
- MSBI Career Opportunities
- MSBI Interview Questions
- MSBI Interview Questions
- Action Properties Dialog Box (Report Builder and SSRS) - MSBI
- Best Practices for Performance Tuning in SSAS Cubes
- Conformed Dimension in SSAS with Example
- Data Warehousing Concepts in SSIS
- How To Debug SSIS Packages in SQL Server
- How to Access Report Manager in SSRS 2012
- How to Create Cube in SSAS with Example
- How to Create Drill Down report in SSRS 2008
- How to Create Table Report in Reporting Services - MSBI
- How to Implement Proactive Caching in SSAS - MSBI
- How to Publish Report to a Report Server in SSRS
- Checkpoints in SSIS
- Incremental load in SSIS with example
- Introduction to SQL Server Analysis Services
- Learn to Write MDX Queries in Analysis Services (SSAS)
- MSBI Advantages and Its Data Evaluation Stages - MSBI
- Named Query & Named Calculation in SSAS
- Normalization and T-SQL in SQL Server
- Passing Parameters to a report in SSRS
- Report and Group Variables in Reporting Services - MSBI
- Reporting Services Configuration Files – SSRS
- How to Set Transaction Isolation Level in SQL Server
- SQL Server 2008 R2 – LookUp Enhancement in SSRS
- SQL Server Analysis Services Aggregation Designs
- Partitions In SSAS
- SQL Server Data Modeling
- SQL Server Performance Tuning Tips and Tricks in MSBI
- SQL Server Reporting Services Performance Tuning - MSBI
- SSAS Analysis Services Cube Deployment Methods
- SQL Server Integration Services – SSIS Architecture Overview
- Step by Step MSBI Installation and Requirements - MSBI
- Step by Step SSIS Package Deployment
- TextBox Properties in SSRS 2008
- SSIS Control Flow
- Working with Report Models in SSRS
- Working with SSRS Reporting Services Configuration Manager
- T-SQL Interview Questions
These are the SSIS practicals in MSBI
- Architecture
- Execution
- Data flow task operations
- Sources
- Destinations
- Transformations
SSIS Practical Architecture
Solution (collection of projects) –> Project (collection of packages) –>Package (A discrete unit of work for doing ETL operations & Administrative tasks)
- Control flow (Tasks, containers, plan tasks, maintenance)
- Data flow (Sources, Destinations, Transformations)
- Package explorer
- Event Handling
Start àPrograms –> SQL server 2008 –> click BIDSà File –> New –> Project –> Select ‘integration services project’ in templates window –> Enter name –> click ok
Project Name: Test_Solution_Project
Location : E:/Test
By default there is no solution is presented, so we can create a solution at the project creation time.
–> Click view menu –> Solution explorer (It describes the projects, packages, data source views, data source information)
↓
[It is used to connect to the DB it can be reusable “ACROSS packages”]
Data source view:
It is the logical object for the physical collection of tables or view in data sources.
Connection manager:
For every connection we can take a name, name can be reusable within the program (or) package.
In case of flat file: Folder the file name taken as connection string for connection manager.
In case of relation, source: Server name and data base name taken as part of connection string in connection manager.
Various ways of package execution:
a) By pressing “F5”
b) Solution explorer –> packages –> Right click –> Execute package
c) Debug menu –> Start debugging
d) SSMS –> Integration services –> MSDB –> package –> rtclick –> run package
e) By using DTUTIL, DTUTIL Exec.facilities …etc
Colors and their meanings:
White –> Ready to execute
Yellow –> Running
Red –> Fail
Green –> Success
Grey –> disable
Ensuring Package success, Failure, Errors, Bottlenecks:
We observe this information in “Progress tab” or “Log Providers”
(a) Progress tab information: It describes how the package validated and executed step by step from starting to ending. Generally it displays
- The no. of rows operated
- Source and destination connections
- The amount of time taken b/w one statement to another statement etc
(b) Log Providers: discussed later in this book
Variables
It is the value which is changeable within the package. There are two types of variables they are
1) System defined variables: These variables hold system information.
