- Home
- Blog
- Microsoft Azure
- Azure Machine Learning

- Azure Active Directory
- Azure Active Directory B2C
- Azure Active Directory Domain Services
- Azure Analysis Services
- Azure App Services
- What is Azure Application Insights?
- Azure Arc
- Azure Automation - Benefits and Special Features
- A Complete Guide On Microsoft Azure Batch
- Azure Cognitive Services
- Azure Data Catalog
- Azure Data Factory - Data Processing Services
- Microsoft Azure Data Factory Tutorial (2024)
- Everything You Need To Know About Azure Data Lake
- Azure DNS - Azure Domain Name System
- Azure ExpressRoute
- Azure Functions - Serverless Compute
- Azure Interview Questions and Answers (2024)
- Azure IoT Edge Overview
- Azure IoT Hub
- What Is Azure Key Vault??
- Azure Load Balancer
- Azure Logic Apps - The Lego Bricks to Serverless Architecture
- Microsoft Azure Media Services
- Azure Monitor
- Introduction To Azure SaaS
- Azure Security Center
- Azure Service Bus
- Overview of Azure Service Fabric
- Azure Site Recovery
- Azure SQL Data Warehouse
- Azure Stack - Cloud Services
- Azure Stream Analytics
- Azure Virtual Machine
- Azure’s Public Cloud
- Microsoft Azure Application Gateway
- Microsoft Azure Certification Path
- Microsoft Azure - Exactly What You Are Looking For!
- Microsoft Azure Fabric Interview Questions
- HDInsight Of Azure
- IS Microsoft Azure Help To Grow?
- Microsoft Azure Portal
- Microsoft Azure Traffic Manager
- Microsoft Azure Tutorial
- Overview of Azure Logic Apps
- Top 10 Reasons Why You Should Learn Azure And Get Certified
- Server-Less Architecture In Azure
- What is Microsoft Azure
- Why Azure Machine Learning?
- Azure DevOps Interview Questions
- Azure Active Directory Interview Questions
- Azure DevOps vs Jira
- What is Azure Service Fabric
- What is Azure Databricks?
- Azure Databricks Interview Questions
- Azure Data Factory Interview Questions
- Azure Architect Interview Questions
- Azure Administrator Interview Questions
- Azure Data Studio vs SSMS
- Microsoft Interview Questions
- What is Azure Data Studio - How to Install Azure Data Studio?
- Azure DevOps Projects and Use Cases
- Azure Data Factory (ADF) Integration Runtime
- Azure DevOps Delivery Plans
- Azure DevOps Variables
- Azure DevOps vs GitHub
- Azure DevOps Pipeline
- Microsoft Azure Services
This technological world is shifting towards technologies like artificial intelligence, IoT, machine learning and deep learning. The fourth industrial revolution which has combined the concept of a machine with the power of intelligence is providing our successful results in terms of modern automated chatbots, voice and text-enabled searches, face recognition, and many more valuable products.
Well, these products are the outcome of the complex machine learning and deep learning algorithms used to develop such data-oriented models. After the introduction of cloud computing where a user can leverage virtual resources such as infrastructure, storage, networking, testing platform, etc., the development of such applications has increased. Azure machine learning is one such cloud-enabled service that is being used for training, deploying, managing, and automating machine learning (ML) models at a massive scale. Let’s explore it in this Azure Machine Learning article.
If you would like to Enrich your career with a Microsoft Azure certified professional, then visit Mindmajix - A Global online training platform: “Azure Training” Course. This course will help you to achieve excellence in this domain.
What is Azure Public cloud?
Microsoft Azure, which is also known as Windows Azure, is Microsoft’s public cloud computing platform developed for providing varieties of cloud services. These services include the platform for computation, networking, storage, analytics, IoT, and Artificial Intelligence application development. One can easily go with the service of their choice and create a scalable application, test, and deploy it. And, the best part is, you will only pay for what you use.

What is Machine Learning?
Machine learning technology refers to the various techniques used to train existing data for fetching valuable insights from it. By leveraging ML models and provided data, we can predict future behaviors, trends, and outcomes. The ML algorithms have the ability to learn without being explicitly programmed.
