the system administrators to access and manage the cloud. This is the first component that everyone “sees” upon starting to use the OpenStack. Developers will be able to access and deal with all the components through the Application Programming Interface (API) also, while Horizon is the only place through which the system admins will be interacting with the OpenStack architecture.
- Keystone: Keystone is the component that provides identity services for all users. It basically contains a central list of all the users of the OpenStack cloud, mapped to the accessible services of the OpenStack. It provides a way for multiple accesses by allowing the developers to map their existing user access methods to the Keystone.
- Glance: Glance provides the image services in OpenStack, where images refer to the virtual copies of the hard disks. Glance helps in allocating these images to be used as templates while assigning new virtual machine instances.
- Ceilometer: Ceilometer provides telemetry services to its users. It performs a close regulation of each user's cloud components' usage and provides a bill for the services used. Think of Ceilometer as a component to meter the usage and report the same to individual users.
- Heat: Heat is that component of the OpenStack that allows developers to store the requirements of a cloud application in a file so that all the resources necessary for a program are available at hand. It thus provides an infrastructure to manage a cloud application. It is an orchestration instrument of OpenStack.

Getting started with OpenStack
OpenStack, being an open-source engine, there are many ways in which you gain a trial experience using OpenStack. Two main ways through which you can experience the OpenStack environment easily are given below:
- Sign up for a public cloud
Try the OpenStack Public cloud infrastructure available across the world by participating in public cloud programs from OpenStack. Use the link to have a glimpse of the OpenStack Public Cloud Passport Program.
- Local Dev Instance
OpenStack can be explored on the Local Dev with the help of DevStack. Devstack intends to provide tools for the installation of the core Openstack. Devstack can be installed and run on the virtual machine, besides on the normal OS. This is suited well for the users, who are willing to explore the features of the dashboard of what the admin cloud stack looks like. You can get more information On DevStack
You can install Devstack through the Git Source
How to progress with OpenStack?
- Since OpenStack is the free source available on the internet, open to all developers, finding an authentic link to look for updates becomes tedious. Considering this, Opensource.com is working incessantly to provide the latest updates on OpenStack, which gives the required guidelines to the developments in OpenStack.
- Besides this, there are many other sources available, which keep the recent updates on OpenStack posted. Mindmajix is one of the best sources for it. We will know more about this later in this module.
OpenStack Architecture
The basic components that make up the architecture of OpenStack are:
Compute (Nova)
- Compute is one of the most important and mandatory components of OpenStack. It is basically a virtualization hypervisor. In a cloud computing environment, it acts as a controller, which manages all the resources in a virtual environment. It is also used to manage high-performance bare metal configurations.
- It is coded in Python and has utilized many pre-defined libraries to deliver robust functioning. The hypervisor technologies that might be used are Xen, KVM, and VMware and this selection depend on the version of OpenStack used. SQL is used for database access.
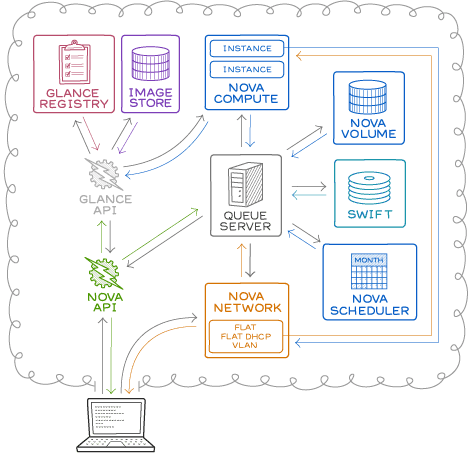
The above picture dissects the computer and the explanation of the picture is given below.
| Related Article: OpenStack Services List |
Functionality
- The nova-API handles the requests and responses from and to the end-user.
- The nova-compute creates and destroys the instances as and when a request is made.
- Nova-scheduler schedules the tasks to the nova-compute
- The glace registry stores the details of the image along with its metadata.
- The Image store stores the images predefined by the admin/user.
- The nova network ensures network connectivity and routing.
