
- Introduction to Amazon Elastic File System
- Amazon On-Demand Instance Pricing
- AWS Kinesis
- Amazon Redshift Tutorial
- Amazon SageMaker - AIs Next Game Changer
- AWS Console - Amazon Web Services
- AWS Architect Interview Questions
- AWS Architecture
- Amazon Athena
- Top 11 AWS Certifications List and Exam Learning Path
- How to Create Alarms in Amazon CloudWatch
- AWS CloudWatch Tutorial
- Introduction To AWS CLI
- AWS Configuration
- AWS Data Pipeline Documentation
- AWS EC2 Instance Types
- AWS Elastic Beanstalk
- AWS Elastic Beanstalk Available in AWS GovCloud (US)
- AWS Free Tier Limits and Faq
- AWS EC2 Instance Pricing
- Choosing The Right EC2 Instance Type For Your Application
- AWS Interview Questions and Answers
- AWS Key Management Service
- AWS Lambda Interview Questions
- AWS Lambda Tutorial
- What Is AWS Management Console?
- Complete AWS Marketplace User Guide
- AWS Outage
- AWS Reserved Instances
- AWS SDK
- What is AWS SNS?
- AWS Simple Queue Service
- AWS SysOps Interview Questions
- AWS vs Azure
- AWS Vs Azure Vs Google Cloud Free Tier
- Introduction to AWS Pricing
- Brief Introduction to Amazon Web Services (AWS)
- Clean Up Process in AWS
- Creating a Custom AMI in AWS
- Creating an Elastic Load Balancer in AWS
- How to Deploy Your Web Application into AWS
- How to Launch Amazon EC2 Instance Using AMI?
- How to Launch Amazon EC2 Instances Using Auto Scaling
- How to Sign Up for the AWS Service?
- How to Update Your Amazon EC2 Security Group
- Process of Installing the Command Line Tools in AWS
- Big Data in AWS
- Earning Big Money With AWS Certification
- AWS Certification Without IT Experience. Is It Possible?
- How to deploy a Java enterprise application to AWS cloud
- What is AWS Lambda?
- Top 10 Reasons To Learn AWS
- Run a Controlled Deploy With AWS Elastic Beanstalk
- Apache Spark Clusters on Amazon EC2
- Top 35 AWS Services List
- What is Amazon S3? A Complete AWS S3 Tutorial
- What is AMI in AWS
- What is AWS? Amazon Web Services Introduction
- What is AWS Elasticsearch?
- What is AWS ELB? – A Complete AWS Load Balancer Tutorial
- What is AWS Glue?
- AWS IAM (Identity and Access Management)
- AWS IoT Core Tutorial - What is AWS IoT?
- What is Cloud Computing - Introduction to Cloud Computing
- Why AWS Has Gained Popularity?
- Top 10 Cloud Computing Tools
- AWS Glue Tutorial
- AWS S3 Interview Questions
- AWS Projects and Use Cases
- AWS VPC Interview Questions and Answers
- AWS EC2 Tutorial
- AWS VPC Tutorial
- AWS EC2 Interview Questions
- AWS DynamoDB Interview Questions
- AWS API Gateway Interview Questions
- How to Become a Big Data Engineer
- What is AWS Fargate?
- What is AWS CloudFront
- AWS CloudWatch Interview Questions
- What is AWS CloudFormation?
- What is AWS Cloudformation
- Cloud Computing Interview Questions
- What is AWS Batch
- What is AWS Amplify? - AWS Amplify Alternatives
- Types of Cloud Computing - Cloud Services
- AWS DevOps Tutorial - A Complete Guide
- What is AWS SageMaker - AWS SageMaker Tutorial
- Amazon Interview Questions
- AWS DevOps Interview Questions
- Cognizant Interview Questions
- Cognizant Genc Interview Questions
- Nutanix Interview Questions
- Cloud Computing Projects and Use Cases
- test info
- AWS Server and Administration
- AWS vs Alternatives
AWS Glue is a fully managed, simple, and cost-effective ETL service that makes it easy for users to prepare and load their data for analytics. It is designed to work with semi-structured data. We can use the AWS Glue console to discover data, transform it, and make it available for search and querying. This blog on “AWS Glue Interview questions” is the best way to learn about AWS glue from scratch.
