- Home
- Blog
- Microsoft Azure
- What is Azure Databricks?

- Azure Active Directory
- Azure Active Directory B2C
- Azure Active Directory Domain Services
- Azure Analysis Services
- Azure App Services
- What is Azure Application Insights?
- Azure Arc
- Azure Automation - Benefits and Special Features
- A Complete Guide On Microsoft Azure Batch
- Azure Cognitive Services
- Azure Data Catalog
- Azure Data Factory - Data Processing Services
- Microsoft Azure Data Factory Tutorial (2024)
- Everything You Need To Know About Azure Data Lake
- Azure DNS - Azure Domain Name System
- Azure ExpressRoute
- Azure Functions - Serverless Compute
- Azure Interview Questions and Answers (2024)
- Azure IoT Edge Overview
- Azure IoT Hub
- What Is Azure Key Vault??
- Azure Load Balancer
- Azure Logic Apps - The Lego Bricks to Serverless Architecture
- Azure Machine Learning
- Microsoft Azure Media Services
- Azure Monitor
- Introduction To Azure SaaS
- Azure Security Center
- Azure Service Bus
- Overview of Azure Service Fabric
- Azure Site Recovery
- Azure SQL Data Warehouse
- Azure Stack - Cloud Services
- Azure Stream Analytics
- Azure Virtual Machine
- Azure’s Public Cloud
- Microsoft Azure Application Gateway
- Microsoft Azure Certification Path
- Microsoft Azure - Exactly What You Are Looking For!
- Microsoft Azure Fabric Interview Questions
- HDInsight Of Azure
- IS Microsoft Azure Help To Grow?
- Microsoft Azure Portal
- Microsoft Azure Traffic Manager
- Microsoft Azure Tutorial
- Overview of Azure Logic Apps
- Top 10 Reasons Why You Should Learn Azure And Get Certified
- Server-Less Architecture In Azure
- What is Microsoft Azure
- Why Azure Machine Learning?
- Azure DevOps Interview Questions
- Azure Active Directory Interview Questions
- Azure DevOps vs Jira
- What is Azure Service Fabric
- Azure Databricks Interview Questions
- Azure Data Factory Interview Questions
- Azure Architect Interview Questions
- Azure Administrator Interview Questions
- Azure Data Studio vs SSMS
- Microsoft Interview Questions
- What is Azure Data Studio - How to Install Azure Data Studio?
- Azure DevOps Projects and Use Cases
- Azure Data Factory (ADF) Integration Runtime
- Azure DevOps Delivery Plans
- Azure DevOps Variables
- Azure DevOps vs GitHub
- Azure DevOps Pipeline
- Microsoft Azure Services
Big data is all around us and comes from various origins, such as social media platforms, transactional data, and other sources. This data has value when it is handled rapidly and interactively. Apache spark, a version of the spark that has been optimized for use in the cloud, is one of the popular analytics platforms on Microsoft azure.
The Azure data bricks is a platform for big data and machine learning offered as a fully managed service. It was made when the people who made Apache Spark and Microsoft worked together.

| Table of Content: What is Azure Databricks? |
What is Azure Databricks?
Azure Databricks is an analytics platform that uses Apache spark. Azure Databricks maintains and builds cloud infrastructure on your behalf, connecting with your cloud account's storage and security features. Data scientists, engineers, and business analysts can work together using azure data bricks one-click setup, interactive workspace, and optimized workflows to analyze massive amounts of data and extract valuable insights.
Azure Databricks is a managed version of Databricks developed in collaboration with Microsoft that enables quick and easy deployment and collaboration for all Azure users. Data lake store, SQL data warehouse, and HDinsights are some of the azure storage and computing resources that azure data bricks integrate seamlessly.
Due to the enormously scalable processing power of Azure, Azure Databricks enables data engineers to execute large-scale Spark workloads, achieving unmatched speed and cost-efficiency in the cloud with auto-scaling, caching, indexing, and query optimization.
