
- Splunk API
- Splunk Careers
- IBM QRadar vs Splunk
- Splunk Architecture
- Splunk Admin Interview Questions
- Splunk Alerts
- Splunk Alternatives
- Splunk CIM
- Splunk Cloud
- Splunk Dashboard
- Splunk Dedup
- Splunk Education
- Splunk Enterprise
- Splunk Enterprise Security
- Splunk Eval Commands With Examples
- Splunk Interview Questions
- Splunk Logging
- Splunk Regex Cheatsheet
- Splunk Rest API Overview
- Introduction to Splunk Rex
- Splunk Search Commands
- Splunk Software
- Splunk Stats
- Splunk Streamstats Command
- Splunk Timechart
- Splunk Tool
- Splunk Tutorial For Beginners
- What are Splunk Universal Forwarder and its Benefits
- Splunk vs ELK
- Splunk Alert and Report
- Monitor Windows Event Log Data – Splunk
- Splunk Universal Forwarder
- What are the Splunkbase Apps and Add-ons
- Splunk Join - Subsearch Commands & Examples
- What are Splunk Apps and Add-ons and its benefits?
- Top 10 OSINT Tools - Open Source Intelligence
- Grafana vs Splunk
- Elasticsearch vs Splunk
- Splunk vs Dynatrace
Splunk is a software platform used for searching, visualizing, and analyzing the machine-generated data collected from applications, sensors, websites, devices, etc., which constitute your IT infrastructure and business. It mainly works as a web-style interface to search, monitor, and analyze machine-generated big data.
In Splunk, we use different kinds of connectors to get or send the data to/from different platforms. Splunk Connect for Kubernetes is one of those connectors that is used for importing and searching the Kubernetes logging data. This Splunk Connect for Kubernetes blog will help you deploy and work with Splunk Connect for Kubernetes.
Table of Contents
- What is Splunk Connect For Kubernetes?
- Prerequisites to Connect Splunk For Kubernetes
- Steps to Connect Splunk For Kubernetes
- Managing the SCK Log Ingestion Through Annotations
- Search For the SCK Metadata
- Sending Logs to Ingest API
What is Splunk Connect For Kubernetes?
Splunk Connect for Kubernetes offers a way to import and search your Kubernetes object, logging, and metrics data in our Splunk platform deployment. Splunk Connect for Kubernetes supports searching and importing our container logs on the below technologies:
- Amazon Web Service (AWS), AWS Fargate, Elastic Container Service, and AWS Fargate.
- Amazon Elastic Kubernetes Service (Amazon EKS).
- Google Kubernetes Engine (GKE).
- OpenShift.
- Azure Kubernetes Service (AKS).
Splunk Inc. is the main contributor to the Cloud Native Computing Foundation (CNCF). Splunk Connect for Kubernetes uses and supports more than one CNCF component in the development of these tools for getting the data into Splunk.
| If you want to enrich your career and become a professional in Splunk, then enroll in "Splunk Certification Training". This course will help you to achieve excellence in this domain. |
Prerequisites to Connect Splunk For Kubernetes
- Splunk Enterprise 8.0 or later.
- An HEC token; see the below topics for more information:
- We must be familiar with our Kubernetes configuration and know where our log information is gathered in our Kubernetes deployment.
- Administrator Access to our Kubernetes cluster.
- For installing through Helm, verify we are running the Helm in our Kubernetes configuration. View https://github.com/kubernetes/helm for more information.
- At least two Splunk platform indexes are ready to gather the log data. One for both logs and Kubernetes objects and one for metrics. We can also create individual indexes for objects and logs; however, we will require three Splunk platform indexes.
Before we begin our deployment of Splunk Connect for Kubernetes, we must go through the prerequisites, installation, and deployment documentation. We should perform the following steps:
Step 1: Create at least two Splunk platform indexes.
Step 2: One event index will include objects and logs(we may also create two individual indexes for objects and logs).
Step 3: One metrics index. If we do configure the one metrics indexes, Kubernetes Connect for Splunk utilizes the defaults generated in our HEC (HTTP Event Collector) token.
Step 4: Create the HEC token if we do not already have it. If we are installing a connector on Splunk Cloud, file the ticket with Splunk Customer Service, and they will deploy indexes for our environment and create our HEC token.

How to Connect Splunk For Kubernetes?
1. Deploy with Helm
Helm enables the Kubernetes administrator to install, handle, and upgrade the applications running in the Kubernetes clusters. Access the Helm repository and site for the product and tutorial documentation for more information on utilizing and configuring Helm charts. Helm is the only way to install Splunk Connect for Kubernetes.