Networking (Neuron)
This is responsible for establishing a neuron structure between the components for better connectivity. It manages all the networking-related functionalities of the architecture as a whole. Starting from assigning and managing the IP addresses of the nodes to managing and implementing routing, it constitutes all.
Image
The instances of the virtual machines or the disk image are stored as images in the image storage Glance.
Object Storage (Swift)
This is the mountable storage unit of the architecture. It helps in data replication across the data center. The files and objects can be copied to multiple units with the help of this unit. The object storage units are replicated with every new server addition. It also stores the replicate content from all the active nodes and makes it available to the new clusters, ensuring a backup in case of any hardware failure or server loss.
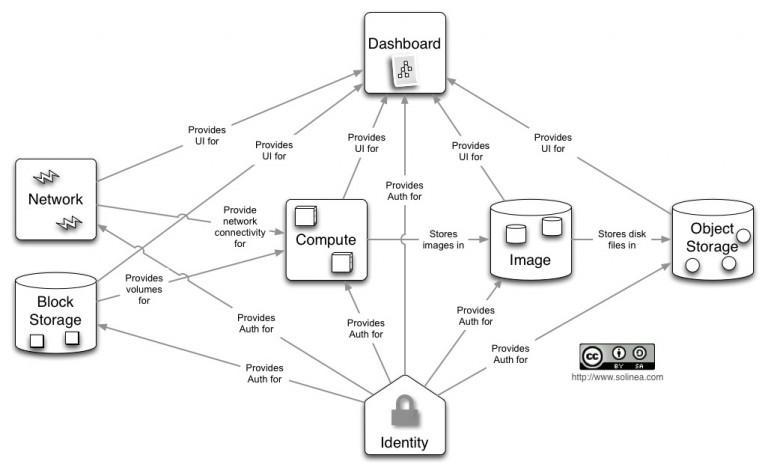
Block Storage (Cinder)
Block Storage provides persistent level storage facilities for cloud-oriented computing devices. It helps in the creation, addition, and removal of the new block devices in the server. It provides complete integration with the OpenStack, reducing the use of extraneous hardware components. It can be accessed and instructed using CLI or web-based services. Linux-based systems can go with Cloudbyte, EMC, Coraid, SAN Storage, etc.
Logical Architecture
Understanding the logical architecture, besides the basic structural architecture, is essential to design, deploy and configure OpenStack.
OpenStack is made of all distinct Services. Each of these services is internally configured to have one API service. Each API service is always looking for API requests and these requests when obtained are preprocessed and passed on to the other parts of the service.
The diagram below has shown a pictorial representation of the Logical Architecture in OpenStack.
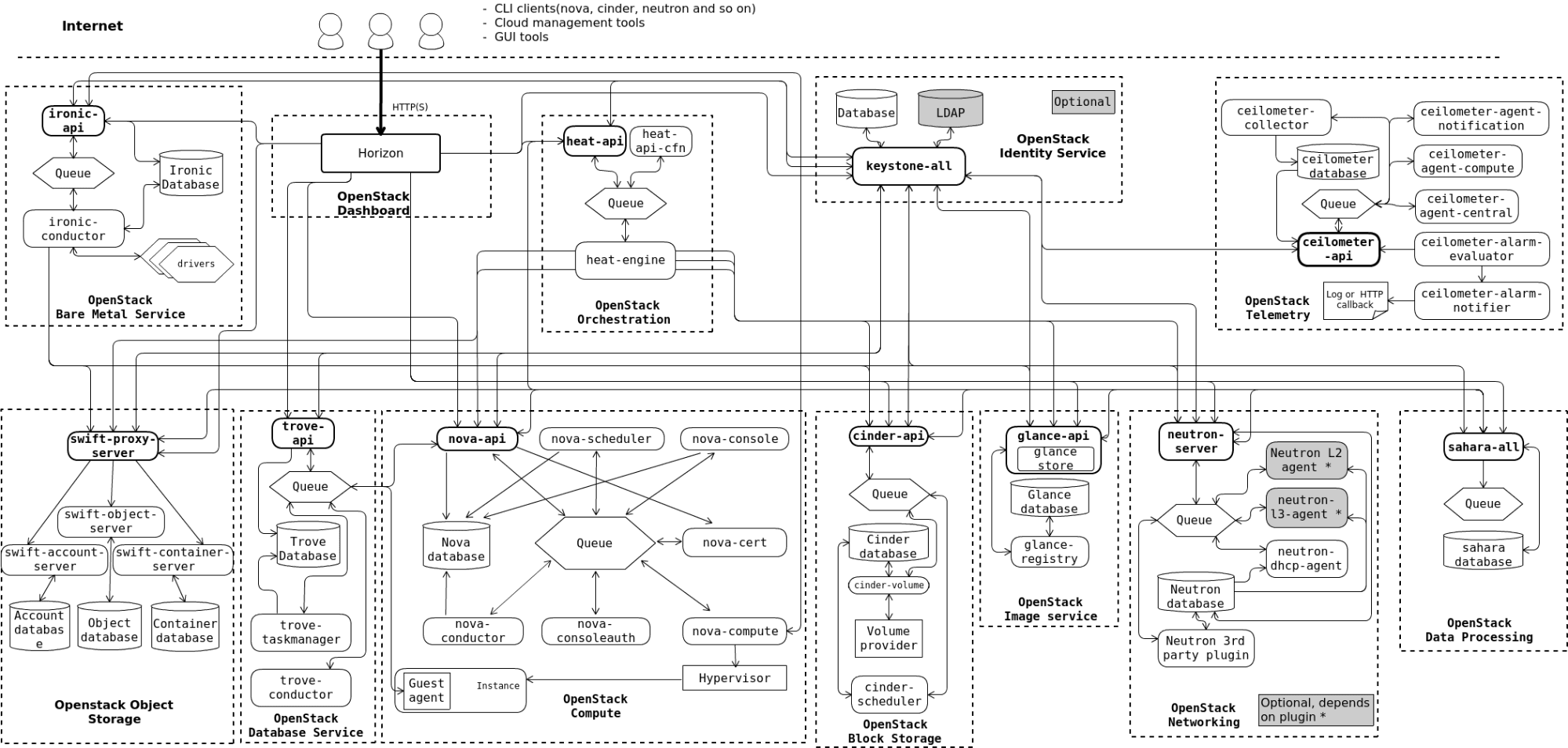
- All services are authenticated through the one Identity Service (Keystone). Individual services generally interact with each other through the public APIs, except for few, which require admin privileges.
- For the inter-process communication within a service, an AMQP message broker is used. The state of service will be stored and updated in the database.
