
- Snowflake Interview Questions and Answers
- Snowflake Tutorial
- Snowflake Architecture
- What is Snowflake Data Warehouse
- Star schema and Snowflake schema in QlikView
- Snowflake vs Redshift - Which is the Best Data Warehousing Tool
- Snowflake vs BigQuery
- Snowflake Time Travel - A Detailed Guide
- What is a Snowflake Table & Types of Tables
- Snowflake vs Databricks
- Snowflake vs Azure
- Snowflake Vs Hadoop: What's the Difference?
- How to Insert Data in Snowflake
- Snowflake Connectors
- Snowflake Documentation - A Complete Guide
- How to Update Data in Snowflake?
- How to Delete Data in Snowflake
- How to Add a Default Value to a Column in Snowflake
- How to Add a Column in Snowflake
- How to Add a NOT NULL Constraint in Snowflake
- How to Alter a Sequence in Snowflake
- How to Create a Table in Snowflake
- How to Create a View in Snowflake
- How to create an Index in Snowflake
- How to Drop a Column in Snowflake
- How to Drop a Table in Snowflake
- How to Drop a View in Snowflake?
- How to Drop the Index in Snowflake
- How to Duplicate a Table in Snowflake
- How to Remove a NOT NULL Constraint in Snowflake
- How to Remove a Default Value to a Column in Snowflake
- How to Rename a Table in Snowflake
- How to Rename a Column in Snowflake
- How to write a Common Table Expression(CTE) in Snowflake
- How to Write a Case Statement in Snowflake
- How to Use Coalesce in Snowflake
- How to Query a JSON Object in Snowflake
- How to Truncate a Table in Snowflake
- How to Group by Time in Snowflake
- How to Import a CSV in Snowflake
- How to Query Date and Time in Snowflake
- How to Convert UTC to Local Time Zone in Snowflake
- How to Avoid Gaps in Data in Snowflake
- How to Have Multiple Counts in Snowflake
- How do we Calculate the Running Total or Cumulative Sum in Snowflake
- How to Round Timestamps in Snowflake
- How to Calculate Percentiles in Snowflake
- How to Compare Two Values When One Value is Null in Snowflake
- How to do Type Casting in Snowflake
- How to Get First Row Per Group in Snowflake
- Snowflake Cloning - Zero Copy Clone
- Snowflake Competitors and Comparisons
- Snowflake Integrations
- Snowflake Key Features
- Snowflake Tables and View Management
- Snowflake Advanced Querying & Analytics
- Snowflake SQL Functions & Conditionals
- Snowflake DML and Constraint Operations
- Snowflake SQL Functions & Querying
- Snowflake DDL Commands, Tables, and Views
- Snowflake DML Commands and Examples
- Snowflake vs Other Data Warehouses
Are you curious about how Snowflake stores and manages data seamlessly? The behind-the-scenes secret is Snowflake’s hybrid architecture, which plays a key role in effective data management.
Snowflake’s hybrid architecture is an innovative approach that leverages a SQL query engine. It stands out among its competitors for its analytical capabilities and unique features.
This Snowflake architecture blog explains how Snowflake uses different architectural models to form its hybrid architecture. You’ll also learn about Snowflake schemas with examples.
Table of Contents
- Introduction
- Overview
- Detailed Overview
- Star Schema and Snowflake Schema in QlikView
- Star Schema vs Snowflake Schema
- Frequently Asked Questions
Introduction to Snowflake
Snowflake is a cloud-based data warehouse that simplifies loading, analyzing, and reporting large volumes of data.
It's a columnar-storage-based relational database that integrates with many external tools. Snowflake has its own query engine and supports multi-statement transactions, role-based security, DML, windowing functions, and other SQL database features.
Let’s take a look at some more key aspects of Snowflake in the following.
- Snowflake is a cloud-native SaaS platform that enables companies to establish and manage a storage system with enhanced scalability and reliability.
- It offers excellent governance, extended SQL support, security, and data exchange features.
- You don’t need to select, install, or maintain any software or hardware while using Snowflake.
- It handles all data storage operations effectively.
- It offers greater flexibility in managing big data.
| Want to enhance your skills to become a master in Snowflake Certification, Enroll in our Snowflake Training Certification Course |
Snowflake Architecture – Overview
Snowflake architecture is a mix of shared-disk and shared-nothing structures. Let’s start with understanding these structures and see how Snowflake integrates them to form a new hybrid architecture.
- Shared-disk Architecture: This architecture is commonly used in conventional databases. It consists of a single storage layer. Here, multiple cluster nodes connect to the centralized storage layer to retrieve and interpret data. All the cluster nodes share a common storage device.
- Shared-nothing Architecture: This architecture uses distributed cluster nodes, each with its own CPU, disk storage, and memory, unlike the shared-disk design. Because each cluster node has its own storage space, data can be divided and stored across these nodes.
Snowflake Architecture – A Deep Dive
Snowflake architecture consists of three distinct, self-scaling layers, as shown in the image below. They are cloud services, compute services, and cloud storage layers.