These variables store under SYSTEM
Syntax:SYSTEM: : < variable Name>
Ex: SYSTEM : : PACKAGE NAME
SYSTEM: : Execution ID
2) User Defined Variable: These variables are created by the user only. These variables store under user name space
Syntax: USER : : i
USER : : Name Var
USER : : Temp_date ..etc

Navigation:SSIS Menuàvariablesà in the variables window click the top most left corner option to create new variable.
Name Scope Data Type Value
l Package Int 32 1
Variable scope: The extent we use the variable is called the scope of variable. There are 2 scopes
a) Package Level: Within the package anywhere we can use this variable
b) Task Level: Within the task only we can use the variable.
Working with Data Flow Task
To move the data from source to destination and to perform intermediate operations this task is mandatory. Frequently used sources are flat file source and OLE DB source and frequently used destinations are flat file destination and OLE DB destination.
Real time modes of flat file sources:
123 VINAY 123 VINAY
456 SIVAM 25 KISHORE
Fixed width Delimited (separated or Variable text)
ID –> 3 chars ID à Max 10 char
Name –> 5 char Name à Max 30 char
Row Delimiter:- ‘|’(pipe)
Column Delimiter:- ,(comma)
Row Delimiter:- CRLF(enter char) [carriage return line or forward]
Column Delimiter:- No
Eg:- Moving data from file to file (comma delimited)
Sol:- 1. Take data flow task on control flow
2. Go to data flow task à drag and drop flat file source & destination and do the below settings.
INPUT: Party_3RC –> notepad
File name: Party_3RC
No of rows: 13
.PNG&w=16&q=75)
–> Connection Manager Name is reusable in the packages.
IS Project 1:- Microsoft visual studio.

FLAT FILE Source:- FLAT FILE Destination:-
Select –> rtclick –> Edit select –> rtclick –> Edit
Flat file connection manager flat file connection manager –>
Click New click new –> select Delimited –> click ok
Connection manager name: SRC Connection manager name: TGT
File name: Browse to the i/p folder File name: Browse to the o/p folder
Party_SRC.Txt file. and specify party_output.txt
Format: Delimited Format: Delimited
Header Row Delimited: {CR}-{LF} Header Row Delimited: {CR}-{LF}
Header Row to skip: 1
Column names in the first data row: Column names in the first data row:
Check it Check it
Click preview –> click ok –> ok Click preview –> click ok –> ok, Go to mappings –> check whether required target columns – -> ok.
After assigning both source and destination
OLE DB:- Object Linking and embedding Data Base
Eg:- Moving data from table to table from source data base
DB_MSBI to MSBI_DB destination data base
Navigation: open BIDS à take data flow task in control flow
OLEDB source —-> OLEDB Destination
OLEDB –> Object linking and embedding data base –> Universal provider to any data base or application (excel..etc)
OLEDB source –> Rt click –> edit –>
OLEDB connection manager –> New –> New
Provider: native OLEDB Native SQL server client 10.0
Server name: local host
Select Authentication: windows (or) SQL server.
Select database: DB_MSBI
Click test connection –> ok –> ok –> ok
Name of the table or view –> emp –>ok –> ok
OLEDB Destination –> Rtclick –> edit
OLEDB connection manager –> New –>New
Provider: native OLEDB native SQL server client 10.0
Server name: local host
Select Authentication: windows (or) SQL server.
Select database: DB_VINAY
Click test connection –> ok –> ok –>ok
Name of the table or view –> click new –> change table name –>ok
Go mapping –> connect required source column to required from one work sheet in another excel
Eg: moving data from flat file to Raw file.
Raw file contains binary information, so we are not able to read.
.png&w=16&q=75)
–> raw file destination –> edit –> connection manager –> rtclick
Access mode –> file name
File name –> file path
Write always –> create always
Columns –> select columns –> ok
Eg: loading data from XML file to table in SQL server database.
