
- Introduction to Amazon Elastic File System
- Amazon On-Demand Instance Pricing
- AWS Kinesis
- Amazon Redshift Tutorial
- Amazon SageMaker - AIs Next Game Changer
- AWS Console - Amazon Web Services
- AWS Architect Interview Questions
- AWS Architecture
- Amazon Athena
- Top 11 AWS Certifications List and Exam Learning Path
- How to Create Alarms in Amazon CloudWatch
- AWS CloudWatch Tutorial
- Introduction To AWS CLI
- AWS Configuration
- AWS Data Pipeline Documentation
- AWS EC2 Instance Types
- AWS Elastic Beanstalk
- AWS Elastic Beanstalk Available in AWS GovCloud (US)
- AWS Free Tier Limits and Faq
- AWS EC2 Instance Pricing
- Choosing The Right EC2 Instance Type For Your Application
- AWS Interview Questions and Answers
- AWS Key Management Service
- AWS Lambda Interview Questions
- AWS Lambda Tutorial
- What Is AWS Management Console?
- Complete AWS Marketplace User Guide
- AWS Outage
- AWS Reserved Instances
- AWS SDK
- What is AWS SNS?
- AWS Simple Queue Service
- AWS SysOps Interview Questions
- AWS vs Azure
- AWS Vs Azure Vs Google Cloud Free Tier
- Introduction to AWS Pricing
- Brief Introduction to Amazon Web Services (AWS)
- Clean Up Process in AWS
- Creating a Custom AMI in AWS
- Creating an Elastic Load Balancer in AWS
- How to Deploy Your Web Application into AWS
- How to Launch Amazon EC2 Instance Using AMI?
- How to Launch Amazon EC2 Instances Using Auto Scaling
- How to Sign Up for the AWS Service?
- How to Update Your Amazon EC2 Security Group
- Process of Installing the Command Line Tools in AWS
- Big Data in AWS
- Earning Big Money With AWS Certification
- AWS Certification Without IT Experience. Is It Possible?
- How to deploy a Java enterprise application to AWS cloud
- What is AWS Lambda?
- Top 10 Reasons To Learn AWS
- Run a Controlled Deploy With AWS Elastic Beanstalk
- Apache Spark Clusters on Amazon EC2
- Top 35 AWS Services List
- What is Amazon S3? A Complete AWS S3 Tutorial
- What is AMI in AWS
- What is AWS? Amazon Web Services Introduction
- What is AWS Elasticsearch?
- What is AWS ELB? – A Complete AWS Load Balancer Tutorial
- What is AWS Glue?
- AWS IAM (Identity and Access Management)
- AWS IoT Core Tutorial - What is AWS IoT?
- What is Cloud Computing - Introduction to Cloud Computing
- Why AWS Has Gained Popularity?
- Top 10 Cloud Computing Tools
- AWS Glue Tutorial
- AWS Glue Interview Questions
- AWS S3 Interview Questions
- AWS Projects and Use Cases
- AWS VPC Interview Questions and Answers
- AWS EC2 Tutorial
- AWS VPC Tutorial
- AWS EC2 Interview Questions
- AWS DynamoDB Interview Questions
- AWS API Gateway Interview Questions
- How to Become a Big Data Engineer
- What is AWS Fargate?
- What is AWS CloudFront
- AWS CloudWatch Interview Questions
- What is AWS CloudFormation?
- What is AWS Cloudformation
- Cloud Computing Interview Questions
- What is AWS Batch
- What is AWS Amplify? - AWS Amplify Alternatives
- Types of Cloud Computing - Cloud Services
- AWS DevOps Tutorial - A Complete Guide
- Amazon Interview Questions
- AWS DevOps Interview Questions
- Cognizant Interview Questions
- Cognizant Genc Interview Questions
- Nutanix Interview Questions
- Cloud Computing Projects and Use Cases
- test info
- AWS Server and Administration
- AWS vs Alternatives
It’s worth noting that deploying Machine Learning (ML) models in a production environment is really challenging. AWS SageMaker overcomes this setback by building high-quality ML models. Also, it simplifies the deployment of the models.
Now, the question is, what is AWS SageMaker exactly? AWS SageMaker is nothing but a cloud-based ML-hosted environment. With AWS SageMaker, You can quickly build and train ML models. Then, you can deploy the models in the production-ready environment effortlessly.