We have segregated AWS Glue interview questions into 2 categories, they are:
Top 10 AWS Glue Interview Questions and Answers
1. What is AWS Glue Data Catalog?
2. How does AWS Glue relate to AWS Lake Formation?
3. What are AWS Glue Crawlers?
4. What are Development Endpoints?
5. What are AWS Tags in AWS Glue
6. What is the AWS Glue Schema Registry?
7. What is the AWS Glue database?
8. What is the AWS Glue job system?
10. What is AWS Glue Elastic Views?
| If you want to Enrich Your Career Potential in AWS glue - then Enroll in our "Amazon Web Services Training" Online Course |
Basic AWS Glue Interview Questions
If you're new to the field and this is your first job, you can expect the following basic
1. What is AWS Glue?
AWS Glue is a managed service ETL (extract, transform, and load) service that enables categorizing, cleaning, enriching, and moving data reliably between various data storage and data streams simple and cost-effective. AWS Glue consists of the AWS Glue Data Catalog, an ETL engine that creates Python or Scala code automatically, and a customizable scheduler that manages dependency resolution, job monitoring, and retries. Because AWS Glue is serverless, there is no infrastructure to install or maintain.
2. Describe AWS Glue Architecture
The architecture of an AWS Glue environment is shown in the figure below.
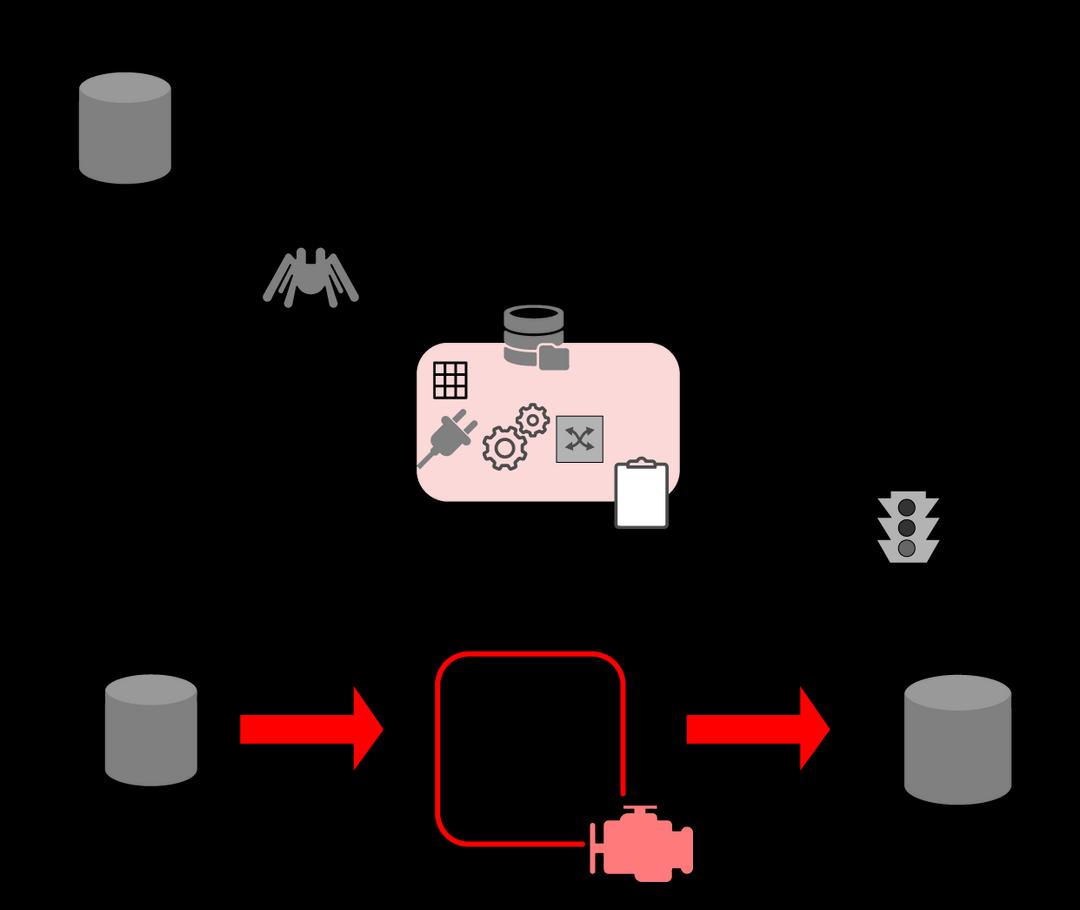
- The fundamentals of using AWS Glue to generate one's Data Catalog and processing ETL dataflows.