For installing and configuring defaults using Helm:
Step 1: Add the Splunk chart repo
helm repo add splunk https://splunk.github.io/splunk-connect-for-kubernetes/Step 2: Get the values file in our working directory
Helm 2
helm inspect values splunk/splunk-connect-for-kubernetes > values.yamlHelm 3
helm show values splunk/splunk-connect-for-kubernetes > values.yamlStep 3: Prepare the values file. After preparing the values file, we can install the chart by running.
Helm 2
helm install --name my-splunk-connect -f values.yaml splunk/splunk-connect-for-kubernetesHelm 3
helm install my-splunk-connect -f values.yaml splunk/splunk-connect-for-kubernetes
2. Deploy Through YAML
We can grab the manifest YAML files and utilize them for creating the Kubernetes objects required for deploying the Splunk Connect for Kubernetes. When we utilize YAML for deploying the Splunk Connect for Kubernetes, the installation does not produce the default configuration that is created when we install it through Helm.
For deploying the connector through YAML, we should know how to configure our Kubernetes variables to work with the connector. If we are unaware of this process, we suggest utilizing the Helm installation method.
For configuring the Splunk Connector for Kubernetes through YAML files:
- Get the charts and manifest files from https://github.com/splunk/splunk-connect-for-kubernetes
- Read all the YAML files in the manifests folder and make the required modifications. Please note that the YAML files in the manifest folder are examples and are not anticipated to be utilized as provided.
- Check whether Splunk Connect identifies our Kubernetes logs for Kubernetes.
3. Architecture
Splunk Connect for Kubernetes deploys the DaemonSet on each node. In the DaemonSet, a fluentd container performs and runs the collecting job. Splunk Connector for Kubernetes gathers three kinds of data:
- Logs: Splunk Connect for Kubernetes gathers two kinds of logs:
- Logs from Kubernetes System Components (https://kubernetes.io/docs/concepts/overview/components/)
- Applications(containers) logs
- Objects
- Metrics.
For gathering the data, Splunk uses:
- Fluentd
- JQ Plugin to transform the data
- Filter_jq_transformer transforms the raw events to the Splunk-friendly format and creates the source and sourcetypes.
- Out_splunk_hec transmits the converted logs to our Splunk platform indexes using HTTP Event Collector(HEC) input.
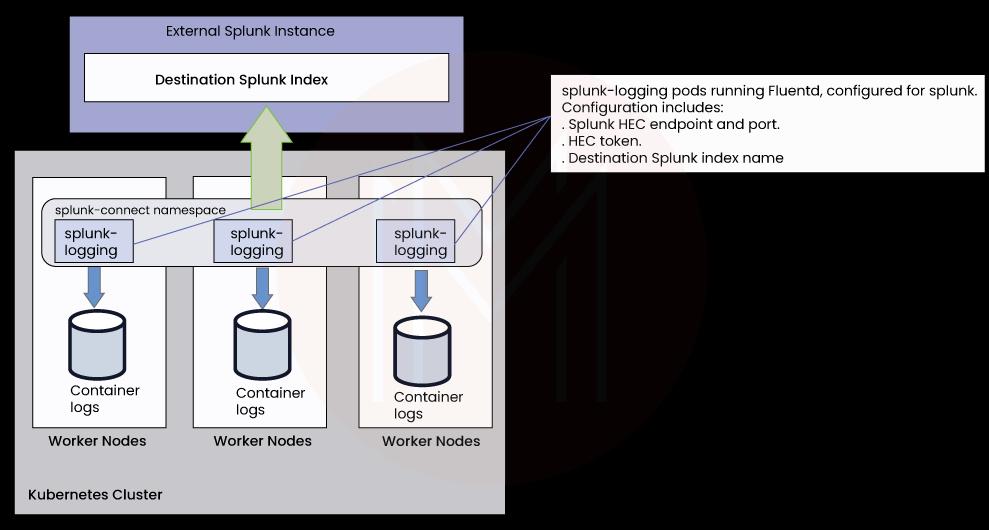
4. Kubernetes Objects
Splunk connects for Kubernetes and gathers Kubernetes objects that enable users to access cluster status. Splunk deploys the code in the Kubernetes cluster that gathers object data. That deployment includes one pod that executes Fluentd, which includes the plugins below for helping push the data to the stack.
- In_kubernetes_objects gathers object data by invoking Kubernetes API (by https://github.com/abonas/kubeclient). in-kubernetes-objects supports two nodes:
- Wach mode: The Kubernetes API transmits new modifications to the plugin. In this mode, only the modified data is gathered.
- Pull mode: The plugin queries Kubernetes API regularly. In this mode, all the data is gathered.
- filter_jq_transformer converts the raw data into a Splunk-friendly format and creates sources and sourcetypes.