- When you are configuring your OpenStack cloud, you can choose the message broker and the database solution from a list of products/solutions available from the market, such as RabbitMQ, MySQL, MariaDB, and SQLite.
- OpenStack can be accessed on web User Interface through CLI or through API calls using tools like curl or other plug-ins. Ultimately, all these REST API calls will issue access to the OpenStack services.
Who is OpenStack for? (Extended)
- The idea of OpenStack can be better appreciated when we treat it as an environment than as a mere product.
- OpenStack is a generic infrastructure that is built to handle many possibilities on the cloud, based on the need. The companies are free to plug into and make necessary changes to shape the environment to their need.
- It is also very efficient to handle both public and private clouds with a common infrastructure, cutting down the dependency on two different environments to handle private and public clouds.
For an end-user, the advantage of using OpenStack lies in the following points
- The average cost and complexity of supporting a generic infrastructure are low by definition than supporting a large diversity of infrastructures that don't share a common ground.
- As many big shot companies and independent developers are constantly contributing to make OpenStack a better environment, it is more reliable to switch to, than those of independent vendors.
- When talking about a company, managing both private and public clouds separately costs heavily in terms of the labor, infrastructure investment, customizing capacity of the specific infrastructure along the added risk. OpenStack, on the other hand, has grown to support private and public clouds more efficiently than any other competitor in the market. Moreover, it is always easier to manage one single environment than two different ones.
Owing to all these advantages of OpenStack, which count in the longer run, many companies have adopted it and have integrated into their back-end infrastructure. Some of the companies to mention are, AT&T, Ericsson, Huawei, and Intel.
| Related Article: OpenStack Troubleshooting |
Installation Guide
- OpenStack, as an open-source cloud computing platform, supports all cloud environments. It is contributed by many developers across the world, leading to simple implementation with a rich set of features.