- In AWS Glue, users create tasks to complete the operation of extracting, transforming, and loading (ETL) data from a data source to a data target. You usually do the following:
- You construct a crawler for datastore resources to enrich one's AWS Glue Data Catalog with metadata table entries. When you direct your crawler to a data store, the crawler populates the Data Catalog with table definitions. Manually define Data Catalog tables and data stream characteristics for streaming sources.
- In addition to table descriptions, the AWS Glue Data Model contains additional metadata that is required to build ETL operations. Users use this information when they take on that job to alter their data.
- AWS Glue may generate a data transformation script. Users can also provide the script using the AWS Glue console or API.
- Users could complete their task immediately or set it to start when another incidence occurs. The trigger could be a timer or an event.
- When a user's task starts, a script pulls information from the user's data source, modifies it, and sends it to the user's data target. The script is run in an Apache Spark environment through AWS Glue.
[Read Also: AWS Glue Tutorial]
3. What are the Features of AWS Glue?
The key features of AWS Glue are listed below:
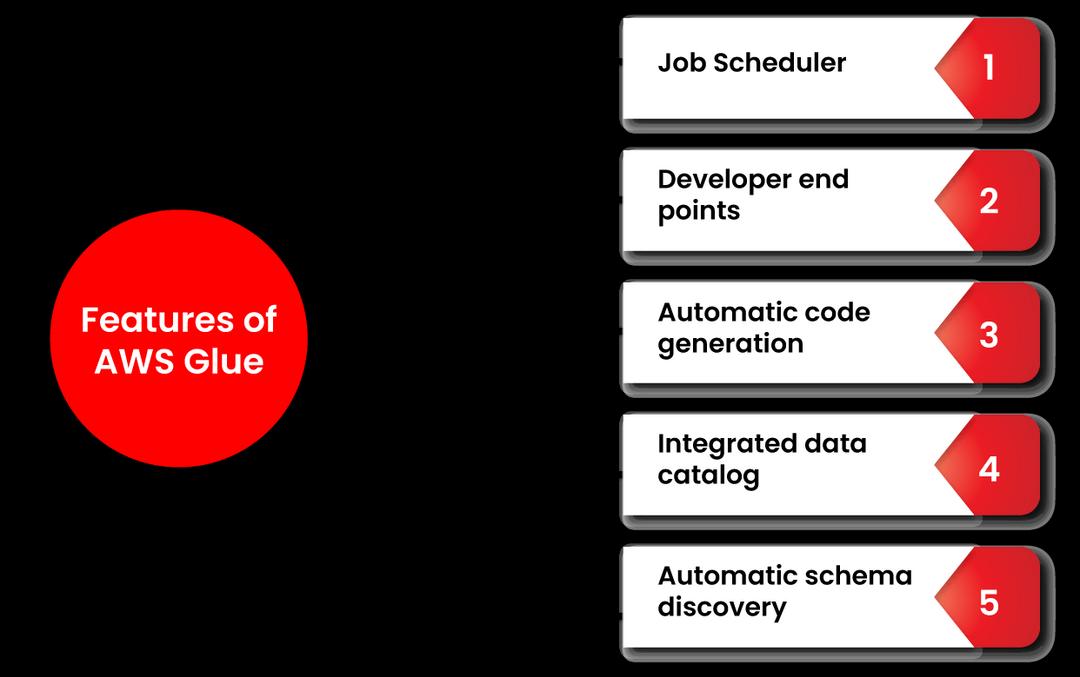
Automatic Schema Discovery
Enables crawlers to automatically acquire scheme-related information and store it in a data catalog.
Job Scheduler
Several jobs can be initiated simultaneously, and users can specify job dependencies.
Developer Endpoints
Aid in creating bespoke readers, writers, and transformations.
Automatic Code Generation (ACG)
Aids in building code.
Integrated Data Catalog
The AWS pipeline's Integrated Data Catalog stores various sources.
4. What are the Benefits of AWS Glue?
The following are some of the advantages of AWS Glue:
- Fault Tolerance - AWS Glue logs can be debugged and retrieved.
- Filtering - For poor data, AWS Glue employs filtering.
- Maintenance and Development - AWS Glue relies on maintenance and deployment because AWS manages the service.