.png&w=16&q=75)
XML_SCR.XML
001_Vinay
Vinay
< /Student 1>
< Student 1>
002_Siva
Siva
< /Student 1>
XML source –> rtclick –> edit –> data access mode –> XML location
OLEDB dest –> Generate XSD –>Ok.
Note: XML schema definition must be specified (or) generated to the corresponding XML file.
Frequently Asked MSBI Interview Questions & Answers
Transformation:
These are intermediate operations performed between source and destination.
Eg: concatenation, addition, sorting, merging etc.
There are different data flow transformations provided for different operations.
Sort transformation:
It sorts the data in the specified order (ascending or descending)
It has some flexibility to do sorting on multiple columns (by giving sort order)
There is a feature called “remove rows with duplicates” which helps us to display unique rows in sorting by eliminating duplicates.
Eg: display the data by location in ascending order, with in the location names in descending order.
.png&w=16&q=75)
–> Rc –> EDIT Available input columns –> select columns
- Parityloc
- Partyname
??.PNG&w=16&q=75)
Derived column transformation:
It performs operation row by row. It does different calculations, aggregation, concatenation, transformations, conversions etc for the columns in the rows.
Eg:
a) Display name and location by concatenation.
b) Display income, if it is null 99999.
c) Display income increment by 12%.
d) Display a new field with current date as business date.
e) Display default company code as 21000.
.png&w=16&q=75)
Note:
I. When we retrieve the data from flat file, all the columns belong to string data type (DT-STR).
II. When we retrieve the data from excel sheet, all the file it’s belong to (DT-WSTR).
Data conversions:
Data conversions are done in three ways.
a) By using data conversion transformation.
b) By using type cast operator in expression.
Syntax:
(column name).
(DT-I4) (PartyIncome)
(DT-DBDATE) (‘2010-10-10’)
c) Directly doing at flat file source itself.
Rt click on flat file source –> show advanced editor –> input and output properties –> flat file source O/P –> output columns –> party income –> data type properties –> data type →four-byte signed integer(DT-I4)
Aggregate Transformation:
It performs aggregate operations such as average, sum, count, min, max, count distinct, group by
- If the field or expression is of numeric data type we can perform the above all the operations.
- If the field is string or data, we perform limited operations group, count, distinct count etc.
Eg: display location wise income sum and average.

.PNG&w=1200&q=75)
Flat file source addition properties:
àRetain null values from the source as null values. It helps us to treat nulls coming from the source as nulls only. (if we uncheck this option null treated as zero for integers, space for string)
Error output options:
In case of error or truncated values coming from source we can use either of the below options.
a) Ignore failure → in case of error or truncations it ignores the failure.
b) Redirect row → in case of error or truncation it redirect the row to the another destination.
c) Fail component → in case of error or truncation it simply fails the component.
Navigation:
Flat file source àrtclickàeditàerror O/P.
Flat file destination files format:
- Delimited àthe columns are delimited by commas, expect the last one which is delimited by the new line character.
- Fixed widthàthe columns are defined by fixed widths.
- Fixed width with row delimiters àthe columns are defined by fixed width. An extra column, delimited by the new line characters is added to define row delimiters.
- Ragged right àthe columns are defined by fixed width, expect the last one which is delimited by the new line character.
OLEDB Source properties:
OLEDB Source àrtclickàeditàdata
Access mode:
- Table or view
- Table name or view name variable
- SQL command
- SQL command from variable
Note: we use variables for dynamic source retrieval.
Multicast Transformation:
It creates multiple copies of some source. So that instead of doing multiple operations on the same source in multiple package we can do in a single package by using multicast.
→ It improves the performance because it reads the data only one time from the source.
Package-1 package-2 package-3
EMP EMP EMP
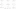
- Three buffers for source
- Multiple read on source
Advantages of single package split
.png&w=1080&q=75)
- Source read only one time
- Single time buffer occupation
Merges transformation:
It Merges multiple input data source here the restriction is the sources should be the sorted order so that the output will also be in the sorted order.
There are two ways to implement
If the source are not in sorted order do the below process
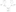
Conditional split transformation:
a) It splits the data based on the condition.
b) There are two types of output comes from this transformation.