With ML-based predictions, you can make your application or devices much smarter serving you the best from it. For example, you may have observed the recommendations while shopping online. Yes, these recommendation engines are empowered by complex ML algorithms. One more example of ML can be seen in making transactions through credit or debit cards where these ML models compare the information through a transaction database for identifying fraudulent transactions.
Well, you must be wondering how these models can provide accurate outcomes. Let’s understand it with the Azure ML services which will help you provide a crystal clear view of ML model development and deployment.
Azure Machine Learning Services
Azure machine learning services allow you to create, test, manage, deploy, migrate, or monitor ML models in a scalable cloud-based environment. Azure machine learning services support thousands of open-source packages available in Python such as TensorFlow and Matplotlib. The supported ML tools make it easy to explore, transform, create, and test data models. E.g., Azure Machine Learning for Visual Studio Code and Jupyter notebooks. Azure ML services assist us with automated model generation and tuning to develop efficient and accurate models.
The best part about Azure ML service - you can train your model over the local machine and then deploy it on the cloud. Azure offers computing services like Azure Databricks, Azure Machine Learning Compute, and advanced hyperparameter tuning services allowing you to create better models.
Once you have created the right model, it’s time to deploy it over containers like Docker which makes it easy to deploy it to Azure Kubernetes Service or Azure Container Instances.
You can take care of deployed models and monitor various executions to get the best outcome. Once it is deployed, you will get asynchronous predictions (real-time) on a massive amount of data.
The advanced machine learning pipelines make a collaborative environment in all steps, including data preparation for deployment.
Also Read: Why Azure Machine Learning?
What you can do with the Azure Machine learning Service?
Azure machine learning service has the potential to auto-train and autotune a model. The Azure machine learning software development kit (SDK) available for Python and open-source packages allows us to create and train accurate deep learning and ML models in an Azure machine learning service workspace. Various ML components can be accessed through Python packages like Scikit-learn, PyTorch, MXNet, TensorFlow, Microsoft Cognitive Toolkit (CNTK), etc.
After creating the model, you need to create a container like Docker which should be tested locally. Once tested successfully, you can deploy it as a web service using Azure Kubernetes service or Azure Container service. Now, the Azure portal or Azure Machine Learning SDK for Python will assist you to manage the deployed web model. It will help you to evaluate model metrics, redeployment of modified versions, and model tracking simultaneously.
Azure Machine Learning Service: Architecture and Concepts :
The key components of the Azure Machine Learning Service along with workflow are described in the below figure:
The Azure machine learning service works as follows -
- Create your machine learning training program in Python and then configure a Compute Target.
- Put the program in the computed target for executing it in this environment. At the time of training, the program can be read from datastore or written in datastore. The running records are stored as runs inside the workspace. They are grouped inside experiments.
- Make a query to the experiments. It is done for logged metrics obtained from the present and past executions. If the desired output is not obtained from the metrics then iterate all the steps from the beginning of the first step. And, if the obtained outcome is relevant, register your model. It is done inside the model registry.
- Create a scoring program.
- Create an image. Register this image in the image registry.
- Finally, deploy this image in Azure. It is deployed as a web service.
Workspace :
The workspace represents the topmost level centralized resource of the Azure Machine Learning service. It allows you to create all the artifacts for your work. It holds the list of all computing targets used for the training-developed model. It also stores the log of training execution, metrics, snapshots, and outputs. This data will assist you in choosing the best training model for your work.
The model is registered through the workspace. This registered model and scoring script is used for making an image. This image is deployed as a REST-service-based HTTP endpoint. You can use Azure Container Instances, Field-programmable gate array (FPGA), or Azure Kubernetes Service for the deployment. You can also deploy this image over the Azure IoT Edge device where it is deployed as a module.
You can take advantage of multiple workspaces sharing each of them among your team members. You can assign multiple roles to the users such as Owners, Readers, or Contributors.
A newly created workspace automatically creates all useful Azure resources such as:
- Azure storage account: a default datastore.
- Azure Container Registry: a docker registered container, and it is used while training during deployment of your model.
- Azure Key Vault: keeps keys used by computing targets and various other useful information accesses.
- Azure Application Insights: keeps monitoring data from your model.
Model:
A model is the code script that takes input and avails output. While developing a machine learning model, it requires the selection of algorithms, availing data to it, and tuning of hyperparameters. Training involves an iterative process which provides a trained model inheriting what it learned from the training process.