5. When to use a Glue Classifier?
A Glue Classifier is used to crawl a data store in the AWS Glue Data Catalog to generate metadata tables. An ordered set of classifiers can be used to configure your crawler. When a crawler calls a classifier, the classifier determines whether or not the data is recognized. If the first classifier fails to acknowledge the data or is unsure, the crawler moves to the next classifier in the list to see if it can.
6. What are the main components of AWS Glue?
AWS Glue’s main components are as follows:
- Data Catalog acts as a central metadata repository
- ETL engine that can automatically generate Scala or Python code.
- The flexible scheduler manages dependency resolution, job monitoring, and retries.
- AWS Glue DataBrew allows the user to clean and stabilize data using a visual interface.
- AWS Glue Elastic View will enable users to combine and replicate data across multiple data stores.
These solutions will allow you to spend more time analyzing your data by automating most of the non-differentiated labor associated with data search, categorization, cleaning, enrichment, and migration.
7. What Data Sources are supported by AWS Glue?
AWS Glue's data sources include:
- Amazon Aurora
- Amazon RDS for MySQL
- Amazon RDS for Oracle
- Amazon RDS for PostgreSQL
- Amazon RDS for SQL Server
- Amazon Redshift
- DynamoDB
- Amazon S3
- MySQL
- Oracle
- Microsoft SQL Server
8. What is AWS Glue Data Catalog?
Your persistent metadata repository is AWS Glue Data Catalog. It's a managed service that allows you to store, annotate, and exchange metadata in the AWS Cloud in the same way as an Apache Hive metastore does.AWS Glue Data Catalogs are unique to each AWS account and region. It creates a centralized location where diverse systems may store and get metadata to maintain data in data silos and query and alter the data using that metadata. Access to the data sources handled by the AWS Glue Data Catalog can be controlled with AWS Identity and Access Management (IAM) policies.
9. Which AWS services and open-source projects use AWS Glue Data Catalog?
The AWS Glue Data Catalog is used by the following AWS services and open-source projects:
- AWS Lake Formation
- Amazon Athena
- Amazon Redshift Spectrum
- Amazon EMR
- AWS Glue Data Catalog Client for Apache Hive Metastore
10. What are AWS Glue Crawlers?
AWS Glue crawler is used to populate the AWS Glue catalog with tables. It can crawl many data repositories in one operation. One or even more tables in the Data Catalog are created or modified when the crawler is done. In ETL operations defined in AWS Glue, these Data Catalog tables are used as sources and targets. The ETL task reads and writes data to the Data Catalog tables in the source and target.

11. What is the AWS Glue Schema Registry?
The AWS Glue Schema Registry assists us by allowing to validate and regulate the lifecycle of streaming data using registered Apache Avro schemas at no cost. Apache Kafka, Amazon Managed Streaming for Apache Kafka (MSK), Amazon Kinesis Data Streams, Apache Flink, Amazon Kinesis Data Analytics for Apache Flink, and AWS Lambda benefit from Schema Registry.
12. Why should we use AWS Glue Schema Registry?
You can use the AWS Glue Schema Registry to:
- Validate schemas: Schemas used for data production are checked against schemas in a central registry when data streaming apps are linked with AWS Glue Schema Registry, allowing you to regulate data quality centrally.
- Safeguard schema evolution: One of eight compatibility modes can be used to specify criteria for how schemas can and cannot grow.
- Improve data quality: Serializers compare data producers' schemas to those in the registry, enhancing data quality at the source and avoiding downstream difficulties caused by random schema drift.
- Save costs: Serializers transform data into a binary format that can be compressed before transferring, lowering data transfer and storage costs.
- Improve processing efficiency: A data stream frequently comprises records with multiple schemas. The Schema Registry allows applications that read data streams to process each document based on the schema rather than parsing its contents, increasing processing performance.
13. When should I use AWS Glue vs. AWS Batch?
AWS Batch enables you to conduct any batch computing job on AWS with ease and efficiency, regardless of the work type. AWS Batch maintains and produces computing resources in your AWS account, giving you complete control over and insight into the resources in use. AWS Glue is a fully-managed ETL solution that runs your ETL tasks in a serverless Apache Spark environment. We recommend using AWS Glue for your ETL use cases. AWS Batch might be a better fit for some batch-oriented use cases, such as ETL use cases.
14. What kinds of evolution rules does AWS Glue Schema Registry support?
Backward, Backward All, Forward, Forward All, Full, Full All, None, and Disabled are the compatibility modes accessible to regulate your schema evolution.