Conditions matched output.
Conditions unmatched output or default output.
Eg: move HYD, Bang, data to separate files and unmatched data to another file.
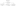
→ Conditional split → rt clickà
ORDER OUTPUTNAME CONDITION
1) HYD-DATA [PARTYLOC]=”HYD”
2) BLORE-DATA [PARTYLOC]=”BLORE”
Default output name → Unmatched-data → Ok
Union all transformation:
- It merges multiple input sources (two or more)
- No need to take the input in the sorted order, so that the output will also have unsorted data.
.png&w=16&q=75)
Limitations:
1) Input sources structures should be same. [No.of columns, order of data type of columns]
OLEDB Source Editor Properties
Data access mode:
- Table or view → to retrieve the data from table or view
- Table name or view name variable → table name or view name takes from the table
- SQL command → we write a customized query to retrieve the data from the object, so that required rows and column retrieved and occupies less buffer every time. Eg: select Party ID, Party Name from Party where Party code in (20, 40, 60)
- SQL command from variable → we pass SQL command from a variable.
Note: this variable generally recommended at the time of dynamic retrieval of data.
OLEDB Destination Additional properties
Data access mode:
i) Table or view
ii) Table or view-fast load → it loads the data very fast compared to normal view or table loading.
During the fast load there are couples of options we must select according to the situation.
- Keep identity
- Keep nulls
- Table Lock
- Check Constraints
Rows per batch 1000
Keep identify uses identity columns generated values.
Note: This fast load option is useful when the table is having clustered index.
iii) Table name or view name-fast load
iv) SQL command.
Question: In data accessing mode after selecting table or view option and clicking new button to create a table, then when does the table will be created.
Sol: After writing changes
Immediately table created (but not at execution time)
SSIS Expressions
1) Write expression when they are small because too many expressions and complex expressions decrease the performance.
2) Generally we use expressions in various places.
- Precedence constraints
- Variables
- For loop
- Connection string in the connection manager
- Derived column transformation
- Conditional split
As part of expressions there are many functions, typecasts and operators available.
Mathematical function: [Mathematical operations on numerical values]
ABS, CEILING, EXP, FLOOR, LOG, LN, POWER, ROUND, SIGN, SQUARE, SQRT.. etc.
Eg: Round (4.82) → 5 ABS (4.82) → 5 ceiling (4.82) → 5
Round (4.26) → 4 ABS (-3.92) →4 floor (4.82) → 4
String Function: [Manipulates string columns/expressions.]
LENGTH, LOWER, LTRIM, REPLACE, CODEPOINT, FINDSTRING, HEX, REPLICATE, REVERSE, RIGHT, SUBSTRING,….etc.
Eg: LOWER (“ABC”) →abc
LTRIM (“abc”) → abc
–> It removes the space.
TRIM(“abc”) →abc
REVERSE (“abc”) → cba
FIND STRING (“VINNNAY”,”N”, 3) → 5 [3rd position]
REPLICATE (“a”, 3) → aaa
REPLACE (“VINAY”, ”Na”, “NNa”)
→ VINNAY
SUBSTRING (“VINAY”, 2, 2) 2
2 point string length 2 → ”IN”
FIND STRING (“VINAY”, N) →
Date/Time function: [To work with day, month, year etc.. In date expressions]
DATE ADD, DATE DIFF, DATE PART, DAY, GETDATE, GETUTCDATE → (universal time coordinate), MONTH, YEAR
DAY (DT-DATE) “2011-09-04” –> 04
MONTH (DT-DATE) “2010-09-04” –> 09
DATE ADD (“MONTH”, 4, (DT-DATE) “2010-05-04”) –> 2010-09-04.
DATE ADD (“MONTH”, 4, JDATE)
DATE DIFF (“MONTH”, (DT-DATE)”2011-07-09”, (DT-DATE)”2011-04-09”)
03months
“DAY” → 90 days
“YEAR” → 0 years
Null functions: [validate null argument]
a) Is null (expression) –> result/true or false
b) Null (DT-DATE) –> null [useful to display “null date” value]
Type cast: [convert one data type of other data type.]