- There are many versions of OpenStack available. Each of them differs in their installation and configuration by few steps.
- This section deals with an informative tutorial to follow the deployment instructions of OpenStack.
- The instruction set is based on example architecture with minimalistic services. The following description is the basic setup required for all the versions of OpenStack installations.
Example Architecture
- Example Architecture requires 2 nodes (min) to launch a basic virtual machine or an instance.
- The example architecture considered here has a minimum configuration to give an idea of proof of concept of OpenStack, rather than going for a production environment.
Hardware requirements
Below are the components required for the example architecture considered.
Controller
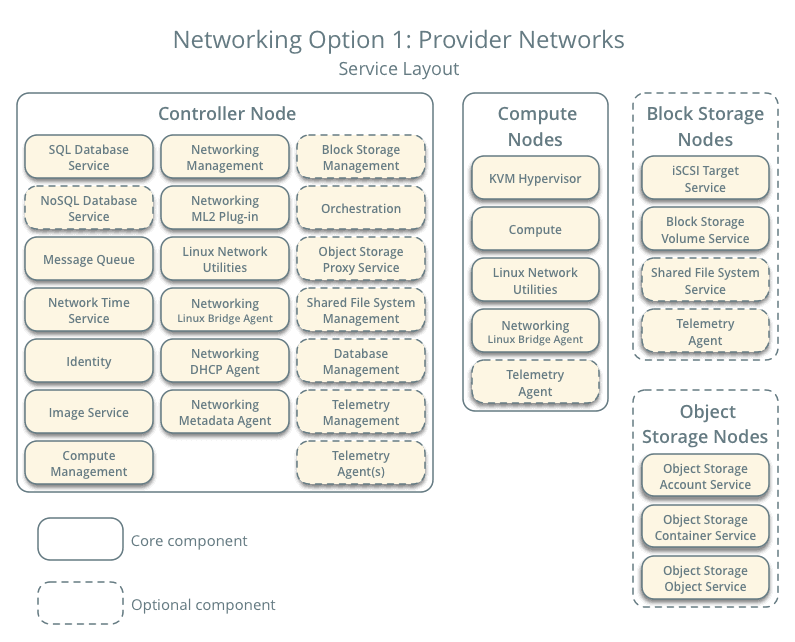
The controller node mainly runs the following functionalities:
- Image Service
- Identity Service
- Management portions of :
- Compute
- Networking
- Various networking agents
- Dashboard
- Supporting services like SQL Database, message queue, NTP. etc
The controller node requires a minimum of two network interfaces.
The below picture depicts the hardware requirements for the example architecture.
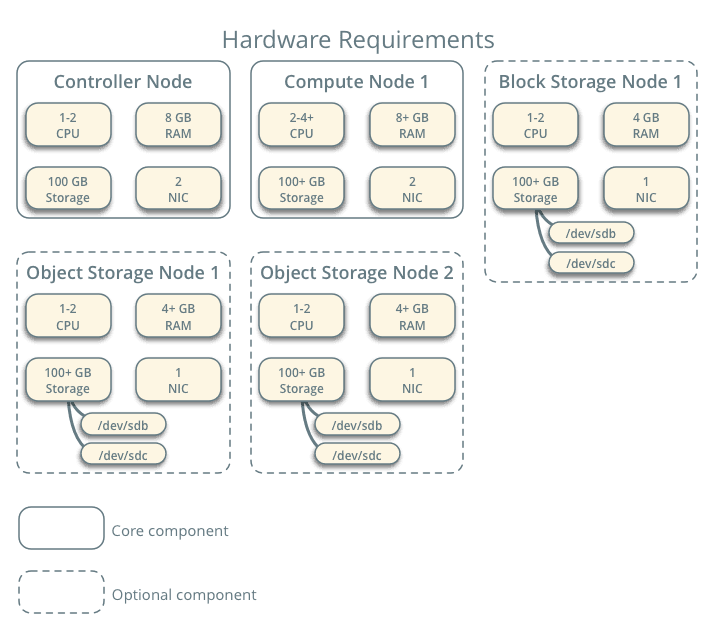
Compute
Compute node basically runs the hypervisor portion. By default, it uses the KVM hypervisor. It also runs the Networking service agent that connects the instances to the virtual networks and also provides security through firewalling via security groups.