15. How does AWS Glue Schema Registry maintain high availability for applications?
The AWS Glue SLA is underpinned by the Schema Registry storage and control plane, and the serializers and deserializers use best-practice caching strategies to maximize client schema availability.
16. Is AWS Glue Schema Registry open-source?
The serializers and deserializers are Apache-licensed open-source components, but the Glue Schema Registry storage is an AWS service.
17. How does AWS Glue relate to AWS Lake Formation?
AWS Lake Formation benefits from AWS Glue's shared infrastructure, which offers console controls, ETL code development and task monitoring, a shared data catalog, and serverless architecture. Lake Formation features AWS Glue capability and additional capabilities for constructing, securing, and administering data lakes, even though AWS Glue is still focused on such types of procedures.
18. What are Development Endpoints?
The term "development endpoints" is used to describe the AWS Glue API's testing capabilities when utilizing Custom DevEndpoint. A developer may debug the extract, transform, and load ETL Scripts at the endpoint.
19. What are AWS Tags in AWS Glue?
A tag is a label you apply to an Amazon Web Services resource. Each tag has a key and an optional value, both of which are defined by you.
In AWS Glue, you may use tags to organize and identify your resources. Tags can be used to generate cost accounting reports and limit resource access. You can restrict which users in your AWS account have authority to create, update, or delete tags if you use AWS Identity and Access Management.
The following AWS Glue resources can be tagged:
- Crawler
- Job
- Trigger
- Workflow
- Development endpoint
- Machine learning transform
20. What are the points to remember when using tags with AWS Glue?
- Each entity can have a maximum of 50 tags.
- Tags are specified as a list of key-value pairs in the "string": "string"... in AWS Glue.
- The tag key is necessary when creating a tag on an item, but the tag value is not.
- Case matters when it comes to the tag key and value.
- The prefix AWS cannot be used in the tag key or the tag value. Such tags are not subject to any activities.
- In UTF-8, 128 Unicode characters are the maximum tag key length. There can't be any empty or null tags in the tag key.
- In UTF-8, 256 Unicode characters are the highest tag value length. The tag value may be null or empty.
21. What is the AWS Glue database?
The AWS Glue Data Catalog database is a container that houses tables. You utilize databases to categorize your tables. When you run a crawler or manually add a table, you establish a database. All of your databases are listed in the AWS Glue console's database list.
22. What programming language is used to write ETL code for AWS Glue?
Scala or Python can write ETL code for AWS Glue.
23. What is the AWS Glue Job system?
AWS Glue Jobs is a managed platform for orchestrating your ETL workflow. In AWS Glue, you may construct jobs to automate the scripts you use to extract, transform, and transport data to various places. Jobs can be scheduled and chained, or events like new data arrival can trigger them.
24. Does AWS Glue use EMR?
The AWS Glue Data Catalog integrates with Amazon EMR, Amazon RDS, Amazon Redshift, Redshift Spectrum, Athena, and any application compatible with the Apache Hive megastore, providing a consistent metadata repository across several data sources and data formats.
Advanced AWS Glue interview questions with answers
25. Does AWS Glue have a no-code interface for visual ETL?
Yes. AWS Glue Studio is a graphical tool for creating Glue jobs that process data. AWS Glue studio will produce Apache Spark code on your behalf once you've defined the flow of your data sources, transformations, and targets in the visual interface.
AWS Glue Advanced Interview Questions
26. How do I query metadata in Athena?
AWS Glue metadata such as databases, tables, partitions, and columns may be queried using Athena. Individual hive DDL commands can be used to extract metadata information from Athena for specific databases, tables, views, partitions, and columns, but the results are not tabular.
27. What is the general workflow for how a Crawler populates the AWS Glue Data Catalog?
The usual method for populating the AWS Glue Data Catalog via a crawler is as follows:
- To deduce the format and schema of your data, a crawler runs any custom classifiers you specify. Custom classifiers are programmed by you and run in the order you specify.
- A schema is created using the first custom classifier that correctly recognizes your data structure. Lower-ranking custom classifiers are ignored.
- Built-in classifiers attempt to identify your data schema if no custom classifier matches it. One that acknowledges JSON is an example of a built-in classifier.
- The crawler accesses the data storage. Connection attributes are required for crawler access to some data repositories.
- Your data will be given an inferred schema.