The main thing about AWS SageMaker is that you don’t need to manage servers since it is a fully managed platform. Curious to learn its features, use cases, and others?
Well! In this blog post, you can learn what is AWS SageMaker, how it works, its vital features, benefits, and a lot more things that await you.
What is AWS SageMaker?
AWS SageMaker is a cloud-based ML platform with which you can quickly create, test, train, and deploy advanced ML models. This AWS service uses powerful ML algorithms to develop and train the models. After that, it deploys them in the production environment smoothly.
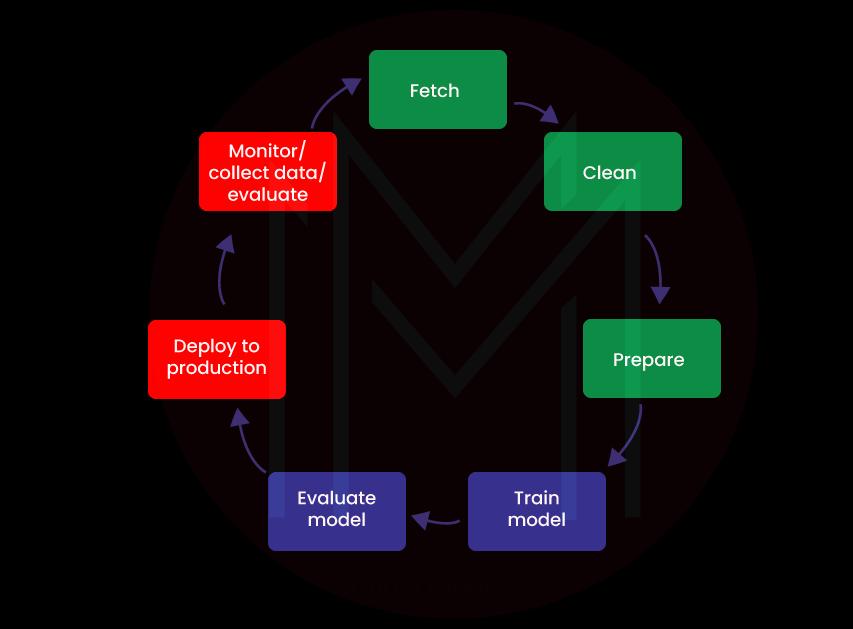
Generally, if you want to build and train efficient ML models, you must manage a huge volume of data. And you need to manage powerful computing resources as well. AWS SageMaker simplifies these requirements in collaboration with other AWS services.
Know that Sagemaker supports all the popular ML frameworks and programming languages.
We Hope you are clear about what is AWS SageMaker. Next, we will look at how it works and all other vital aspects of SageMaker in the coming topics.
| Looking forward to becoming a master in "Cloud Computing Courses"? Check out the "AWS Training" and get certified today. |
How does AWS SageMaker work?
As you know, AWS SageMaker is the cloud platform that you can use to create, train, and deploy ML models into applications in a production-ready environment. In other words, AWS SageMaker functions in three phases: building, training, and deploying ML models.
Let’s discover more about the three phases in detail in the following.
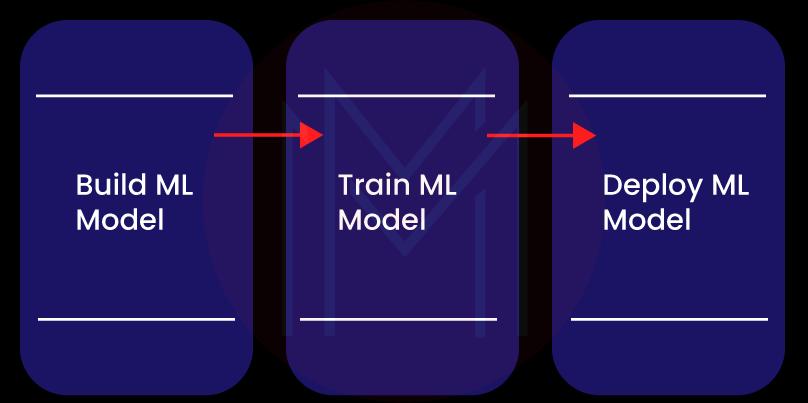
Building ML Models
Before building models, the essential thing that we need to do is prepare the example data. This is the data required to train ML models. We need to store this data in a single repository. Also, we need to clean the data to bring consistency to the data. Because of this, we can quickly transform the data and then allow ML models to learn the data to derive the best results.