A model is obtained by executing in Azure Machine Learning. If you have created your model by training it outside, don’t worry, you can still use it in Azure Machine Learning. All it requires is registering it in the Azure Machine Learning service workspace.
Model Registry:
A model registry is responsible for keeping records. It was recorded from all the models of your Azure Machine Learning service workspace. You can recognize a model by its version and name. Every time you register a model with the name which has been already being used before, the registry stores it as a new version. The version is increased and the name of the model remains the same.
You can also put additional metadata tags during the registration of your model. It helps you with search it through that tag. Always remember that suppose if a model is getting used by the image then it can’t be deleted.
Image:
The image provides an environment to deploy your model independently. It has all the components required by the model. An image contains a model, application or a script (this script is provided as an input to the model which returns an output), dependencies required by your model or script.
Azure machine learning has two types of images- FPGA image and Docker image.
An FPGA image is used while deploying a field-programmable gate array in Azure ML while Docker image is used to deploy computer targets such as Azure Kubernetes Service or Azure Container Instances.
Image registry:
An image registry holds a record of images created by your models. It avails additional metadata tags while creating an image. The metadata tags are kept by an image registry. These tags can be used as a query to find your image.
Deployment:
A Deployment instantiates your image into a web service which is further hosted over the cloud. Also, it can instantiate an image into an IoT module for using it in an integrated device deployment.
Web Service:
The web service deployed over the cloud can use either Azure Kubernetes service or Azure Container Instances or FPGAs. You can create a service from your image which keeps your model, program, and other necessary files. The image provides HTTP endpoints for establishing a connection to send or receive requests to the web service and load balancers.
Azure avails valuable application insights so that you can monitor your deployed web service through model telemetry. All you need is to choose this feature. The insights data collected from telemetry are kept inside storage account instances and are only authorized to you. You can also add an automatic scaling feature to scale up and scale down your deployment.
IoT module:
IoT module is a Docker container that keeps your model, program/ application, and various other dependencies. These modules are deployed on edge devices with the help of Azure IoT Edge.
If you’ve selected a monitoring feature then Azure will gather all telemetry information from the models. This model lies inside the Azure IoT Edge module. This data can be easily accessed inside the storage account instance. The execution of the module is taken care of by Azure IoT Edge. The main device which hosts your model is also monitored by it.
Datastore:
A datastore provides a storage abstraction for your Azure account. It leverages the Azure file share and Azure blob container to keep the data. Each workspace keeps a default datastore. Here, you can register other data stores on demand. To access this information, you need the Python SDK API. You can also use Azure Machine Learning CLI to retrieve files from here.
Run:
A run record keeps information like metadata about execution such as timestamp, duration, etc., metrics logged by your program and output files which are automatically collected by the experiment. Run is produced when you provide a program file for training your model. A run contains zero or more child runs. E.g., a top-level run can have two child runs, all of them having their own run as a child.
Experiment:
The experiment contains various runs from a particular program. It is available in a workspace. Every time you provide a run, you have to give an experiment name. All the run data are stored in an experiment. Suppose if you submit a run and you provide an experiment with a name that doesn’t exist, it automatically creates a new experiment with the provided name.
Pipeline :
A machine learning pipeline is responsible for creating and directing workflow involved in machine learning phases. E.g., a pipeline provides data preparation, deployment, training of your model, and inferencing tasks. Each phase in the pipeline contains various steps; all of them run independently in multiple compute targets.
Compute Target:
It is a computing resource that is used while executing your training program or hosting service during deployment.
Compute targets are associated with a workspace. Compute targets apart from the local machine is shared among workspace users.
Managed and unmanaged compute targets:
Managed compute targets are the ones managed and created by Azure Machine Learning service. They are optimized to handle workloads. Through the Azure portal, Azure Machine Learning SDK or Azure CLI, you can easily develop a machine learning compute instance in a workspace. Other compute targets must be developed outside of the workspace after that they are attached to it.
The compute targets which are not managed by Azure Machine Learning service are called unmanaged compute targets. They are created outside and attached to the workspace for further use in the Azure Machine Learning service. It requires extra steps for maintaining or enhancing their performance to handle ML workloads.
Run configuration:
It keeps the instruction set to specify your program execution in a compute target. It contains a long set of behavior definitions like which environment to use while building specifications from Python or Conda. It is persistent in a directory which includes the training program.