- The crawler populates the data catalog. A table description is a piece of metadata that defines your data store's data. The table is kept in the Data Catalog, a database container for tables. The label generated by the classifier that inferred the table schema is the table's classification attribute.
28. How to customize the ETL code generated by AWS Glue?
Scala or Python code is generated via the AWS Glue ETL script suggestion engine. It makes use of Glue's ETL framework to manage task execution and facilitate access to data sources. One can use AWS Glue's library to write ETL code, or you can use inline editing using the AWS Glue Console script editor to write arbitrary code in Scala or Python, which you can then download and modify in your IDE.
29. How to build an end-to-end ETL workflow using multiple jobs in AWS Glue?
AWS Glue includes a sophisticated set of orchestration features that allow you to handle dependencies between numerous tasks to design end-to-end ETL processes; in addition to the ETL library and code generation, AWS Glue ETL jobs can be scheduled or triggered when they finish. Several jobs can be activated simultaneously or sequentially by triggering them on a task completion event.
30. How does AWS Glue monitor dependencies?
AWS Glue uses triggers to handle dependencies among two or more activities or external events. Triggers can both watch and invoke jobs. The three options are a scheduled trigger, which runs jobs regularly, an on-demand trigger, or a job completion trigger.
31. How does AWS Glue handle ETL errors?
AWS Glue tracks job metrics and faults and sends all alerts to Amazon CloudWatch. You may set up Amazon CloudWatch to do various tasks responding to AWS Glue notifications. You can use AWS Lambda to trigger an AWS Lambda function when you get an error or a success notice from Glue. Glue also has a default retry behavior that retries all errors three times before generating an error message.
32. Can we run existing ETL jobs with AWS Glue?
Yes. On AWS Glue, we can run your Scala or Python code. Simply save the code to Amazon S3 and use it in one or more jobs. We can reuse code across multiple jobs by connecting numerous jobs to the exact code location on Amazon S3.
33. What AWS Glue Schema Registry supports data format, client language, and integrations?
The Schema Registry supports Java client apps and Apache Avro and JSON Schema data formats. We intend to keep adding support for non-Java clients and various data types. The Schema Registry works with Apache Kafka, Amazon Managed Streaming for Apache Kafka (MSK), Amazon Kinesis Data Streams, Apache Flink, Amazon Kinesis Data Analytics for Apache Flink, and AWS Lambda applications.
34. How to get metadata into the AWS Glue Data Catalog?
The AWS Glue Data Catalog can be populated in a variety of ways. Crawlers in the Glue Data Catalog search various data stores you own to infer schemas and partition structure and populate the Glue Data Catalog with table definitions and statistics. You can also run crawlers regularly to keep your metadata current and in line with the underlying data. Users can also use the AWS Glue Console or the API to manually add and change table information. Hive DDL statements can also be executed on an Amazon EMR cluster via the Amazon Athena Console or a Hive client.
35. How to import data from the existing Apache Hive Metastore to the AWS Glue Data Catalog?
Simply execute an ETL process that reads data from your Apache Hive Metastore, exports it to Amazon S3, and imports it into the AWS Glue Data Catalog.
36. Do we need to maintain my Apache Hive Metastore if we store metadata in the AWS Glue Data Catalog?
No, the Apache Hive Metastore is incompatible with AWS Glue Data Catalog. You can use Glue Data Catalog to replace Apache Hive Metastore by pointing to its endpoint.
37. When should we use AWS Glue Streaming, and when should I use Amazon Kinesis Data Analytics?
Streaming data can be processed with AWS Glue and Amazon Kinesis Data Analytics. AWS Glue is advised when your use cases are mostly ETL, and you wish to run tasks on a serverless Apache Spark-based infrastructure. Amazon Kinesis Data Analytics is recommended when your use cases are mostly analytics, and you want to run jobs on a serverless Apache Flink-based platform.
AWS Glue's Streaming ETL allows you to perform complex ETL on streaming data using the same serverless, pay-as-you-go infrastructure that you use for batch tasks. AWS Glue provides customized ETL code to prepare your data in flight and has built-in functionality to process semi-structured or developing schema Streaming data. Use Glue to load data streams into your data lake or warehouse using its built-in and Spark-native transformations.
We can use Amazon Kinesis Data Analytics to create complex streaming applications that analyze data in real time. It offers a serverless Apache Flink runtime that scales without servers and saves application information indefinitely. For real-time analytics and more generic stream data processing, use Amazon Kinesis Data Analytics.