More than one compute node can be deployed. A minimum of 2 network interfaces is required for each Compute Node.
Block Storage
- The optional block storage requires a minimum of one network interface. It contains the disks for the Block Storage and the Shared file system services.
- The production environment should have a separate storage network to increase efficiency. However, for the sake of simplicity, a management network is used between the Compute Nodes and the Block Storage.
Object Storage
- Like block storage, object storage is also optional and contains disks that are used for storing accounts, containers, and objects.
- This service demands 2 nodes. Each node demands 2 network interfaces. More than one object storage service can be deployed in a system.
- Networking
There are 2 options available for networking. You can choose either of them. They are:
Provider Networks
The features of Provider Networking are submitted below:
- It deploys the simplest of the OpenStack Networking possible with layer 2 (switching/bridging) services and VLAN segmentation networks.
- It bridges the virtual network with the physical network infrastructure to enable layer-3 routing services.
- It depends on the physical network infrastructure for the layer-3 routing services.
- The Instances are supplied with the IP address information through a DHCP service.
Warning
This networking method lacks support for the private networks, layer-3 (routing) services, and advanced services such as LBaaS and FWaaS. Consider going for the next option, if you are considering the options said.
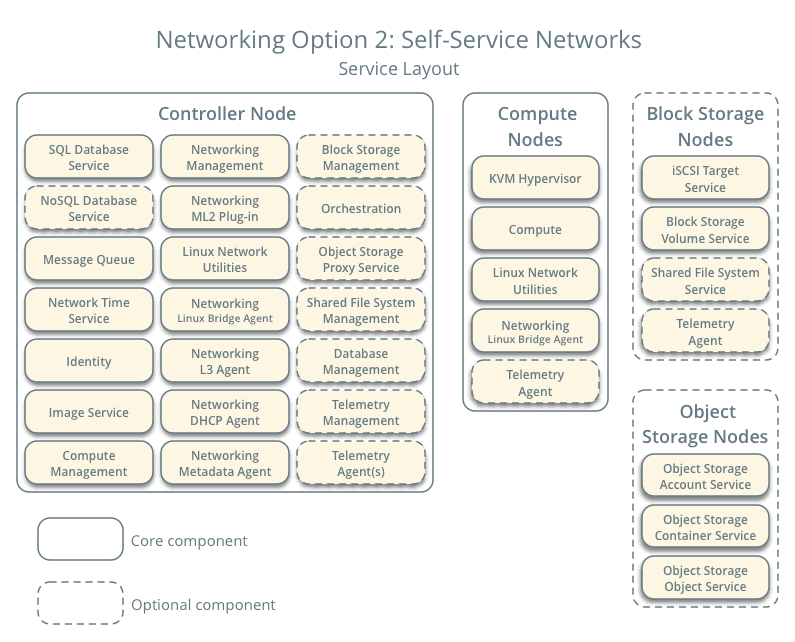
Self-Service Networks
This method of networking just augments the Provider Networking with the layer-3 routing services, which enable the self-service networks (private networks). They basically use overlay segmentation methods such as VXLAN to include the services for private networks. It routes the virtual network to the physical network using NAT. It also draws a foundation for advanced services like LBaaS and FWaaS.
Environment
- This segment deals with configuring the controller node and a compute node within the example architecture.
- Many environments include the Image service, Identity, Compute, at least one networking service, and the Dashboard, the Object Storage service is capable of working independently. However, if you want to just try out the Object Storage Service, ensure that the appropriate nodes are configured.
- In order to configure nodes, use the account in admin privileges. To do this, either run commands as the "root" user or configure "sudo" utilities.
- Before heading further, make sure that the hardware requirements are met.
The following are the requirements to make a proof of concept model for the OpenStack deployment with core services and CirrOS instances.
