
- Blue Prism vs Selenium
- Career Scope in Selenium-The Future of Testing
- Essene of Getting Certified in Selenium
- Getting Started With Selenium
- Top 10 Reasons Why You Should Learn Selenium
- Selenium Interview Questions
- Selenium Release History Infographics
- Selenium Tutorial
- Tosca vs Selenium
- Automation Selenium RC using TestNG - Selenium
- Commands in Context Menu - Selenium
- Debugging - SELENIUM
- Different Flavours of Selenium
- Finding Elements by XPATH and Using CSS - SELENIUM
- How to Create test suites in Selenium
- How to Setup and Configure Selenium Webdriver with Eclipse
- How to use WebDriver Backed Selenium
- How to work on pages with AJAX in selenium?
- How to Install Debugbar Tool - SELENIUM
- How to Install IE Developer Tool - SELENIUM
- Installation of Selenium IDE
- Introduction to Selenium
- Introduction to Selenium 2.0 Webdriver-SELENIUM
- Java Tutorial for Selenium WebDriver
- How to Locate & Find Elements - SELENIUM
- Locators & How to Install Firebug - SELENIUM
- Running Test Cases - SELENIUM
- Sample Programs in Remote Control for Selenium
- Selenium Commands – “Selenese”
- Selenium Commands with Examples - SELENIUM
- Selenium WebDriver Commands List
- Synchronisation commands - SELENIUM
- What Is Selenium RC : A Step-by-Step Guide for 2024
- XPATH Usage in Selenium
- Skills That Will Make You a Champ Software Tester with Latest Trends
- Tricentis Tosca Automation Tool (2025)
- Tosca Interview Questions for 2025
- Using Selenium to Interact With Elements on a Web Page
- What is Selenium? - Selenium Automation Testing Introduction
- What is selenium IDE
- Selenium WebDriver Interview Questions
- Selenium With Python Interview Questions
- Selenium Projects and Use Cases
- How to Install and Configure Selenium WebDriver?
XPath is a computer programming language that stands for XML Path Language. It is the XSLT standard's major element. XPath enables flexible navigation through attributes and elements in an XML document. The nodes are identified and navigated through "path-like" syntax in an XML document by XPath. Over 200 built-in functions are contained in XPath. The World Wide Web consortium developed the XPath, and it appeared first in 1998.
Let us have some more useful insights on XPath before moving forward-
- The market share of XPath in the Programming Languages Category is around 0.3% as per the enlyft report. That means not many people compete in this category.
- The industries where the XPath is used the most are Information Technology and services (15%) and Computer Software (27%).
- The top locations that use XPath are the United States (62%), the United Kingdom (6%), and India (5%).
As we have gained the basic idea of XPath, let us move ahead and look at the XPath Interview Questions- updated (2024) and Answers respectively for each of the following categories-
Top 10 XPath Interview Questions and Answers:
XPath Interview Questions and Answers for the Freshers:
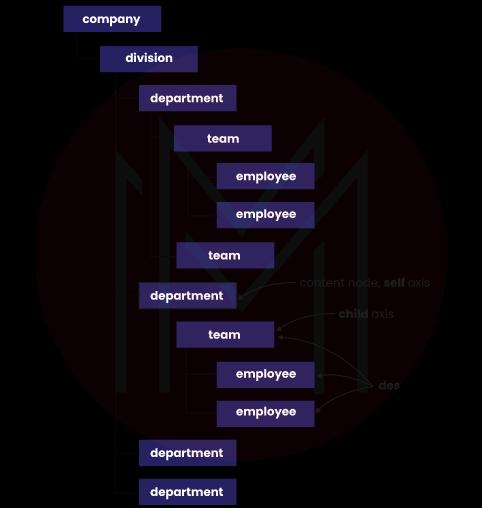
1. What is meant by XPath axes?
We use XPath axes for identifying the elements by their relationship, such as child, parent, sibling, etc. It is just like the way in which the location of the node is defined by the path.
2. List and explain the different XPath axes.
A list of XPath axes for setting relation from the current node to others is given below-
- Attribute- we use it to get all the attributes of the current node.
- Ancestor- we can get all the ancestors (grandparents, parents, etc.) of the current node.
- Ancestor-or-self- we can get the ancestors of the current node as well as the current node itself.
- Child- we can obtain all the children of the current node.
- Descendant- we can retrieve all the descendants (grandchildren, children, etc.) of the current node.
- Preceding- it is used for getting everything in the document coming before the start of the current node.
- Namespace- we can retrieve all the namespace nodes of the current node.
3. What is meant by XPath operators?
Functions and operators on nodes are defined by XPath. A string, node-set, a number, or a Boolean is returned by the expression of XPath.