Apache Spark, Delta Lake, and MLflow & Spark are the three companies that laid the groundwork for Databricks. Databricks is a unified processing engine capable of analyzing massive volumes of data using SQL, graph processing, machine learning, and real-time stream analysis.
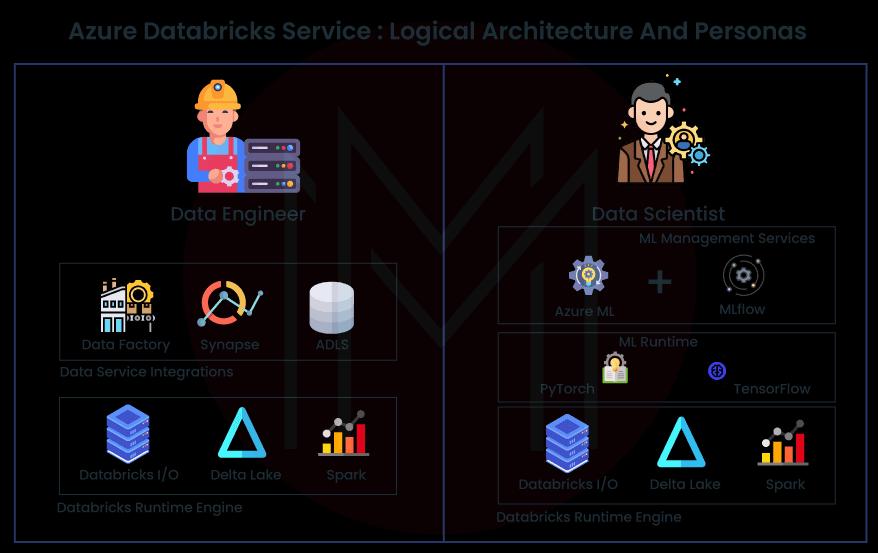
The Databricks runtime engine is at the center of the Azure Databricks architecture. This engine features an optimized Spark offering and Delta Lake and Databricks I/O for an Optimized Data Access Layer engine. Workloads relating to data science can use this core engine's tremendous processing capabilities. Additionally, it offers options for native integration with various data services offered by Azure, such as Azure Data Factory and Synapse Analytics. Additionally, it provides a variety of runtime environments for machine learning, such as Tensorflow and PyTorch. Integrating the notebooks with the MLFlow + Azure Machine Learning service is possible.
| If you want to enrich your career and become a professional in Azure Databricks, then visit Mindmajix - a global online training platform: "Azure Databricks Training" This course will help you to achieve excellence in this domain |
Databricks Introduction
Before we get into the fundamental concepts of databricks, we must have a solid understanding of what databricks are supposed to accomplish overall.
Regarding cloud-based data engineering tools for processing and manipulating enormous amounts of data and examining it using machine learning models, data bricks is at the top of its game. It's the newest big data instrument in Microsoft's Azure cloud and was just released. It's accessible to businesses and helps them see the benefits of integrating their data and machine learning with great effort.
Databricks is a single data and analytics platform for all data personas, including data engineers, analysts, and scientists. Because it is a managed platform, data developers don't have to worry about maintaining databricks libraries, dependencies, clusters, updates, or anything else that isn't directly linked to delivering insights from data; instead, they can focus on data analytics. It functions as a platform that provides data developers with all the resources they require to concentrate on data analytics.
Databricks is already accessible on Azure and AWS, and its availability on GCP was just announced. Databricks' features and components are the same across all three cloud providers, except for the google cloud platform (GCP), which is still under preview. Databricks is a first-party azure service that, like any other azure service, can be provisioned and managed entirely through the azure interface. It also means it works seamlessly with Azure, incorporating azure active directory and the other azure data capabilities right out of the box.
Databricks in Azure
The Microsoft Azure cloud services platform is geared for use with the Azure Databricks data analytics platform. Azure data bricks provides users with the following three environments:
- Databricks SQL
- Databricks data science and engineering
- Databricks machine learning

Azure Databricks's Features
Azure Databricks gives you access to the most recent versions of Apache Spark and makes it possible to integrate without any complications with open-source tools. The following are some Azure databricks features:
- Enhanced Apache Spark infrastructure.