- Controller Node: 1 processor, 4 GB memory, and 5 GB storage
- Compute Node: 1 processor, 2 GB memory, and 10 GB storage
- With the increase in the services added to the basic architecture, the hardware requirements also scale up to get the best performance.
- To improvise efficiency and reduce cluttering, minimal installation is recommended on your Linux distribution.
- On each node, ensure to install a 64-bit version of your distribution.
- For most of the applications, a single partition on the disk is sufficient; however, for extra additions like optional block storage, an additional partition might be demanded. Try considering “Logical Volume Manager (LVM)" for such cases.
Many beginners go for building each host as a Virtual Machine, for initial testing and trial sessions, mainly for two reasons:
- Only one physical server is sufficient to handle multiple nodes with any number of network interfaces.
- Periodic "snapshot" (history) will be marked during the installation process. Hence, you can always "rollback" to a working event, in case of any hiccups.
- However, the performance of hosts will suffer through VMs, particularly if, the hypervisor/processor is incapable of handling the nested VMs.
Note: If you are going for VMs, make sure that the hypervisor provides a way to disable the MAC address filtering on the interface of the provider network.
Security
While installing the OpenStack capabilities onto your system, it is important to configure for security during the process, so that all the computation on the cloud will be handled securely, later. There are many security options available for the user, like:
- password
- Policy
Encryption
- Additionally, the other services include the database server and message broker password security.
- The link given below takes you through the detailed steps of installation, which involve setting up important parameters for the environment and configuring the required services. The last part deals with the launching of an instance.
- Use the next button (arrow buttons) to proceed to the further steps in installation and set-up in the following link: Installation Guide
How does OpenStack work?
- Cloud mainly provides computing for the end-users in a remote environment, where they deploy the software programs and run them, instead of a physical environment that has more limitations in terms of capabilities and storage. OpenStack is considered as an Infrastructure as a Service (IaaS), where it helps the users to easily add a new instance on which the cloud components can run. Basically, the infrastructure aims to provide a "platform" on which the developer can create and deploy software applications.
- After understanding the layers of architecture, it is important to reconnect the dots and understand how OpenStack works!
- Horizon is the face of the application environment. Everything a user needs to do should start with the Dashboard, which is called Horizon. It is a simple graphical user interface that has divided modules that perform a specific action.
- As we know, every action on OpenStack works as a service API call. Every API call is first authenticated by Keystone for permission availability. So, before you access the dashboard of OpenStack, you will have to authenticate yourself as a registered user, through your login credentials.
- Once you successfully log in, you will see your dashboard with options to create new image instances, cinder, volumes, and configure network details.
- The image instances are basically the instances of your virtual machines or environments on which you will configure the cloud. They can be Ubuntu, CirrOS, RedHat, OpenSUSE, etc.
- You can choose an instance and enter the details like the network configuration, etc. to create a new one. This instance can be connected to a new cinder instance or volumes to include any extra services. Remember the creation of a new image instance is also an API call.
- Once an image is created, you can configure it and manage it through the CLI and add whatever data you want to add. You may even want to perform many extended operations on the instance created.
- Any data computation performed on the cloud instance created will be stored along with its metadata in image architecture and other storage components and thus in the associated databases.
- You can even configure an instance to store the snapshots, where the state of the disk at any moment will be stored for future reference. This provision is available in the dashboard.
How to find out which version of OpenStack I am using?
So, this is quite a common question, as many will not be able to find out the version of the OpenStack they are using. Here is a quick workaround for that:
- Make an SSH request to your hosts
- Run the following command
Command:
openstack --versionSimilarly, you can query to get the versions of other components of your OpenStack too.