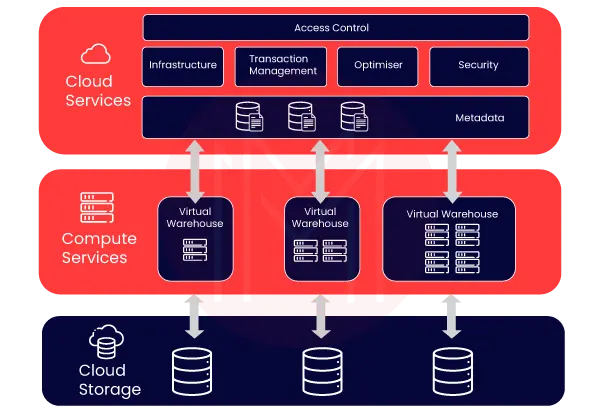
Let’s discuss these three layers one by one below.
Storage Layer
Snowflake divides data into many internally optimized, compressed micro-partitions. It stores data in a columnar format. Data is stored in the cloud and managed using a shared-disk architecture, simplifying data administration.
Compute units establish connections to the storage layer to retrieve information for query processing. Because Snowflake is cloud-based, storage space is elastic and billed monthly based on per TB consumption.
Compute Layer
Snowflake executes queries using virtual warehouses. It maintains a layer of separation between the query processing and the disk storage. This layer executes queries against the data.
Virtual warehouses are computing units composed of multiple nodes. Each node has a CPU and memory. You can create multiple virtual warehouses to meet varying workloads.
Each virtual warehouse operates independently and does not communicate with the others.
Cloud Services Layer
This layer performs operations, such as encryption, authorization, and query processing. It includes infrastructure, transaction management, SQL performance optimization, metadata, security, and database connectivity.
Whenever a new login process is initiated, it must traverse this layer. Also. Snowflake queries are routed through this layer's analyzer and then to the Compute layer for execution.
On top of all that, this layer stores the metadata required to improve a query or filter data.
The benefit of the Snowflake hybrid architecture is that each layer may be scaled independently of the others.
[Also Read: Snowflake Tutorial]
Star Schema and Snowflake Schema in QlikView
QlikView is a business intelligence platform for data discovery, analytics, and visualization.
In QlikView, relational database schemas fall into two types: the star schema and the Snowflake schema.
There are two types of tables used to store data, as listed below.
- Fact table
- Dimension table
Let’s take a close look at the tables.
Fact table:
A fact table contains numeric data. It may contain information such as IDs, keys, and related fields from the dimension table across the data model. The fact table is placed at the centre of the star schema or Snowflake schema, surrounded by dimension tables.
Dimension table:
The dimension tables contain descriptive or textual features of the data, such as Product ID, Manager ID, Product name, and Manager name. Each dimension table describes the data of that particular table.
For example, if a dimension table contains information about a product, it contains data specific to that product.
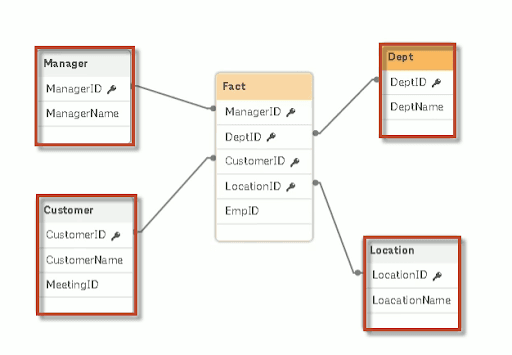
In the figure below, the highlighted ones show the Dimension tables. The one connected to all the dimension tables is known as the Fact table.
Star Schema - Overview
A star schema has a single fact table that connects to all the dimension tables via links. As the name suggests, it resembles a star, with a fact table at its centre and all dimension tables surrounding it.
A star schema represents the entity-relationship diagram between a Fact table and dimension tables. It shows how a fact table is connected with multiple dimension tables. In this schema, every dimension table has a primary key but no parent table.
- Data model:
A star schema data model consists of a main Fact table connected to multiple dimension tables via primary keys. This type of schema is commonly used for Online Analytical Processing (OLAP), which provides high speed. The resulting star schema has a hub-and-spoke or star-like representation.
Simply put, a star schema is a structure in which dimension tables are connected to the centrally located Fact table. The fact table contains the foreign keys or primary keys of all the dimension tables.
Example:
As shown in the figure, the centre table (Sales details) represents the Fact tables. Also, tables connected across the fact table are the dimension tables, such as Product details, Customer details, Place details, and Order details.
-
- Advantages of the Star schema: The advantages of the star schema are as follows:
- A star schema reduces the time required to load a large amount of data into the database.
- It provides efficient navigation through data, yet the dimension tables are joined to the fact table.
- It is designed to enforce the relation between the accuracy and consistency of loaded data.
- Queries run faster in a star schema.
- Advantages of the Star schema: The advantages of the star schema are as follows:
Snowflake Schema - overview
A snowflake schema is an enhancement of a star schema where every point of a star multiplies into several points. As you know, each dimension is represented by a single dimension table in a star schema.
But in the Snowflake schema, that dimension table is standardized into numerous lookup tables. A dimension table is further linked to the sub-dimension table through multiple links. It is useful when the dimension table becomes very large.