- Designed with deep learning in mind.
- Multiple languages and library support.
- Automatic escalation and deceleration.
- Shared office space for employees to work together.
| Related Article: Azure Administrator Interview Questions |
Advantages of Azure Databricks
Here are some of the Azure databricks advantages that follow below are:
- The best advantage is the deep integration into the Azure subscription.
- It comes equipped with Ganglia for the storage of your Metrics.
- Your cloud-based extract, transform, and load procedure may use Azure data factory as one of its components.
- Databricks supports several languages. Scala is the primary language, although it can also communicate effectively with SQL and R and works well with Python.
- Databricks break down the walls that have previously divided data engineers and data scientists, allowing them to work in tandem on the same piece of code for all of the ELT machine-learning components you may decide to use.
- You can save, retrieve, and update data by integrating with the azure data lake store and blob storage.
- You may set up a cluster using azure DevOps, and you should save your code in a repository for source code. When working with this kind of data in the past, we were often burdened with many administrative responsibilities; however, if you use DevOps, you won't have to worry about those duties. It will allow you to save time.
- Effortlessly combines with your existing active directory.
- There is the possibility of working together in a notebook set. People can leave comments in the margins of the notebook, much like they can do on google docs, and may post those comments in real-time. In addition to it, there is revision control, which stores revisions.
Databricks SQL
With databricks SQL, you have a user-friendly environment. It facilitates the execution of sql queries on the azure data lake, the creation of many virtualizations, and the creation and sharing of dashboards, all of which are helpful tools for analysts.
Data analysts who primarily deal with sql queries and business intelligence tools are the target audience for databricks sql. It makes it easy to create dashboards and execute ad hoc queries on the data stored in your data lake by providing a user-friendly environment. The user interface of this environment is very unlike that of the data science & engineering environment and the databricks machine learning environment. This part discusses the essential ideas you need to comprehend to use databricks sql successfully.
1) Data management in Databricks SQL
- Visualization: Visualization is a graphical representation of the findings from performing a query.
- Dashboard: The presentation of query visualizations and comments is a dashboard.
- Alert: A message when a particular value in a field returned by a query has reached a predetermined limit.
2) Computation management in Data bricks SQL
This section will introduce the necessary principles to understand how to execute SQL queries in Databricks SQL.
- Query: A query that conforms to the standards of SQL.
- SQL warehouse: A compute resource on which SQL queries may be executed is a SQL warehouse.
- Query history: Query history is a collection of queries that have been run together with the performance characteristics of those queries.
3) Databricks runtime in Databricks SQL
The collection of fundamental elements is executed on Azure Databricks' clusters. Azure Databricks provides access to a variety of runtimes, including the following:
- Apache Spark is included in the Databricks Runtime. However, it also contains many other components and improvements that significantly improve big data analytics' speed, usability, and security.
- Databricks Runtime for machine learning is an environment that is already prepared for machine learning and data science. It is built on Databricks Runtime and offers this environment. It has various well-known libraries, including Keras, PyTorch, TensorFlow, and XGBoost.
Databricks Data Science and Engineering
To facilitate collaboration between data scientists, data engineers, and machine learning engineers, Databricks has developed a data science and engineering platform. It is possible to feed information into the significant data pipeline in two ways:
- Import data into Azure in bulk using Azure data factory.
- Use Event Hubs, Apache Kafka, or the IoT Hub for continuous streaming.
Workspace is another name that may refer to the databricks data science & engineering platform. It is a platform for analytics, and Apache spark is its foundation. The databricks data science & engineering platform offers full open-source apache spark cluster capabilities and technologies. Using databricks SQL to operate comprehensive azure-based applications is made possible by integrating with azure active directory. Users of databricks sql are given the ability to uncover and share insights thanks to the platform's integration with Power BI. Here are some features of databricks data science & engineering are:
- Workspace
- Interface
- Data Management
- Computation Management
- Databricks Runtime
- Job
- Model Management
- Authentication and Authorization
A) Workspace
The workspace is the location to gain access to all Azure databricks assets. In addition to providing access to data items and computational resources, it polarizes them and arranges them into hierarchies. This area of the workspace includes:
- Dashboard: Dashboard is an interface that gives the user access to many visualizations.