Training script:
It requires a directory for training scripts and other related files while training your model. You need to provide an experiment name for keeping data collected during training. The whole directory is cloned to the training environment during the training process. The script named by run configuration is executed in the beginning. Finally, a directory snapshot is kept under the workspace of the experiment.
Logging:
The Azure Machine Learning Python SDK is used for collecting log metrics. After execution, you can make queries to identify which run was obtained during deployment.
Snapshot:
When the run is provided, the Azure Machine Learning compresses the directory containing the script. This zip file is then sent to the compute target where it is extracted and executed. Azure Machine Learning keeps this file as a snapshot to avail you with the run record. You can easily download this snapshot which is accessible in a run record.
Activity:
Activity points towards the long-running operations such as creation or deletion of computing targets, execution of a script over the compute target, etc. It provides notifications through SDK which helps you to easily monitor operational progresses.
Managing, Deploying and Monitoring Models
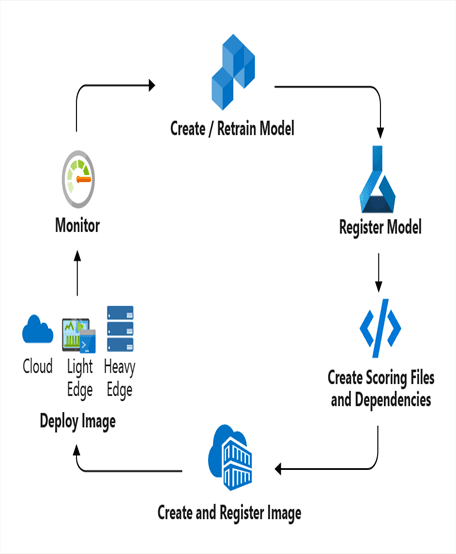
Now, I’ll tell you how Azure Machine Learning service is used to deploy, manage, and monitor your machine learning model. You can deploy your developed and trained ML model over a local machine or any other source. The below diagram represents the whole deployment workflow :
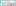
The deployment process involves the following phases :
- Registering the model in a registry hosted over Azure Machine Learning service workspace.
- Register an image into a portable container. The image pairs a model with the scoring script and other associated dependencies.
- Deploy the image over a cloud web service. Or, it can be edge devices as well where the image should be deployed.
- After deployment, monitor and gather data.
- Finally, update a deployment that can be used for a new image.
All the steps involved are performed independently. You can also integrate the deployment with an I/CD workflow as you can see in the below picture.
Step 1: Register your model
During model registration, the version is provided to your model and it is kept inside the workspace of the Azure cloud. By registering a model, you can easily manage and track your trained models. The registered model can be recognized with the help of its name and version.
The model version is auto-incremented while registering a model with the same name. Like I said before, model registration involves the additional metadata tags which are used for finding your model.
The model which is used by an image can’t be deleted at the same time.
Step 2: Image register
An image is responsible for easy and reliable model deployment. It also provides all the necessary components for your model. It comprises a model, scoring engine, scoring file or an application, and other dependencies required by your model.
The image also contains the SDK components which are used in logging and monitoring of your model. The SDK logs information is very useful in various ways. It helps in fine-tuning or retraining your model including input and output.
Once your workspace is created, many resources are used by it. All the objects that participated in the image creation are kept in the Azure storage account of your workspace.
The code for creating and registering your image in Python is given below:
From azureml.core.image import Container Image
# Image configuration
image_config = ContainerImage.image_configuration(execution_script = "score.py",
runtime = "python",
conda_file = "myenv.yml",
description = "Ridge regression model image",
tags = {"data": "diabetes", "type": "regression"}
)
Time estimate: Approximately 10 seconds.
The key parameters used in the above example are explained below in this table :
| Parameter | Description |
| execution_script | Shows a Python script that is used to get requests provided to the service. In the given example, the script is kept in the score.py file. |
| runtime | Points towards the image using Python. Another option is spark-py, which leverages Python with Apache Spark. |
| conda_file | Used for availing a Conda environment file. This file includes the conda environment for the deployed model. |
# Register the image from the image configuration
image = ContainerImage.create(name = "myimage",
models = [model], #this is the model object
image_config = image_config,
workspace = ws
)
Step 3: Deploy image
The registered images are deployed over the cloud or edge devices. All the resources required for monitoring, auto-scaling and load balancing are created during deployment of your model. A certificate enabled authentication is provided to keep deployed services secure during the deployment. It also allows you to upgrade the old deployment so that it can leverage a new image.