In this schema, a dimension table will have one or more parent tables. The hierarchies are divided into distinct tables. These hierarchies help move data from the topmost to the bottommost hierarchy.
- Data model:
The Snowflake schema data model consists of one or more fact tables connected to multiple dimension tables, forming a star schema. These dimension tables are further linked to the sub-dimension tables according to the data scaling.
As shown in the figure below, the fact table is connected to all the dimension tables via their primary keys. Some of the dimension tables are further linked to the sub-dimension table.
Unlike a star schema, the Snowflake schema organises data within the database to eliminate redundancy, thereby reducing data volume. This schema is commonly used for multiple fact tables with more complex structures and multiple underlying data sources.
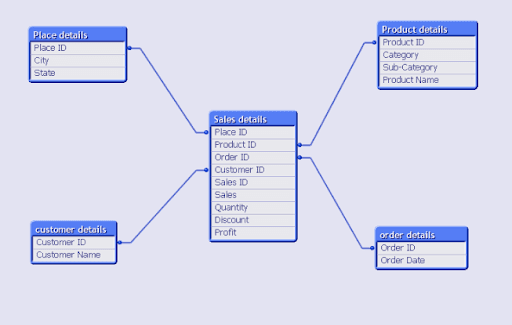
Example:
The fact table is connected to the Location table, as is the Dimension table. The Location table is further connected to the Location details table, as is the Sub dimension table.
-
- Advantages of the Snowflake schema: The advantages of the snowflake schema are as follows:
- It helps to increase flexibility.
- It is easy to maintain
- It improves query performance by minimising disk storage requirements and by connecting small lookup tables.
- Advantages of the Snowflake schema: The advantages of the snowflake schema are as follows:
Difference Between Star Schema and Snowflake Schema
| Description | Star schema | Snowflake schema |
| Data model | Top-down approach | Bottom-up approach |
| Normalization/ Denormalization | The fact table and Dimension tables are in the Denormalized form | The fact tables are in Denormalized form, whereas the dimension tables are in normalised form. |
| Ease of use |
|
|
| Ease of Maintenance | It contains redundant data and is harder to maintain and change. | No redundancy. Hence, Snowflake is easier to maintain and change. |
| Dimension Table | It contains only a single-dimensional table for each dimension. | It contains more than one dimension table for each dimension, depending on the data. |
| Query Performance | Fewer foreign keys and takes less time for execution. | More foreign keys result in longer execution times. |
| Joins | Fewer joins | More number of joins |
| Application | We can prefer the star schema when the dimension table has fewer rows. | We can prefer the snowflake schema when the dimension table is relatively big. So, this schema helps reduce data size. |
| The Top 40+ Best BigQuery Interview Questions & Answers 2025 article can help you understand key concepts and prepare for interviews. |
Frequently Asked Questions
1. Is learning Snowflake tough?
Ans: Snowflake is easy to learn. If you have foundational knowledge of data management and cloud computing, then you can learn Snowflake quickly.
2. How long will it take to learn Snowflake?
Ans: You can learn Snowflake within 25 hours. MindMajix offers advanced 25-hour Snowflake training in two modes: live online and on-demand training. You can choose the training mode based on your comfort and requirements.
3. How to prepare for Snowflake certification?
Ans: Snowflake offers multiple certifications that learners can use to evaluate their skills and stay competitive in the job market. To pass the certifications easily, you need to have:
- A thorough knowledge of Snowflake data warehousing concepts
- A deep understanding of Snowflake architecture and data management
On top of all that, attending professional Snowflake training with MindMajix will help you pass the certification exams successfully.
4. What would be the career prospects for Snowflake professionals?
Ans: Infosys, HCLTech, KPMG, Cognizant, UST, and many other top companies worldwide recruit Snowflake professionals.
5. What are the differences between Databricks and Snowflake?
Ans:
- Snowflake's multi-cluster warehouse offers better scalability than Databricks.
- Both platforms provide enhanced security and integration capabilities.
Conclusion:
Snowflake comes with a wide range of built-in features. A simple-to-use platform like Snowflake can go a long way toward improving your data warehouse use cases, making it easier to build and maintain. We hope this blog helped you gain a deeper insight into Snowflake Architecture.
If you are interested in exploring Snowflake features, you can enrol in a Snowflake course with MindMajix. It will help you learn Snowflake from the basics to core concepts in one place, advancing your career.
 On-Job Support Service
On-Job Support Service
Online Work Support for your on-job roles.

Our work-support plans provide precise options as per your project tasks. Whether you are a newbie or an experienced professional seeking assistance in completing project tasks, we are here with the following plans to meet your custom needs:
- Pay Per Hour
- Pay Per Week
- Monthly
| Name | Dates | |
|---|---|---|
| Snowflake Training | Jul 21 to Aug 05 | View Details |
| Snowflake Training | Jul 25 to Aug 09 | View Details |
| Snowflake Training | Jul 28 to Aug 12 | View Details |
| Snowflake Training | Aug 01 to Aug 16 | View Details |