- Package: Package that can be made accessible to notebooks or jobs operating on the cluster. Additionally, we can add our libraries.
- Repo: Repo is an abbreviation for "repository," which refers to a folder in which the contents are versioned together by synchronizing them to a local git repository.
- Experiment: An experiment is a compiled set of machine learning flows to train a machine learning model.
B) Interface
The interface is compatible with three functions: UI, REST API, and CLI (command line).
- UI: It offers a comfortable and intuitive user experience for working with workspace folders and their resources.
- REST API: There are two different versions of the REST API, which are known as REST API 2.0 and REST API 1.2. REST API 2.0 has all REST API 1.2 and a few new capabilities. Therefore, REST API 2.0 is the version that is recommended.
- CLI: CLI is a free and open-source project on the GitHub website. REST API 2.0 serves as the foundation for CLI.
C) Data Management
The following is a topic of the four accurate stages that are followed by data management in the management of the SQL process:
- Databricks File System (DBFS): It is an abstraction layer that sits above the Blob storage and is known as the Databricks File System or DBFS. It is organized into folders, which may include additional files or directories.
- Table: Apache Spark SQL and the Apache Spark APIs allow users to query tables. Tables may be found in Apache Spark.
- Metastore: In the data warehouse, the information stored in the metastore pertains to the numerous tables and partitions.
D) Computation Management
To use Azure Databricks for computational tasks. We need to know the following:
- Cluster: Cluster refers to a collection of computing resources and configurations that serve as a platform for executing notebooks and tasks. These can be divided into two categories:
- All-purpose: We may use either the graphical user interface (UI), the command line interface (CLI), or the REST application programming interface (API) to construct a general-purpose cluster. We can manually terminate and restart a cluster that serves many purposes. These clusters may be shared among several people, allowing for collaborative and interactive analysis.
- Job: After executing a job on a new job cluster, the Azure Databricks job scheduler establishes a task cluster and terminates the cluster when the job is finished. A task cluster cannot be restarted at this time.
- Pool: The pool provides a collection of instances that are ready to be used, which speeds up the cluster start-up process. Additionally, it speeds up the auto-scaling process. If there are not enough resources in the pool, it will grow more significantly on its own. When an associated cluster is deactivated, the instances of users are returned to the pool, where they are available for subsequent use by another cluster.
E) Databricks Runtime
Databricks Runtime is an Apache Spark-based framework developed specifically for Microsoft's Azure cloud.
Using Azure Databricks, you won't need any technical knowledge or experience to set up and configure your data architecture since the service removes all of the complexities. Data engineers concerned with the efficiency of production operations can use Azure Databricks, which offers a Spark engine that is quicker and more performant thanks to numerous enhancements at the I/O layer and the processing layer (Databricks I/O).
F) Job
- Workload: There are two different kinds of workloads in terms of pricing methods, and they are as follows:
Data engineering workload: This workload is performed on a task cluster.
Data analytics workload: The workload known as data analytics is carried out by an all-purpose cluster.
- Execution context: It is the current condition of an environment within a REPL. Python, R, Scala, and SQL are all supported by it.
G) Model Management
The following are the fundamental ideas that must understand to construct machine learning models:
- Model: This mathematical function models the relationship between the model's inputs and outputs. Steps of training and making inferences are included in machine learning. To train a model, we may use previously collected data and then apply that knowledge to forecast the results of newly collected data.
- Run: Run is a group of metrics, parameters, and tags associated with training a machine learning model.
- Experiment: The run is the fundamental organizational unit for the experiment, and access to the runs is controlled by it. Every single MLflow run is a part of the experiment
H) Authentication and Authorization
- User and group: A user is a person who is permitted to use the system. A group is any collection of users.