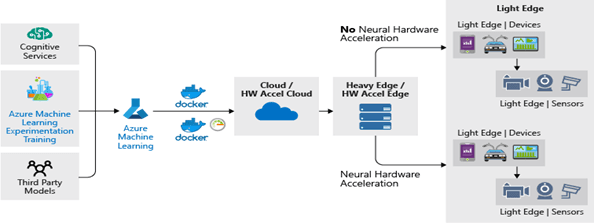
If you are planning to deploy your image over the cloud, you may use the following deployment targets:
- Azure Container Instance
- Azure Kubernetes Service
- Azure FPGA machines
- Azure IoT Edge devices
As you are deploying your service over the cloud, the inferencing requests are load-balanced and scaled as per demand automatically. The telemetry from your model can be collected inside the Azure Application Insights service.
For deploying it to an Azure Container Instance, go through the following steps:
Specify the deployment configuration.
from azureml.core.webservice import AciWebservice
aciconfig = AciWebservice.deploy_configuration(cpu_cores = 1,
memory_gb = 1,
tags = {"data": "mnist", "type": "classification"},
description = 'Handwriting recognition')For image deployment which is created above, use below-defined code:
from azureml.core.webservice import Webservice
service_name = 'aci-mnist-13'
service = Webservice.deploy_from_image(deployment_config = aciconfig,
image = image,
name = service_name,
workspace = ws)
service.wait_for_deployment(show_output = True)
print(service.state)
For deployment in Azure Kubernetes Cluster:
from azureml.core.compute import AksCompute, ComputeTarget
# Use the default configuration (you can also provide parameters to customize this)
prov_config = AksCompute.provisioning_configuration()
aks_name = 'aml-aks-1'
# Create the cluster
aks_target = ComputeTarget.create(workspace = ws,
name = aks_name,
provisioning_configuration = prov_config)
# Wait for the create process to complete
aks_target.wait_for_completion(show_output = True)
print(aks_target.provisioning_state)
print(aks_target.provisioning_errors)
Deploy your model in Azure Kubernetes service using this code:
from azureml.core.webservice import Webservice, AksWebservice
# Set configuration and service name
aks_config = AksWebservice.deploy_configuration()
aks_service_name ='aks-service-1'
# Deploy from image
service = Webservice.deploy_from_image(workspace = ws,
name = aks_service_name,
image = image,
deployment_config = aks_config,
deployment_target = aks_target)
# Wait for the deployment to complete
service.wait_for_deployment(show_output = True)
print(service.stateFor deployment over FPGA use below written code
from azureml.core import Workspace
ws = Workspace.from_config()
print(ws.name, ws.resource_group, ws.location, ws.subscription_id, sep = 'n')
from azureml.core.model import Model
model_name = "resnet-50-rtai"
registered_model = Model.register(ws, model_def_path, model_name)
from azureml.core.webservice import Webservice
from azureml.exceptions import WebserviceException
from azureml.contrib.brainwave import BrainwaveWebservice, BrainwaveImage
service_name = "imagenet-infer"
service = None
try:
service = Webservice(ws, service_name)
except WebserviceException:
image_config = BrainwaveImage.image_configuration()
deployment_config = BrainwaveWebservice.deploy_configuration()
service = Webservice.deploy_from_model(ws, service_name, [registered_model], image_config, deployment_config)
service.wait_for_deployment(True)For deployment over an IoT edge, use
# Getting your container details
container_reg = ws.get_details()["containerRegistry"]
reg_name=container_reg.split("/")[-1]
container_url = """ + image.image_location + "","
subscription_id = ws.subscription_id
from azure.mgmt.containerregistry import ContainerRegistryManagementClient
from azure.mgmt import containerregistry
client = ContainerRegistryManagementClient(ws._auth,subscription_id)
result= client.registries.list_credentials(resource_group_name, reg_name, custom_headers=None, raw=False)
username = result.username
password = result.passwords[0].value
print('ContainerURL{}'.format(image.image_location))
print('Servername: {}'.format(reg_name))
print('Username: {}'.format(username))
print('Password: {}'.format(password))//deployment of the model
wget https://raw.githubusercontent.com/Azure/ai-toolkit-iot-edge/master/amliotedge/deploymodel
sudo chmod +x deploymodel
sudo ./deploymodel <ContainerRegistryName> <username> <password> <imageLocationURL> <DeploymentID> <IoTHubname> <DeviceID>
Step 4: Monitor models and collect data
For monitoring input, output, and other sensitive information, you can use an SDK available for model logging and data capture. The information is kept as a blob in your Azure Storage account. You have to import the SDK inside the scoring script or your application form using the SDK. After importing it, you can use it to log information like parameters, outputs or input details.