We use Jupyter Notebooks on the AWS SageMaker to process the example data. With notebooks, you can quickly retrieve, clean, and transform the data. When it comes to fetching data, you can bring any amount of data from the Amazon S3 bucket. Also, AWS SageMaker creates ML instances in AWS EC2. The EC2 instances support running Jupyter notebooks.
Training ML Model
Know that we use algorithms to train ML models. AWS SageMaker offers many powerful algorithms. For example, image classification and linear regression are a few AWS SageMaker algorithms developers or data scientists widely use to build ML models. Not only that, SageMaker allows using custom-built ML algorithms as well as Docker container images to build ML models.
However, we need to choose the algorithms based on the application requirements. Also, we need to select the resources based on the requirements. For instance, we can use only one general-purpose instance or a cluster of instances. Besides, you need to specify the instance types and location of data while training ML models.
Once you complete training an ML model, you need to evaluate the ML models to check whether they derive accurate inferences. In this regard, Sagemaker allows using Jupyter notebooks to assess the ML models. Also, it allows using a high-level Python library for evaluating the models.
Deploying ML Models
You can enhance the quality of ML models before deploying them in production. And you need to perform the necessary health checks in the ML models before the deployment. Applying security is also essential before the deployment. You need to set auto-scaling to allocate resources. Besides, you need to create HTTPS endpoints to improve security.
Advantages of AWS SageMaker
AWS SageMaker offers many advantages to its users. We will list them as follows:
- It allows storing a high volume of data with the support of AWS S3 bucket
- It will enable using powerful compute instances such as AWS EC2
- It performs data labeling in a short time
- It stores all the ML components in a single place
- It performs quick scaling of resources with the help of AWS Lambda
- It always maintains good uptime
- It ensures advanced security for data
- It supports programming languages such as Java, C, and Python. It also supports front-end languages such as CSS, HTML, and JavaScript.
- It facilities users with pre-built ML algorithms along with drag-and-drop options.
- Above all, AWS SageMaker enhances productivity by quickly building and deploying ML models.
| Related Article: What is AWS? |
Role of Machine Learning in AWS SageMaker
Essentially, we build and train ML models to make predictions or inferences. We use ML algorithms to develop and train the models. Then, we deploy the models into the applications in a production environment. Finally, the models generate inferences based on the real-time input data.
The significant thing about ML models is that they can process high-volume data in no time. In other words, it can process millions of data and generate results in milliseconds.
Let’s find out the role of ML in AWS SageMaker now.
SageMaker uses effective tools to automate mundane or repetitive processes. The SageMaker tool set includes all the crucial ML modeling components. And the SageMaker templates consist of all the required software capabilities. Using these features, SageMaker performs creating, training, and deploying ML models at scale. Besides, you reduce human errors and modeling costs remarkably using the automation capabilities of SageMaker.
How to train ML models using AWS SageMaker?
First, we need to create a training job. Creating the training job is essential to train ML models. Every training job will include the following:
- The URL of the Amazon S3 Bucket where you will store the input data
- The URL of the Amazon S3 bucket where you will keep the output data.
- The details of compute resources that SageMaker will use to train ML models
- The path of the Amazon Elastic container registry where you will save the modeling codes.
Let’s now look at how the training of ML models is performed.