- Access control list: An access control list, also known as an access control list (ACL), is a list of permissions associated with a principal and determines who is allowed access to an object. ACL details both the object and the operations that are permitted on it.
Databricks Machine Learning
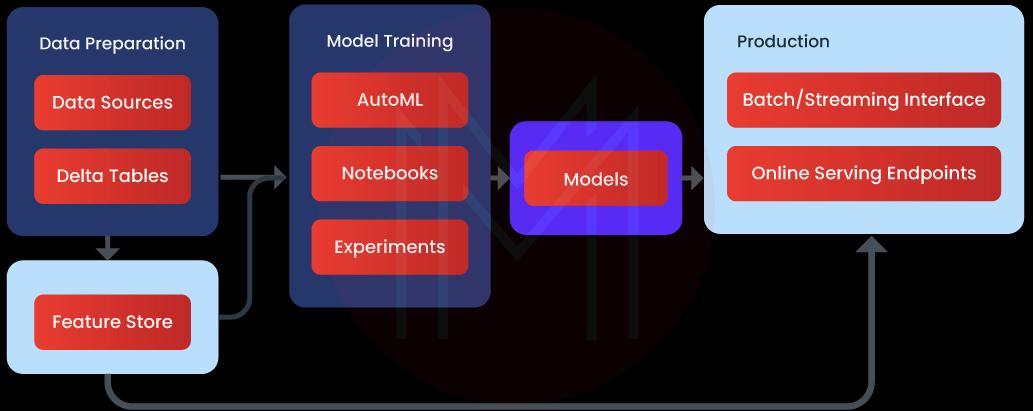
Databricks machine learning is an all-inclusive platform for doing machine learning research. It helps in managing services for feature development, model training, experiment tracking, and management. Beyond that, it can be used as a template.
Databricks machine learning is an end-to-end integrated platform for machine learning that incorporates managed services for feature production, model training, experiment tracking, administration, and model serving. Azure Databricks features and capabilities are a good fit for the many steps required to create and release a model.
You can do the following using data bricks machine learning:
- You may either train models by yourself or use AutoML.
- MLflow monitoring allows you to keep tabs on your experimentation with training parameters and models.
- Make use of feature tables you've created to train and infer models.
- A model registry is a platform for model sharing, management, and delivery.
Additionally, you can use all of the capabilities in the Azure data bricks workspace, including clusters, notebooks, data, tasks, security, Delta tables, administrative controls, and a host of other features.
Conclusion
Azure Databricks is a platform, i.e., cloud analytics, that can meet the needs of data engineers and scientists when building an end-to-end big data solution and deploying it in production. It is possible because Azure Databricks is built on the open-source Apache Hadoop framework. Data scientists and engineers may use it to execute machine learning and real-time analytics. Data engineers can use it to build up clusters, schedule and run processes, and establish links to data sources, among other things.
Simply connecting the cluster to the analytics tool is all required for business users to access the data that has been converted in Azure data bricks analytics tool for reporting purposes.
 On-Job Support Service
On-Job Support Service
Online Work Support for your on-job roles.

Our work-support plans provide precise options as per your project tasks. Whether you are a newbie or an experienced professional seeking assistance in completing project tasks, we are here with the following plans to meet your custom needs:
- Pay Per Hour
- Pay Per Week
- Monthly
| Name | Dates | |
|---|---|---|
| Azure Databricks Training | Aug 01 to Aug 16 | View Details |
| Azure Databricks Training | Aug 04 to Aug 19 | View Details |
| Azure Databricks Training | Aug 08 to Aug 23 | View Details |
| Azure Databricks Training | Aug 11 to Aug 26 | View Details |

Madhuri is a Senior Content Creator at MindMajix. She has written about a range of different topics on various technologies, which include, Splunk, Tensorflow, Selenium, and CEH. She spends most of her time researching on technology, and startups. Connect with her via LinkedIn and Twitter .