Once you have enabled the model data collection during the image deployment, the information provided for collecting data such as your personal blob store authentication keys, logs, etc., is provisioned automatically.
Use the following code for testing
import json
test_sample = json.dumps({'data': [
[1,2,3,4,5,6,7,8,9,10],
[10,9,8,7,6,5,4,3,2,1]
]})
test_sample = bytes(test_sample,encoding = 'utf8')
prediction = service.run(input_data = test_sample)
print(predictionStep 5: Update the deployment
The updates introduced to your model have not registered automatically. Just like updates, new image registration doesn’t automatically update deployments which were formed in the last image version. You have to manually register for the image and model, and then finally update the model. For updating, use the following code.
from azureml.core.webservice import Webservice
from azureml.core.image import Image
service_name = 'aci-mnist-3'
# Retrieve existing service
service = Webservice(name = service_name, workspace = ws)
# point to a different image
new_image = Image(workspace = ws, id="myimage2:1")
# Update the image used by the service
service.update(image = new_image)
print(service.state)
Now, troubleshoot using
import logging
logging.basicConfig(level=logging.DEBUG)
Dealing with the JSON data
The below-written code accepts and returns the JSON data. Here, the run function is responsible for the transformation of data from JSON format to the model expected data and the transformation of response again to the JSON before finally returning it.
# import things required by this script
import json
import numpy as np
import os
import pickle
from sklearn.externals import joblib
from sklearn.linear_model import LogisticRegression
from azureml.core.model import Model
# load the model
def init():
global model
# retrieve the path to the model file using the model name
model_path = Model.get_model_path('sklearn_mnist')
model = joblib.load(model_path)
# Passes data to the model and returns the prediction
def run(raw_data):
data = np.array(json.loads(raw_data)['data'])
# make prediction
y_hat = model.predict(data)
return json.dumps(y_hat.tolist())
What are FPGAs?
FPGA is pronounced as field-programmable gate arrays. FPGA comprises an array of programmable logic blocks with a hierarchy of reconfigurable interconnects. The interconnects are responsible for allowing these blocks to get configured in multiple ways after their development. Comparing it with the other chips, the FPGAs stand best in providing the programmability and performance combination at the same.
FPGAs vs. CPU, GPU, and ASIC
The below diagram and table provides a clear picture depicting the comparison between FPGAs and other processors. Let’s have a look.

| Processor | Description | |
| Application-specific integrated circuits | ASICs |
|
| Field-programmable gate arrays | FPGAs |
|
| Graphics processing units | GPUs |
|
| Central processing units | CPUs |
|
Microsoft Machine Learning for Apache Spark (MMLSpark)
Since the data generation is expanding at an unstoppable pace, it is compulsory to have a good tool for fetching valuable insights from the big data. The Spark ML library is the best tool for processing big data at a massive scale with machine learning experiments. Data scientists were facing challenges like low-level data manipulation, lack of image processing tools, text analytics, and many more.
Thanks to the Microsoft Machine Learning for Apache Spark (MMLSpark) for providing an awesome environment as it is created on the top of SparkML eliminating the challenges of data science. It includes cool libraries like OpenCV, CNTK, etc., to provide a smooth workflow. With it, one can create models with 1/10th of the written code using pipelines objects. It is a fault-tolerant, RESTful, and elastic ML framework.
The key features of MMLSpark are :
- Bing image search: A rich query-based tool for the visual world on a massive scale.
- Serve terabytes of data through the art of OCR engine and image classifier.
- Text analytics: Know the meaning of your database of free-form text.