- DT-I4 (column or expression)
- (DT-STR, “length”, “codepage”) (column or expression)
- (DT-WSTR(Wide), “length”) (col. or exp.)
- (DT-numeric, precision, scale) (“)
Eg: (DT-Numeric,2,6) (123456)à1234.56.
Operator:
&&———–logical AND
||————logical OR
?: –> writing if condition
?:
Eg: is null (party name)? “unknown:” TRIM (party name)
Display expression if date is null or the date length is zero or the date is having null date, display null otherwise display date.
IS NULL (JDATE)||len (trim((DT-WSTR,10)JDATE))==0||JDATE==”00-00-0000”? NULL(DT-DATE):JDATE
List: ADD, concatenates (+), subtract, Negate, Multiply, Divide, modulo (%), parentheses ([]), equal (==), Unequal (!=), Greater (>)..etc
- Display an expression where the file name should be appeared with the current time stamp in this format.
FILENAME-YYYY-MM-DD-HHMMSS.TXT
CDATEà”2011-08-09 04:23:22:00000
“File Name-“+
Substring ((DT-WSTR, 30) CDATE, 1, 10) +”-“+
Substring ((DT-WSTR, 30) CDATE, 12, 2) +
Substring ((DT-WSTR, 30) CDATE, 15, 2) +
Substring ((DT-WSTR, 30) CDATE, 18, 2) +”.TXT
Note:
Fast load option is useful when the table is having clustered index.
In case sorted input sources:
.png&w=16&q=75)
0 –> Un sorted
1 –> Sorted
- Take 2 flat files and assign locations
- Go to each flat file –> Rt click –> show advanced editor
- Input and output properties –> flat file source output
- Is sorted: true
Output columns –> party ID –> data types: change DT-I4 sort key position:1
Flat file source error output –> is sorted: true
Output column –> flat file source error output column sort key option: 1 ok –>ok
Note: merge works with two source at a time
Different between merge and union all
Merge Union all
Only two sources No limit
Input should be sorted Not applicable
Sorted result Not applicable
Merge join:
It performs merge operation along with joins. Generally it supports the below joins.
a) Inner join
b) Left join
c) Full join
Emp table
DID DNAME NULL
10 IT ?
40 HR ?
Dept Table
EID ENAME DID
1 A 10
2 B 20
Query structure:
Select cols/* from cross join no where condition.
Inner join
ON
Left join
ON
Right join < Table B >ON
Full outer join
ON
Eg: select E.EID, E.ENAME, E.EID, D.DID, D.DNAME from EMP E
Cross join dept D
Inner join dept D ON E.EID=D.DID
Left outer join dept D ON E.EID=D.DID
Right outer join dept D ON E.EID=D.DID
Full outer join dept D ON E.EID=D.DID
Output:
.PNG&w=16&q=75)
Cache creation:
OLEDB source [Dept Table]
↑↓
Cache transformation –> RC –> edit –> cache connection manager new –> connection mgr name; Dept cache
- Use file cache
Browse –> Output folder –> DBP _cache .CAW –> columns –> DEPT ID –> index position –> ok –> ok –> run(Package and see cache generate)
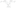
–> Merge join –> rt click –> merge join transformation editor –> join type: left outer join
Look up transformation:
It look up the required values on target and fetches relevant result. [Exact result]
Real time usage:
- To fetch relevant value
- While working with SCDs [slowly changing dimension]
- To have exact match with destination and to improve query retrieval fast (it uses caches)
Types of caches:
- Full cache
- No cache
- Partial cache
No cache:
Here there is no cache to the target table. So every time source query hits the database and fetches the result.
Advantage:
If the source data changing frequently and less no.of records are there it is recommended.
.png&w=16&q=75)
Draw backs:
1. Hits on the target increases and traffic also high.
Full cache: Here there is a cache for the target table, so every source request goes to the cache and fetches the data.