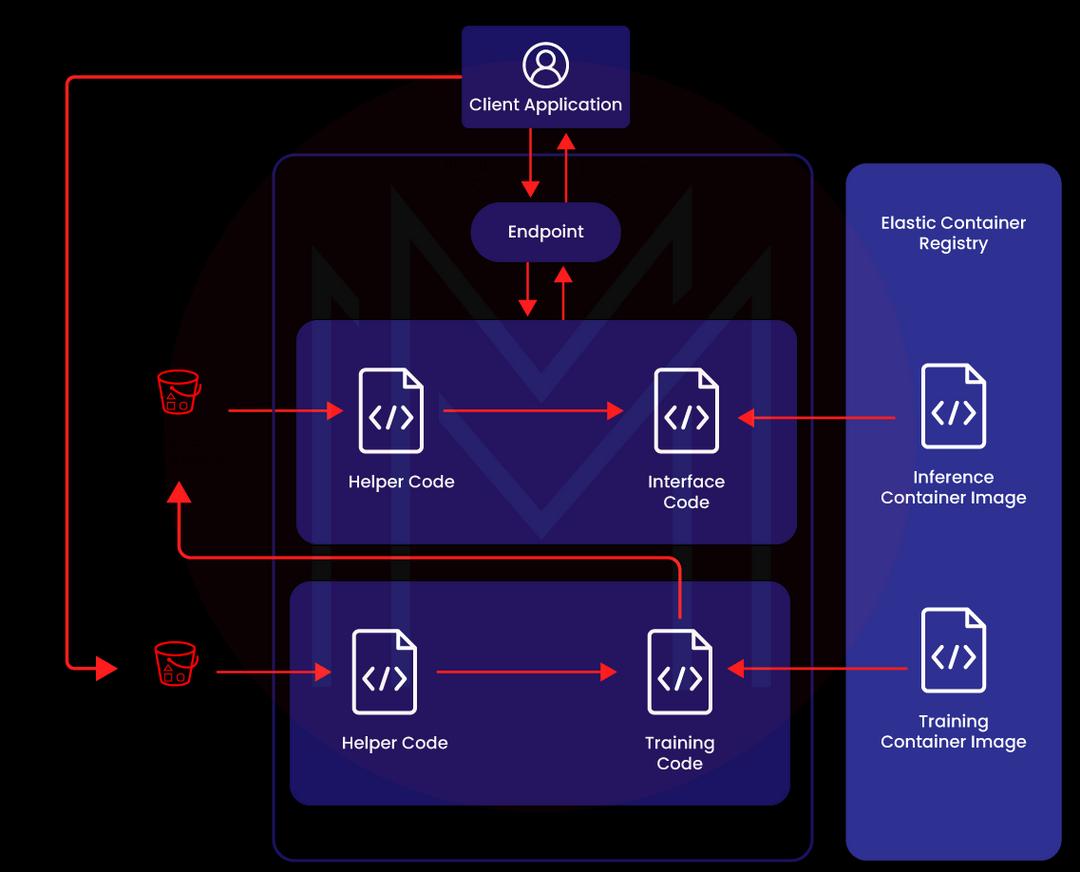
When training ML models, you can fetch input data from the Amazon S3 bucket. The AWS SageMaker launches the ML compute instances once you have built the training job. Then, you can train the ML model using the input data. Lastly, you store the output data in the AWS S3 bucket.
It is essential to note that SageMaker automatically scales its resources based on the requirements. Also, SageMaker uses distributed training libraries to train high-level ML models faster. Also, SageMaker uses third-party libraries such as Megatron, DeepSpeed, and others to train the models.

The above image shows the automated workflows in training ML models step by step. You can use high-performance GPUs as well as CPU instances to train ML models. However, Sagemaker generated billing only based on the resources used for the training. Developers and data scientists can use SageMaker or third-party libraries to increase training performance. Also, Sagemaker uses the training compiler to boost performance.
Moreover, Tuning is one of the crucial steps performed while training models. If training parameters don’t fall within limits, they are tuned to fit within them. It is essential to note that Sagemaker performs tuning ML models automatically.
In the next step, debugging is performed to detect errors in training data and modeling codes. Subsequently, profiling and experimentation are completed. You can store the model training results in an Amazon S3 bucket. Finally, you can deploy the model in the production environment and record the inferences.

How to evaluate ML models using AWS SageMaker?
Once you complete training ML models, you must evaluate the models' effectiveness. To assess the models, you must validate them by applying different methods. It will help you to choose the best-fit model.
We can evaluate ML models using the following four methods. It can be done with either live data or else historical data. Note that historical data is offline data.
Let’s go to the methods right now.
Offline testing with historical data
In this testing, we use historical data to validate ML models. So we can get results or inferences for the offline data. We can use Jupyter notebooks in SageMaker for making this testing. Besides, we can use a high-level Python library to perform this testing.
Testing with ‘Holdout set’
A holdout set is nothing but a part of training data. Usually, this data will be 20-30% of the training data. First, we need to use the holdout set to train an ML model and record inferences. Then, we need to train the model with the training data and record inferences. Lastly, we can compare both inferences and validate the model's effectiveness.
Online Testing with Live Data
In this testing, we use live data to validate ML models. The significant thing about this testing is that we allow only 10 % of the live data for evaluating a model. If we get satisfied with the model, we can allow 100% of the live data into the model.
