- Home
- Blog
- Microsoft Azure
- Azure Databricks Interview Questions

- Azure Active Directory
- Azure Active Directory B2C
- Azure Active Directory Domain Services
- Azure Analysis Services
- Azure App Services
- What is Azure Application Insights?
- Azure Arc
- Azure Automation - Benefits and Special Features
- A Complete Guide On Microsoft Azure Batch
- Azure Cognitive Services
- Azure Data Catalog
- Azure Data Factory - Data Processing Services
- Microsoft Azure Data Factory Tutorial (2024)
- Everything You Need To Know About Azure Data Lake
- Azure DNS - Azure Domain Name System
- Azure ExpressRoute
- Azure Functions - Serverless Compute
- Azure Interview Questions and Answers (2024)
- Azure IoT Edge Overview
- Azure IoT Hub
- What Is Azure Key Vault??
- Azure Load Balancer
- Azure Logic Apps - The Lego Bricks to Serverless Architecture
- Azure Machine Learning
- Microsoft Azure Media Services
- Azure Monitor
- Introduction To Azure SaaS
- Azure Security Center
- Azure Service Bus
- Overview of Azure Service Fabric
- Azure Site Recovery
- Azure SQL Data Warehouse
- Azure Stack - Cloud Services
- Azure Stream Analytics
- Azure Virtual Machine
- Azure’s Public Cloud
- Microsoft Azure Application Gateway
- Microsoft Azure Certification Path
- Microsoft Azure - Exactly What You Are Looking For!
- Microsoft Azure Fabric Interview Questions
- HDInsight Of Azure
- IS Microsoft Azure Help To Grow?
- Microsoft Azure Portal
- Microsoft Azure Traffic Manager
- Microsoft Azure Tutorial
- Overview of Azure Logic Apps
- Top 10 Reasons Why You Should Learn Azure And Get Certified
- Server-Less Architecture In Azure
- What is Microsoft Azure
- Why Azure Machine Learning?
- Azure DevOps Interview Questions
- Azure Active Directory Interview Questions
- Azure DevOps vs Jira
- What is Azure Service Fabric
- What is Azure Databricks?
- Azure Data Factory Interview Questions
- Azure Architect Interview Questions
- Azure Administrator Interview Questions
- Azure Data Studio vs SSMS
- Microsoft Interview Questions
- What is Azure Data Studio - How to Install Azure Data Studio?
- Azure DevOps Projects and Use Cases
- Azure Data Factory (ADF) Integration Runtime
- Azure DevOps Delivery Plans
- Azure DevOps Variables
- Azure DevOps vs GitHub
- Azure DevOps Pipeline
- Microsoft Azure Services
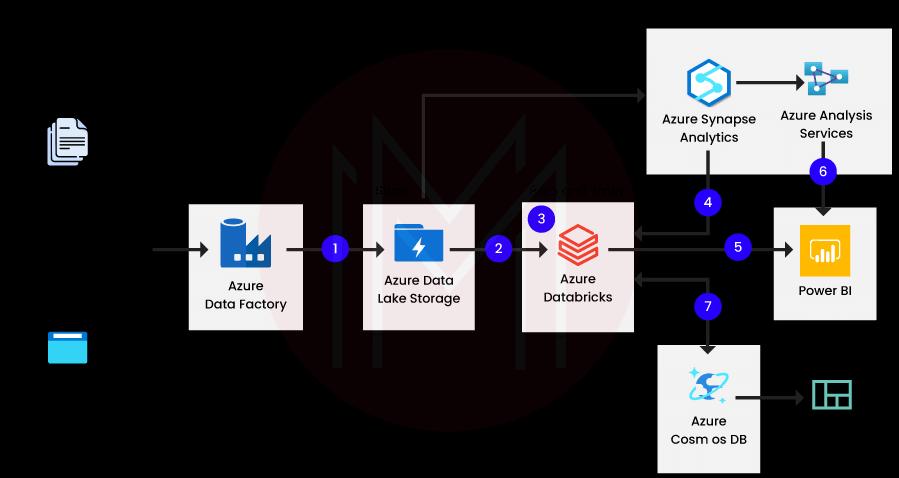
The most recent versions of Apache Spark are available through Azure Databricks, and you can easily incorporate open-source libraries. With Azure's global scale and availability, create clusters quickly in a managed service Apache Spark environment.
Before proceeding with the interview questions, let us first understand the pros and cons of azure databricks.
Databricks Pros:
- With Databricks, it can process a lot of data, and since Azure is a component of it, the data is cloud-native.
- The clusters are simple to configure and set up.
- It can connect to Azure DB and has a connector for Azure Synapse Analytics.
- Active Directory is integrated with it.
- There are several languages supported. The primary language is Scala, but it also integrates well with SQL, R and Python.
Databricks Cons:
- It is not compatible with Git or other version control systems.
- It does not yet support Azure Batch or AZTK; only HDInsight.
For better understanding, we have divided these questions into three categories, they are:
Frequently Asked Azure Databricks Interview Questions
- What exactly does coaching entail?
- How is a Databricks personal access token created?