.png&w=16&q=75)
Adv:
If the target is not changed and having more records.
Partial cache:
Initially the cache is empty for every new request source query hits the database and fetches the information to the cache. For existing records, source query hits the cache.
Adv:
More and more new records are added to the destination there is huge usage in existing records as well.
Look up result:
If there is no match in the look up we can go for either of the below (ways) options.
a) Ignore failure
b) Redirect rows to error output
c) Fail component
d) Redirect rows to no match O/P.
If the source is having multiple matches in the destination it returns “First Match”
Lookup performance improvement:
a) Increase or decrease the cache memory according to the target table size, because more rows with the big size cache gives bad performance.
b) Instead of taking table, take an SQL query to have required no.of rows and columns in the cache and to perform lookup operations.
Lookup –> rt click –> edit –> connection –> mark use results of an SQL query option and write this type of customized query.
“SELECT DEPT ID, DEPT NAME From DEPT where DEPT ID in [10,20]”
Eg: Retrieving the dept id, name from dept (using full cache) table based on the match from emp table.
Matched records in one destination and
Unmatched records to another destination.
Sol: a) OLEDB source (Emp table)
b) Lookup –> Rc –> Edit –> general select full cache
.png&w=16&q=75)
Specify how to handle rows with no matching entries i.e., redirect rows to no match output
Connection
OLEDB connection manager:
DB-MSBI
Use table or view:
Columns
Connect DID from EMP to DEPT and select DID, DName from Dept.
Ok
Take two destinations and connect matched result to one destination and unmatched result to another destination.
Note:
a) Unmatched result destination structure is like source table only and it contains source unmatched records.
b) Lookup operations we can perform only on relational tables (we can’t perform on flat files)
Working with partial cache:
In the above steps do the below changes
.png&w=16&q=75)
Navigation:
Lookup –> Rc –> Edit –>
General
Select partial cache.
Advanced
Take required amount of memory if required enable the cache for no matching entries options.
Note: the cache created and dropped automatically
Creating the named cache:
- This cache is shareable across multiple packages.
- This is recommendable if the lookup table data is not changed such as a long time.
.png&w=16&q=75)
Navigation:
Start –> programs –> open BIDS –> New –>Project –> package –>control flow task –> data flow task –> Drag or select the OLEDB source –> cache transform –> steps page no 340)
Using the preached or named cache for operations:
To do the named cache operations, take some changes in the “lookup” i.e.,
Navigation: lookup –> rt click –> edit –> lookup editor
.png&w=16&q=75)
Properties –> general
Cache mode: Select full cache
Connection type: Cache connection manager
–> Specify how to handle rows with no matching entries Redirect rows to no match output.
Go to connection:
Cache connection manager –> new –> name –>
Check use cache file name
Ok
Ok
Check columns, ok, ok
Fuzzy lookup transformation:
This transformation is designed to get the result from the destination based on the similarity but not exact match.
While doing the operation three more columns added for destination.
a) similarity:
It displays how much similar source row with destination row. (Column)
b) similarity-column name:
It display how much similar each source column with each destination column.
c) confidence:
How much the system is having confidence to give the result?
Note: generally we go for similarities for string values.
Eg:
.PNG&w=16&q=75)
EMP – ADDRESS TABLE
EID ENAME
1 Madhu Mohan
2 Vinay Krishna
8 Rajesh Yadav
5 Ramana
6 Murali Mohan
.png&w=16&q=75)
Navigation:
Fuzzy lookup:
- Take OLEDB source as emp.
- Fuzzy lookupàrt click àedità
Reference table
OLEDB connection manager: DB-MSBI
Table or view: Emp-address
Columns:
Connect ename from Emp to Ename in Emp-address and select EName and E-address columns from Emp-add
Ok Ok.
.PNG&w=16&q=75)
4. Take two destinations and connect each condition.
5. Run package.
Pivot transformation:
- It converts rows information into columns.
- It creates less normalization of data.
.PNG&w=16&q=75)
Un pivoted column:
It doesn’t participate in pivoting.