- Face recognition: Recognize millions of images with a few lines of handful code.
- Distribute Model Interpretability: Know any image classifier with the help of distributed implementation. It leverages the local interpretable model agnostic explanations (LIME).
- Milliseconds serving: Serve any spark computation in milliseconds through Python, Scala or any other language.
- Scalable Deep Learning: Distributed computation framework through Apache Spark and flexible CNTK allows you to deal with deep learning problems through a scalable environment.
- Distributed Microservices: There are tools available for establishing any of the HTTP endpoint services by using Spark. Spark can be used as an elastic micro service orchestrator.
Installation
Microsoft Machine Learning for Apache Spark (MMLSpark) can be easily installed on existing Spark clusters via the --packages option, such as:
spark-shell --packages Azure:mmlspark:0.14
pyspark --packages Azure:mmlspark:0.14
spark-submit --packages Azure:mmlspark:0.14 MyApp.jarIt can also be used for other Spark contexts such as, use MMLSpark in AZTK through .aztk/sparkdefault.conf file.
For python: install PySpark first with pip install pyspark. Now, use –packages to add runtime package for getting scala sources:
import pyspark
spark = pyspark.sql.SparkSession.builder.appName("MyApp")
.config("spark.jars.packages", "Azure:mmlspark:0.14")
.getOrCreate()
import mmlspark
Visual Studio Code Tools for AI
Visual Studio Code Tools for Artificial Intelligence is an extension that allows you to create, deploy, and test advanced AI and deep learning applications. It combines the Azure Machine Learning potential to avail of a robust experimentation environment where a user can leverage data preparation and training of model along with the multiple computer targets.
In addition, you can take advantage of customized metrics and execute history tracking to streamline your data science reproducibility and auditing work. Companies can collaborate securely on their project work which involves the third party hand in the development of the deployment. You can take benefit of deep learning services through CNTK, Google TensorFlow, and various other advanced deep learning frameworks.
The key features include:
- You can create AI and deep learning applications over Windows and Macintosh VS Code Tools for AI which is a cross-platform extension. It supports the deep learning framework such as Google TensorFlow, Microsoft Cognitive Toolkit (CNTK), and many more.
- Its integrated development environment allows us to use services like syntax highlighting, auto-compilation, and automatic text formatting, making the whole development process easier. It also makes testing easier by allowing you to test and debug the application on local variables and models.
- You can easily browse for the required samples in the gallery. It leverages the sample experiments through CNTK, MMLspark, TensorFlow, etc., so that your model can easily learn and it can be shared among the others.
- You can scale up and scale down the deep learning model training and inference to the cloud. With this extension, you can train your model over your local computer or add jobs over the cloud by integrating it with the Azure Machine Learning. If you have to submit jobs, the various compute targets such as Azure GPU, virtual machines, or spark clusters are the best resources to do so.
Conclusion :
Now, we have a clear idea about how to create, test and deploy a machine learning model over the Azure cloud. You can also leverage the famous ML libraries of Apache Spark which allow us to deal with big data. Now, you know how complex machine learning models like recommendation engines, chatbots, pattern analysis, analytics, BI tools, etc., are developed and deployed over the web. Well, if you are also planning to develop such applications, you should start framing it and test it over the Azure ML service platform. Rest is assured, you will emerge as a big barrel of belief, confidence, and success.
 On-Job Support Service
On-Job Support Service
Online Work Support for your on-job roles.

Our work-support plans provide precise options as per your project tasks. Whether you are a newbie or an experienced professional seeking assistance in completing project tasks, we are here with the following plans to meet your custom needs:
- Pay Per Hour
- Pay Per Week
- Monthly
| Name | Dates | |
|---|---|---|
| Azure Training | Aug 01 to Aug 16 | View Details |
| Azure Training | Aug 04 to Aug 19 | View Details |
| Azure Training | Aug 08 to Aug 23 | View Details |
| Azure Training | Aug 11 to Aug 26 | View Details |

Anji Velagana is working as a Digital Marketing Analyst and Content Contributor for Mindmajix. He writes about various platforms like Servicenow, Business analysis, Performance testing, Mulesoft, Oracle Exadata, Azure, and few other courses. Contact him via anjivelagana@gmail.com and LinkedIn.