4. What are the different kinds of operators provided by XPath?
There are different categories of operators in XPath as per their properties. And the different types of XPath operators are given below-
- Boolean operators
- Comparison operators
- String functions
- Number operators/functions
- Node operators/functions
5. How is the relationship among nodes defined?
The nodes that are available in XPath are given below. And these are related to each other in a structure like tree. The nodes are-
- Parents
- Children
- Siblings
- Ancestors
- Descendants
An example-
<book>
<title>The Alchemist</title>
<author>Paulo Coelho</author>
<year>1993</year>
<price>200.00</price>
</book>6. What is meant by the comparison operators provided in XPath?
XPath comparison operators are used for comparing one value to another. Some of the different types of comparison operators are given below-
- <
- >
- =
- !=
- <=
- >=
7. What is meant by the number of operators provided in XPath?
The XPath number operators are used for mathematical computing operations on different keywords. There are five different number operators in XPath, and they are given below-
- +
- _
- *
- Mod
- Div
8. What is meant by the boolean operators provided in XPath?
The Boolean operators are the simple words that are used for combining or excluding keywords. They include OR, AND, NOT, etc. They are used for connecting our search words to either expand or concise our set of results.
| Looking forward to becoming a master in Selenium? Check out the "Selenium Training" and get certified today. |
9. What is meant by the number of functions provided in XPath?
The number functions in XPath are used for fetching the different kinds of values from the expressions. The examples include ceiling value, example, floor value, etc. XPath provides four types of number functions, and they are given below-
- Sum()
- Round()
- Floor()
- Ceiling()
10. What is meant by the string functions provided in XPath?
Some rules are specified by the XPath string functions, which we use for getting strings according to our preferences.
11. What is meant by an atomic value in XPath?
The nodes that have no child node or parent node are referred to as Atomic values.
For instance-
<book>
<title>The Alchemist</title>
<author>Paulo Coelho</author>
<year>1993</year>
<price>200.00</price>
</book>Here, Paulo Coelho is an atomic value.
12. What is meant by the XPath predicate?
The XPath predicate is the XPath expression that is written in brackets. The selected nodes are restricted in a node-set for some conditions.

13. How can XPath be executed in Jquery?
The XPath can be executed in jQuery by using $x as follows-
$x("//XPath")14. Give an example to illustrate what is parent in a code.
<book>
<title>The Alchemist</title>
<author>Paulo Coelho</author>
<year>1993</year>
<price>200.00</price>
</book>Here, the book element is the parent of title, author, year, and price.
15. Give an example to illustrate what is an ancestor in a code.
<bookstore>
<book>
<title>The Alchemist</title>
<author>Paulo Coelho</author>
<year>1993</year>
<price>200.00</price>
</book>
</bookstore>Here, the bookstore element is the ancestor of the book, title, author, year, and price.
XPath Interview Questions and Answers for the Experienced:
1. How is dynamic text handled in XPath?
The text function finds the elements with the help of the text present in them.
<button type = “button”>Blueberry</button> (Blueberry is text here.)
XPath with text : //button[ text() = ‘Blueberry’ ]But contains function has to be used along with text function when the text is dynamic. And some part of the string needs to be static for this to work.
<button type = “button”>*****berry</button>
XPath with text : //button[ contains( text(), ‘berry’) ]2. When is the position function used?
The position function lets the user obtain the match at a particular index. The elements that are greater than the position or less than the position can also be obtained using the position function.
3. Can the XPath be used inside a frame?
The frame is nothing else but another webpage which is shown as a different web page. Therefore, we can use the XPath just like a normal web page once we go into the frame.
4. Write the XPath for a button.
The XPath for a button is written as given below. The button can be formed in two ways- by using input tag or button tag.
// form button using the input tag
<input type = “button’ value = ‘ABCD’>
XPath : // input [ @type = ‘button’ ]
// form button using the button tag
<button>ABCD</button>
XPath : // button5. How are the lower and upper case attributes handled in XPath?
The @method can be used for an attribute. But the @method might not help us in case the attribute value keeps changing from lower to upper case or the mix of changes. In such situations, the case (lower/upper) should be ignored.
6. Differentiate between XPath and CSS.
- The XPath allows us to traverse both forward as well as backward. On the other hand, XSS allows only forward movement.
- Because the engines of XPath are different in each browser, it becomes a bit inconsistent.
| Check Out - Finding Elements by XPATH and Using CSS |
7. What is meant by an XPath query?
We are allowed to select nodes from a document through the expression in an XPath query. For instance, all the elements with a "text" tag can be asked and then filtered by the opening tags.
An XPath query is a bit more complex than an XPath location path as some form of search and logic is required for identifying what nodes are desired. These are useful expressions resulting in Boolean values- true/false by which the nodes are returned on the condition satisfaction.
8. Which XPath function can be used for removing unnecessary white spaces in a string?
We can use the normalized-space function for stripping white space from a string and replacing sequences of white space characters with a single space. And then the resultant string is returned.