Pivoted columns:
Columns values which are converted from rows to columns.
Pivoted value: the values which are moved to pivoted columns.
Column name Pivoted key usage
Party ID 1àun pivoted
SAL component 2àpivoted columns
SAL amount 3àpivoted values
Lineage ID:
It is a unique ID taken by a system for every column which is mapped.
.png&w=16&q=75)
Navigation:
- Take pivot-SRC as source
- Pivot –> rt click –> edit –>
Input columns: select all columns
Input output properties:
Pivot default input:
Do the below settings
Party ID –> pivot usage –> 1
SAL component –> pivot usage –> 2
SAL amount –> pivot usage –> 3
Note:
Identify lineage ids of party ID, sal component, sal amount
Eg:
Column name lineage id
Party id 349
Sal component 371
Sal amount 375
Pivot default O/P:
- Click add columns –> Rename column to party ID –> Go to properties and set
- Pivot key value: party ID, source column: 349
- Click add columns –> Rename column to HRS –> Go to properties and set
- Pivot key value: HRA, source column: 375
- Click add columns –> Rename column to TA –> Go to properties and set
- Pivot key value: TA, source column: 375
- Click add columns –> Rename column to DA –> Go to properties and set
- Pivot key value: DA, source column: 375
Audit:
It display audit information for every row coming from source or it adds audit information to the source data.
Eg: Audit types:
- Execution instance GUID
- Package ID
- Package name
- Version ID
- Execution start time
- m/c name
- User name
- Task name
- Task ID
Character map:
It applies string operations such as lower to upper and vice versa etc.
Copy column:
It creates multiple copies of the column.
Export column:
It export column value from rows in data set to a file.
Eg: exporting, image from column to a file.
Import column:
It imports in to column, values from a file
Eg: loading images from file to table rows.
Fuzzy grouping:
It groups similar rows.
OLEDB command:
It executes an SQL command for each row in a data set.
Percentage sampling:
It takes sample percentage no.of rows from source data set.
Eg: taking 20% of sample rows from a dataset.
Row sampling:
It display the specified no.of sampled rows.
Eg: display 10,000 sample rows from a table.
Row count:
It count the no.of rows in dataset.
Un pivot:
It converts columns information iTerm lookup:nto rows i.e, it creates move a normalized representation of dataset.
Script component:
It executes a customs script (VB.Net) or (C#.Net)
Term extraction:
It extracts terms from a data to column.
It counts the frequencies that terms in a reference table appears in a dataset.
List of Related Microsoft Certification Courses:
| SSRS | Power BI |
| SSAS | SQL Server |
| SCCM | SQL Server DBA |
| SharePoint | BizTalk Server |
| Team Foundation Server | BizTalk Server Administrator |
 On-Job Support Service
On-Job Support Service
Online Work Support for your on-job roles.

Our work-support plans provide precise options as per your project tasks. Whether you are a newbie or an experienced professional seeking assistance in completing project tasks, we are here with the following plans to meet your custom needs:
- Pay Per Hour
- Pay Per Week
- Monthly
| Name | Dates | |
|---|---|---|
| MSBI Training | Jul 18 to Aug 02 | View Details |
| MSBI Training | Jul 21 to Aug 05 | View Details |
| MSBI Training | Jul 25 to Aug 09 | View Details |
| MSBI Training | Jul 28 to Aug 12 | View Details |

As a content writer and storyteller, Raunaak Mitra regards himself to be a prodigy in writing. He firmly believes that language is borderless, and anyone can write as long as they have a strong narrative capability and the ability to emote feelings into words. Authors like F. Scott Fitzgerald and R. K. Narayan have influenced him to keep the writing as simple as possible for anyone to understand. Other than being well-versed about technological trends like AI, Machine Learning, AR, VR, Gaming, Microprocessors, Cloud Computing, Industry 4.0, literally any technological advancement (old or new), he also shares a knack to curate fiction on sci-fi, satire, and thriller genres.