38. What is AWS Glue DataBrew?
AWS Glue DataBrew is a visual data preparation solution that allows data analysts and scientists to prepare without writing code using an interactive, point-and-click graphical interface. You can simply visualize, clean, and normalize terabytes, even petabytes, of data directly from your data lake, data warehouses, and databases, including Amazon S3, Amazon Redshift, Amazon Aurora, and Amazon RDS, with Glue DataBrew.
39. Who can use AWS Glue DataBrew?
AWS Glue DataBrew is designed for users that need to clean and standardize data before using it for analytics or machine learning. The most common users are data analysts and data scientists. Business intelligence analysts, operations analysts, market intelligence analysts, legal analysts, financial analysts, economists, quants, and accountants are examples of employment functions for data analysts. Materials scientists, bioanalytical scientists, and scientific researchers are all examples of employment functions for data scientists.
40. What types of transformations are supported in AWS Glue DataBrew?
You can combine, pivot, and transpose data using over 250 built-in transformations without writing code. AWS Glue DataBrew also suggests transformations such as filtering anomalies, rectifying erroneous, wrongly classified, duplicate data, normalizing data to standard date and time values, or generating aggregates for analysis automatically. Glue DataBrew enables transformations that leverage powerful machine learning techniques such as Natural Language Processing for complex transformations like translating words to a common base or root word (NLP). Multiple transformations can be grouped, saved as recipes, and applied straight to incoming data.
41. What file formats does AWS Glue DataBrew support?
AWS Glue DataBrew accepts comma-separated values (.csv), JSON and nested JSON, Apache Parquet and nested Apache Parquet, and Excel sheets as input data types. Comma-separated values (.csv), JSON, Apache Parquet, Apache Avro, Apache ORC, and XML are all supported as output data formats in AWS Glue DataBrew.
42. Do we need to use AWS Glue Data Catalog or AWS Lake Formation to use AWS Glue DataBrew?
No. Without using the AWS Glue Data Catalog or AWS Lake Formation, you can use AWS Glue DataBrew. DataBrew users can pick data sets from their centralized data catalog using the AWS Glue Data Catalog or AWS Lake Formation.
43. What is AWS Glue Elastic Views?
AWS Glue Elastic Views makes it simple to create materialized views that integrate and replicate data across various data stores without writing proprietary code. AWS Glue Elastic Views can quickly generate a virtual materialized view table from multiple source data stores using familiar Structured Query Language (SQL). AWS Glue Elastic Views moves data from each source data store to a destination datastore and generates a duplicate of it. AWS Glue Elastic Views continuously monitors data in your source data stores, and automatically updates materialized views in your target data stores, ensuring that data accessed through the materialized view is always up-to-date.
44. Why should we use AWS Glue Elastic Views?
Use AWS Glue Elastic Views to aggregate and continuously replicate data across several data stores in near-real-time. This is frequently the case when implementing new application functionality requiring data access from one or more existing data stores. For example, a company might use a customer relationship management (CRM) application to keep track of customer information and an e-commerce website to handle online transactions. The data would be stored in these apps or more data stores. The firm is now developing a new custom application that produces and displays special offers for active website visitors.
Conclusion
The blog has come to an end. We've addressed the most common AWS Glue interview questions from organizations like Infosys, Accenture, Cognizant, TCS, Wipro, Amazon, Oracle, and others. We hope that the above-mentioned interview question will assist you in passing the interview and moving forward into the bright future. Best wishes for your upcoming interview.
 On-Job Support Service
On-Job Support Service
Online Work Support for your on-job roles.

Our work-support plans provide precise options as per your project tasks. Whether you are a newbie or an experienced professional seeking assistance in completing project tasks, we are here with the following plans to meet your custom needs:
- Pay Per Hour
- Pay Per Week
- Monthly
| Name | Dates | |
|---|---|---|
| AWS Training | Jul 21 to Aug 05 | View Details |
| AWS Training | Jul 25 to Aug 09 | View Details |
| AWS Training | Jul 28 to Aug 12 | View Details |
| AWS Training | Aug 01 to Aug 16 | View Details |

Madhuri is a Senior Content Creator at MindMajix. She has written about a range of different topics on various technologies, which include, Splunk, Tensorflow, Selenium, and CEH. She spends most of her time researching on technology, and startups. Connect with her via LinkedIn and Twitter .