9. List the most useful path expressions in XPath.
| Expression | Description |
| nodename | All the nodes will be selected with the name "nodename." |
| / | Selection will be made from the root node. |
| // | The selection will be from the current node document matching the selection regardless of the location. |
| . | The current node will be selected. |
| .. | The parent of the current node will be selected. |
| @ | The attributes will be selected. |
10. How are unknown nodes selected in XML?
We use XPath wildcards to select unknown XML nodes-
| Wildcard | Description |
| * | Any element node can be matched. |
| @* | Any attribute node can be matched. |
| node() | Any node of any kind can be matched. |
11. What selection will be made if you use "child::book" and "attribute::lang" respectively?
child::book- Here, all book nodes that are children of the current node will be selected.
attribute::lang- Here, the lang attribute of the current node will be selected.
12. Differentiate between XSLT, XPath, and XQuery.
XSLT is a language that is used for transforming XML documents.
XPath is a language that is used for navigating XML documents.
XQuery is a language that is used for querying XML documents.
13. Give an example of the usage of a predicate.
softwareTester[ @name = “T1” ]
Here, the element <softwareTester> with the attribute – T1 will be selected.
14. What will be located with "//@*" and "//@id" respectively?
//@* - All attributes within the XML document will be selected.
//@id – The id attribute within our XML documents will be selected.
15. What will be the result of "//title [ @lang = 'en]?
It will result in the selection of all the title elements having a "lang" attribute with the value - "en."
Frequently Asked XPath Interview Questions and Answers:
1. List a few languages in which the XPath expressions can be used.
Major languages in which XPath expressions can be used are given below-
- C
- C++
- JavaScript
- Java
- Python
- XML Schema
- PHP
2. Which major companies use XPath?
The major companies that use XPath are-
- United Airlines
- Boeing
- Fujitsu
- SpendBridge
3. List down the main features of XPath.
Some of the major features of XPath are enlisted below-
- XPath is a major XSLT standard element.
- It can define any part of an XML document flexibly.
- It stands for XML Path Language.
- The expressions of XPath are case-sensitive.
- We can use it for querying data from XML documents.
- We can easily navigate XML documents using it.
- Path expressions are used by XPath for navigating in XPath.
4. What are the main benefits of XPath?
The main benefits of XPath are given below-
- The queries are compact.
- Queries are easily parsed.
- It is easy to type and read queries.
- The syntax is simple.
- A node can be uniquely identified in an XML document.
- Any number of results can be returned by queries, including 0.
- We can evaluate queries at any level of a document.
- XPath can be used in several contexts, including searching repositories.
- Queries are declarative rather than procedural.
5. What is meant by XPath expressions?
The nodes and node sets are selected in an XML document by these path expressions or patterns. XSLT uses these patterns for performing transformations.
| Check Out: XPATH Usage in Selenium |
6. What are the types of nodes available in XPath?
Seven types of nodes are specified by XPath as the output of XPath expressions' executions. The list is given below-
- Element
- Root
- Text
- Comment
- Attribute
- Namespace
- Processing Instruction

7. How many location path types are available in XPath? Name them.
There are two types of location paths that the XPath provides. They are as follows-
- Absolute path- It starts with '/' or root node.
For example-
/company/employee- Here, the employee nodes will be selected within the class root node. - Relative path- A relative path is the one that starts with the node selected by us.
8. What do you mean by XPath syntax?
Different nodes, predicates, path notations, path expressions, and URLs are specified by the XPath syntax, which we can use for defining the XML document.
9. What are the different types of standard functions provided by XPath?
There are more than 200 built-in functions available in XPath. And we can use these functions in string values, boolean values, date and time comparison, numeric values, sequence manipulation, etc.
10. What happens when the top-level element is present in XSLT?
- There is no effect of the top-level elements on XSLT elements' behavior.
- Also, there is no effect on the functions that are defined with it in the document.
- There is no permission granted to the top-level elements to be used by the specification of XSL: apply templates.
- Some of the top-level elements are ignored in case an error occurs in XSLT.
- The namespace URI is not recognized by the XSLT top-level element. But it can be provided using other resources.
Conclusion:
It is relatively easy to write program phrases than to understand the XML- style as well as the sequence of each word in a document. Also, a high level of abstraction could be easily understood and handled through XPath. This makes it an important part of XML that is cherished by all its users. Therefore learning XPath proves to be a great asset. And we hope that we were successful in helping you revise the XPath Interview Questions through this compilation.
 On-Job Support Service
On-Job Support Service
Online Work Support for your on-job roles.

Our work-support plans provide precise options as per your project tasks. Whether you are a newbie or an experienced professional seeking assistance in completing project tasks, we are here with the following plans to meet your custom needs:
- Pay Per Hour
- Pay Per Week
- Monthly
| Name | Dates | |
|---|---|---|
| Selenium Training | Aug 04 to Aug 19 | View Details |
| Selenium Training | Aug 08 to Aug 23 | View Details |
| Selenium Training | Aug 11 to Aug 26 | View Details |
| Selenium Training | Aug 15 to Aug 30 | View Details |