- What function does Kafka fulfill?
- Can Spark handle streaming data processing?
- Is code reuse possible in the Azure notebook?
- What is a Databricks cluster?
- What distinguishes data lakes from data warehouses?
- Is Databricks owned by Microsoft?
- AWS Databricks and Azure Databricks side by side.
- What languages does Databricks support?
| If you want to enrich your career and become a professional in Azure Databricks, then enroll in "Azure Databricks Training". This course will help you to achieve excellence in this domain. |
Databricks Interview Questions and Answers For Freshers
1. Is it possible to combine Databricks and Azure Notebooks?
They operate similarly, but data transfer to the cluster requires manual coding. This Integration is now easily possible thanks to Databricks Connect. On behalf of Jupyter, Databricks makes a number of improvements that are specific to Databricks.
2. What exactly does coaching entail?
Temporary holding is referred to as the cache. The process of temporarily storing information is referred to as caching. You'll save time and lessen the load on the server when you come back to a frequently visited website because the browser will retrieve the data from the cache rather than from the server.
3. What different types of caching are there?
There are four types of caching that stand out:
- Information caching
- Web page caching
- Widespread caching
- Output or application caching.
[ Learn Complete Azure Databricks Tutorial ]
4. Should you ever remove and clean up any leftover Data Frames?
Cleaning Frames is not necessary unless you use cache(), which will use a lot of network bandwidth. You should probably clean up any large datasets that are being cached but aren't being used.
5. What different ETL operations does Azure Databricks carry out on data?
The various ETL processes carried out on data in Azure Databricks are listed below:
- The data is converted from Databricks to the data warehouse.
- Bold storage is used to load the data.
- Data is temporarily stored using bold storage.
6. Does Azure Key Vault work well as a substitute for Secret Scopes?
That is certainly doable. However, some setup is necessary. The preferred approach is this. Instead of changing the defined secret, start creating a scoped password that Azure Key Vault will backup if the data in secret needs to be changed.
7. How should Databricks code be handled when using TFS or Git for collaborative projects?
TFS is not supported, to start. Your only choices are dispersed Git repository systems and Git. Although it would be ideal to integrate Databricks with the Git directory of notebooks, it works much like a different project clone. Making a notebook, trying to commit it to version control, and afterwards updating it are the first steps.

8. Does Databricks have to be run on a public cloud like AWS or Azure, or can it also run on cloud infrastructure?
This is not true. The only options you have right now are AWS and Azure. But Databricks uses Spark, which is open-source. Although you could build your own cluster and run it in a private cloud, you'd be giving up access to Databricks' robust features and administration.
9. How is a Databricks personal access token created?
- On the Databricks desktop, click the "user profile" icon in the top right corner.
- Choosing "User setting."
- Activate the "Access Tokens" tab.
- A "Generate New Token" button will then show up. Just click it.
10. What steps must be taken to revoke a private access token?
- On the Databricks desktop, click the "user profile" icon in the top right corner.
- Choosing "User setting."
- Activate the "Access Tokens" tab.
- To cancel a token, click the "x" button next to it.
11. What function does Kafka fulfill?
Azure Databricks connects to action hubs and data sources like Kafka when it decides to gather or stream data.
12. What does the Azure data lake serve?
In order to manage, secure, and analyze particular management and administration, Azure data lakes are employed in combination with other IT investments. Additionally, it allows us to improve data applications by utilizing operating repositories and data stores.
13. Why is Azure blob cloud storage backup required?
Blob storage enables redundancy, but it might not be able to handle application failures that could bring down the entire database. We have to continue using secondary Azure blob storage as a result.
14. Can Spark handle streaming data processing?
Undoubtedly, Spark Streaming is an essential part of Spark. There is support for multiple streaming processes. You can publish to a document, read from streaming, and stream a lot of deltas.
15. Is code reuse possible in the Azure notebook?
We should import the code first from Azure notebook into our notebook so that we can reuse it. There are two ways we can import it.
- We must first create a component for the code if it is located on a different workstation before integrating it into the module.
- We can import and use the code right away if it is on the same workstation.
Databricks Interview Questions For Experienced
16. What is a Databricks cluster?
The settings and computing power that make up a Databricks cluster allow us to perform statistical science, big data, and powerful analytic tasks like production ETL, workflows, deep learning, and stream processing.
17. Is it possible to use Databricks to load data into ADLS from on-premises sources?
Even though ADF is a fantastic tool for putting data into lakes, if the lakes are on-premises, you will also need a "self-hosted integration runtime" to give ADF access to the data.
18. What parts of Databricks are there?
- A secure collaborative workstation for developers to code in real-time.
- Managed Groupings to increase query processing speed.
- Delta to address the issues with traditional data lake file formats and manage in-memory data analysis.
- ML Flow to address rising production challenges and ML lifecycle.
- SQL Analytics, which creates queries to retrieve information from data lakes and display it in dashboards.
19. What distinguishes data lakes from data warehouses?
The majority of the structured data in data warehouses has been processed and is managed locally with in-house expertise. You cannot so easily change its structure. All types of data, including unstructured data, such as raw and old data, are present in data lakes. They can be easily scaled up, and the data model could be modified quickly. It uses parallel processing to crunch the data and is retained by third-party tools, ideally in the cloud.