- Out_splunk_hec transmits the data to Splunk through HTTP Event Collector input(HEC).
5. Metrics
- Splunk Connect for Kubernetes deploys daemon sets on the Kubernetes cluster. These daemon sets contain only one pod, which executes one container:
- Fluentd metrics plugin gathers metrics. It formats the metrics for the Splunk ingestion by ensuring the metrics have appropriate metric_name, dimensions, etc., and then transmits them to Splunk through out_splunk_hec through Fluentd engine.
- Assure that our Splunk configuration contains a metrics index that can receive the data.
6. Performance
Some parameters utilized with the Splunk connect for Kubernetes can have an impact on the overall performance of the log ingestion, objects, or metrics. Generally, the more filters we add to one of the streams, the greater the performance effect.
Splunk Connect for Kubernetes can surpass the default throughput of the HEC. To handle the capacity requirements, Splunk suggests we monitor HEC throughput and back pressure on the Splunk Connect for the Kubernetes deployments and be prepared to add the extra nodes as required.
Managing the SCK Log Ingestion Through Annotations
Handle Splunk Connect for Kubernetes with these supported Annotations:
- Use “splunk.com/index” annotation on pod or/and namespace for telling which splunk platform indexes for ingesting to the Pod annotation will take priority over namespace annotation while both are annotated. Ex: ubectl annotate namespace kube-system splunk.com/index=k8s_events
- Set “splunk.com/exclude” annotation to true on pod or/and namespace for excluding ist logs from the ingested to our Splunk platform deployment.
- Use “Splunk.com/sourcetype” annotation on the pod to overwrite the “sourcetype” field. If not set, it is dynamically created to be container:CONTAINER_NAME. Please note that sourcetype will be preceded with the.Values.sourcetypePrefix (default: kube).
Visit here to learn Splunk Training in Bangalore
Search For the SCK Metadata in Splunk
Splunk Connect for the Kubernetes sends events to Splunk, which can include meta-data attached to every event. Metadata values like “namespace”, “pod”, “cluster_name”, “container_id”, and “container_name” will show up as the fields while viewing the event data in Splunk. There are two solutions to run the searches in Splunk on the meta-data.
- Modify the search using “fieldname :: value” rather than “fieldname=value”
- Configure the “fields.cmf” on the downstream Splunk system for having our meta-data fields be searched through “fieldname=value”.
Sending Logs to Ingest API
Splunk Connect for Kubernetes can be utilized for sending the events to the Splunk ingest API. In ingest_api section of the yaml file we are utilising to deploy, the below configuration options must be configured.
- ServiceClientSecretKey: Splunk Connect for Kubernetes utilizes the client secret key for making authorized requests to ingest API.
- serviceClientIdentifier: Splunk Connect for Kubernetes utilizes the client identifier for making the authorized requests to ingest API.
- ingestAPIHost: Indicates which URL or hostname to use for the requests to ingest API.
- tokenEndpoint: This value specifies which endpoint Splunk Connect for Kubernetes must look out for the authorisation token required to make requests to ingest API.
- eventsEndpoint: Specifies which endpoint to use for the requests to ingest API.
- Tenant: Implies which tenant Splunk Connect for Kubernetes must use for the requests to ingest API.
- debugIngestAPI: Set to True if we want to debug the requests and responses to ingest API.
| Check out Top Splunk Interview Questions and Answers that help you grab high-paying jobs |
Conclusion
Splunk is a Big data analytics tool that is used for analysing and visualising the machine-generated data collected from different data sources. The Splunk connect for Kubernetes enables us to import and search our Kubernetes objects, logging, and metrics data in the Splunk deployment. I hope this Splunk Connect for Kubernetes will give you the sufficient information about Splunk Connect for Kubernetes. If you have any queries, let us know by commenting below.
 On-Job Support Service
On-Job Support Service
Online Work Support for your on-job roles.

Our work-support plans provide precise options as per your project tasks. Whether you are a newbie or an experienced professional seeking assistance in completing project tasks, we are here with the following plans to meet your custom needs:
- Pay Per Hour
- Pay Per Week
- Monthly
| Name | Dates | |
|---|---|---|
| Splunk Training | Jul 28 to Aug 12 | View Details |
| Splunk Training | Aug 01 to Aug 16 | View Details |
| Splunk Training | Aug 04 to Aug 19 | View Details |
| Splunk Training | Aug 08 to Aug 23 | View Details |

Viswanath is a passionate content writer of Mindmajix. He has expertise in Trending Domains like Data Science, Artificial Intelligence, Machine Learning, Blockchain, etc. His articles help the learners to get insights about the Domain. You can reach him on Linkedin