Commands:
nova-manage --version
cinder-manage --version
glance-manage –versionOpenStack vs. AWS
Openstack is known as a platform to provide cloud computing services. Amazon Web Services (AWS) is also known as a reliable and scalable platform for inexpensive cloud computing services. Both of these platforms are widely used by many shark companies for the backend configuration. Considering the large-scale implementation, it is important for us to know, which of the two solutions fit our needs the best, before deciding to adopt one. The distinct differences between the two are given below. Go through each, to bank on one for the deployment.
| Topic of comparison | OpenStack | AWS |
|
Compute
|
Whatever OS cloud admins host on the OpenStack. Glance manages images. Admins upload the images and generate a catalog for the users. However, users can upload their own images too. |
AMIs provided by AWS marketplace AMI(Amazon Machine Image) manages the images. An online marketplace with predefined images is offered. However, the users can upload their own images too. |
|
Networking Private IP Public IP Load Balance VM traffic |
Automatically an IP address will be assigned to every virtual instance. It is managed by DHCP. A floating IP is a public IP and you can dynamically add it to a running virtual instance. The OpenStack LBaaS manages the load balance traffic. |
AWS allocates every new instance, a private IP address using DHCP. The Public IP is auto mapped to private IP address by AWS. The Elastic Load Balance automatically distributes the incoming traffic from the services to the EC2 instances. |
|
Identity Authentication | Managed by Keystone | Managed by IAM Identity and Access Management |
|
Storage Object Storage Block Storage |
Managed by Swift Managed by Cinder |
Managed by S3 bucket – Simple Storage Service Managed by EBS - Elastic Block Storage |
|
Database Relational Database Non-Relational Database |
Uses MySQL, PostgreSQL Uses Cassandra, Couchbase or MongoDB |
Users use an instance of MySQL or Oracle 11g Uses Amazon SimpleDB |
| Big data and Parallel Processing | Sahara | EMR(Elastic MapReduce) |
How Can I learn OpenStack?
- To learn the OpenStack environment completely, right from the basics to the installation and advancement, there are seldom any online tutorials or course materials available. Many of the sites either give information on selective topics or are very vague & hard to follow.
- As an answer to the need of the hour, Mindmajix OpenStack training has covered an in-detail course material on OpenStack. The course content is covered from basics, explained with visual aids and simple language, for better understanding and implementation.
Job Opportunities for OpenStack
- The opportunities for OpenStack developers and technical consultants are on a boom. The available roles in the market on OpenStack extend from an OpenStack engineer, developer, technical consultant, VMware Engineer with expertise in OpenStack, OpenStack neutron architect, etc. to Python developer with automation.
- Any expertise in OpenStack is welcomed by the IT industry, at present.
- The average salary for an OpenStack developer ranges from $63000-$125000 in the US.
Future Scope
- The IT sector is seeing a spectrum shift to complete cloud infrastructure for a decade now. The endless possibilities of cloud computing which encompass the unlimited storage capacity to less cost of infrastructure make it the first choice when it comes to handling big data.
- A generic environment that can be customized easily to meet specific demands makes OpenStack the favorite choice for many companies across the industry. The open-source nature and incredible community support extend its applications. The future calls for such a robust environment and the OpenStack are going to continue its legacy for being the free infrastructure with some great features suited for the long run.
OpenStack is one of the best cloud computing environments in the market. The databases of many top-notch companies have integrated the OpenStack in their back-end. The ease of linear scalability and open-source nature has attracted many customers and technology enthusiasts to come forward and contribute to the development. This has made the OpenStack, only better with the years. Seeing all the advantages and endless scalable features, OpenStack can be considered for cloud computation as it proves to be an affordable solution for the long run
 On-Job Support Service
On-Job Support Service
Online Work Support for your on-job roles.

Our work-support plans provide precise options as per your project tasks. Whether you are a newbie or an experienced professional seeking assistance in completing project tasks, we are here with the following plans to meet your custom needs:
- Pay Per Hour
- Pay Per Week
- Monthly
| Name | Dates | |
|---|---|---|
| OpenStack Training | Aug 01 to Aug 16 | View Details |
| OpenStack Training | Aug 04 to Aug 19 | View Details |
| OpenStack Training | Aug 08 to Aug 23 | View Details |
| OpenStack Training | Aug 11 to Aug 26 | View Details |

Ravindra Savaram is a Technical Lead at Mindmajix.com. His passion lies in writing articles on the most popular IT platforms including Machine learning, DevOps, Data Science, Artificial Intelligence, RPA, Deep Learning, and so on. You can stay up to date on all these technologies by following him on LinkedIn and Twitter.