20. Is Databricks only available in the cloud and does not have an on-premises option?
Yes. Databricks' foundational software, Apache Spark, was made available as an on-premises solution, allowing internal engineers to manage both the data and the application locally. Users who access Databricks with data on local servers will encounter network problems because it is a cloud-native application. The on-premises choices for Databricks are also weighed against workflow inefficiencies and inconsistent data.
21. Is Databricks owned by Microsoft?
No. Databricks is still an Apache Spark-based open-sourced product. In 2019, Microsoft invested $250 million. Microsoft has released Azure Databricks in 2017 after integrating some of Databricks' services into its cloud service. Both Google Cloud GCP and Amazon Cloud AWS have similar alliances in place.
22. What type of cloud services does Databricks provide? Do you mean SaaS, PaaS, or IaaS?
The purpose of Databricks' Software as a Service (SaaS) service is to utilize the capabilities of Spark clusters to manage storage. Users will only need to deploy new applications after making changes to their configurations.
[ Related Article: Introduction to Azure SaaS ]
23. What type of cloud service does Azure Databricks provide? Do you mean SaaS, PaaS, or IaaS?
Platform as a Service (PaaS) is the category in which the Azure Databricks service falls. It offers a platform for application development with features based on Azure and Databricks. Utilizing the services provided by Azure Databricks, users must create and build the data life cycle and develop applications.
24. AWS Databricks and Azure Databricks side by side.
The product of effectively integrating Azure and Databricks features is Azure Databricks. Databricks are not just being hosted on the Azure platform. Azure Databricks is a superior product thanks to MS characteristics like Active Directory authentication and assimilation of many Azure functionalities. AWS Databricks merely serves as an AWS cloud server for Databricks.
25. What type of cloud service does Azure Databricks provide? Do you mean SaaS, PaaS, or IaaS?
Platform as a Service (PaaS) is the category in which the Azure Databricks service falls. It offers a platform for application development with features based on Azure and Databricks. Utilizing the services provided by Azure Databricks, users must develop the data life span and develop applications.
26. What languages does Databricks support?
Java, R, Python, Scala, and Standard SQL. It also supports a number of language APIs, including PySpark, Spark SQL, Spark.api.java, SparkR or SparklE, and Spark.
Most Common Azure Databricks FAQs
1. What are Databricks?
Azure provides Databricks, a cloud-based tool for processing and transforming large amounts of data.
2. What is Azure from Microsoft?
It is a platform for cloud computing. To give users access to the services on demand, the service provider could indeed set up a service model in Azure.
3. Describe DBU.
Databricks Unified, also known as DBU, is a framework for managing resources and determining prices.
4. What sets Azure Databricks apart from regular Databricks?
In order to advance statistical modeling and predictive analytics, Microsoft and Databricks have collaborated to create Azure Databricks.
5. What advantages do Azure Databricks offer?
Among the many advantages of Azure Databricks are its lower costs, higher productivity, and enhanced security.
6. Can Databricks and Azure Notebooks coexist?
Although they can be carried out similarly, data transmission to the cluster must be manually coded. This integration can be completed without any issues thanks to Databricks Connect.
7. What kinds of clusters are available in Azure Databricks?
There are four different cluster types in Azure Databricks, including interactive, job, low-priority, and high-priority clusters.
8. Describe caching.
The act of temporarily storing information is referred to as caching. Your browser uses the data from the cache rather than the server when you visit a website that you frequent. Time is saved, and the load on the server is decreased.
9. Is it acceptable to delete the cache?
It is acceptable to clear the cache because no programme requires the information.
10. What steps must be taken to revoke a private authentication code?
Go to "user profile" and choose "User setting" to cancel the token. Click the "x" next to the token you want to revoke by selecting the "Access Tokens" tab. Finally, click the "Revoke Token" button on the Revoke Token window.
Conclusion
You can find Azure Databricks interview questions and responses in this article, which will be helpful when you apply for jobs in the industry. By going through these inquiries, you can make sure you've considered everything a company might be looking for.
 On-Job Support Service
On-Job Support Service
Online Work Support for your on-job roles.

Our work-support plans provide precise options as per your project tasks. Whether you are a newbie or an experienced professional seeking assistance in completing project tasks, we are here with the following plans to meet your custom needs:
- Pay Per Hour
- Pay Per Week
- Monthly
| Name | Dates | |
|---|---|---|
| Azure Databricks Training | Jul 25 to Aug 09 | View Details |
| Azure Databricks Training | Jul 28 to Aug 12 | View Details |
| Azure Databricks Training | Aug 01 to Aug 16 | View Details |
| Azure Databricks Training | Aug 04 to Aug 19 | View Details |

Viswanath is a passionate content writer of Mindmajix. He has expertise in Trending Domains like Data Science, Artificial Intelligence, Machine Learning, Blockchain, etc. His articles help the learners to get insights about the Domain. You can reach him on Linkedin