Testing using the K-Fold method
SageMaker allows splitting the example data set into ‘k’ parts in this testing. Here, each ‘k’ part is assumed as a holdout set. We need to train an ML model using the parts separately. Then, we need to add the models to derive the final model. Usually, the ‘k’ value will be mainly between 5 to 10.
Key Features of AWS SageMaker
There are many features that AWS SageMaker offers to its users.
Let’s look at the brief of a few key features in the following one by one.
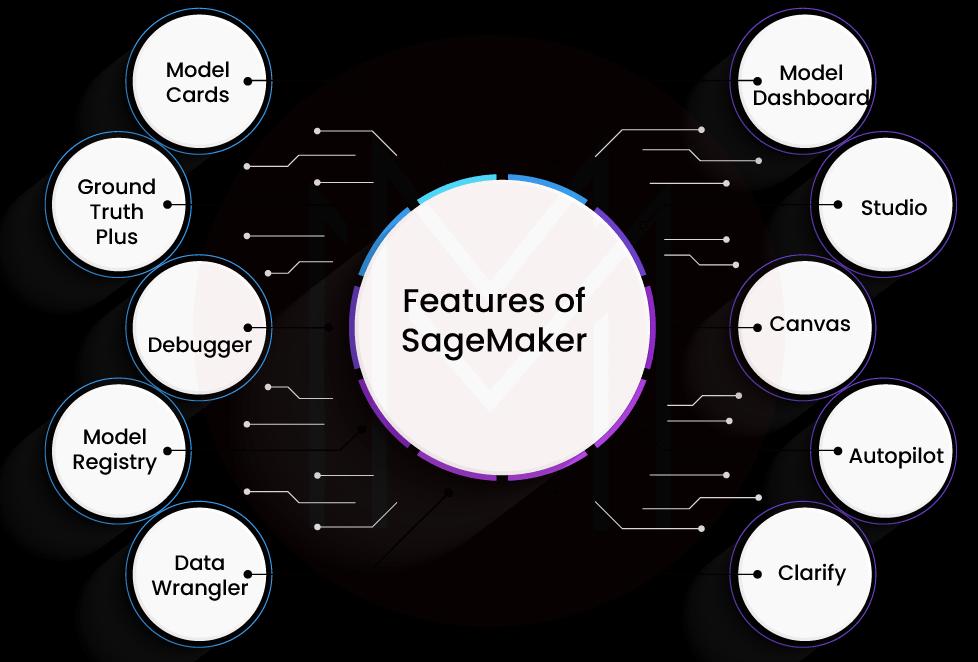
- SageMaker Model Cards: This is where you can document all the ML models for easy access. And the documents will be in that location throughout the ML model's lifecycle.
- SageMaker Model Dashboard: With this dashboard, you can view all the details of ML Models in one place. In other words, this dashboard collects information from various sources and unites them at a common point. So, you can easily track the performance of models in a single place.
- SageMaker Studio: It is an integrated ML environment. Creating, training, and deploying ML models can be done seamlessly using this studio.
- SageMaker Canvas: It is the automation tool of SageMaker, which supports developers and data scientists in building ML models without using codes.
- SageMaker Autopilot: This tool allows developers to build ML models even if they don’t have any expertise in ML algorithms. For example, they can build classification as well as regression models effortlessly.
- SageMaker Clarify: This tool helps to detect the elements that cause biases. It simplifies explaining the inferences generated by ML models.
- SageMaker Data Wrangler: SageMaker integrates this tool with ML workflows and simplifies pre-processing of training data. Simply put, this tool speeds up data preparation. This tool allows using only a few codes or no code.
- SageMaker Model Registry: This feature supports model versioning, smoothly approving workflows, and deploying ML models.
- SageMaker Debugger: This tool can automatically identify training data defects and model codes. This tool closely follows the training parameters as well as training data throughout the training process. Debugger alerts developers soon after it detects any deviation in the training process.
- SageMaker Ground Truth Plus: This tool helps to increase the quality of training datasets. Additionally, it avoids using any labeling application.
Use cases of AWS SageMaker
The use cases of AWS SageMaker are plenty. Below is a list of a few use cases.
- Finance: SageMaker is widely used in the finance industry to solve complex problems in accounting, tax preparation, etc.
- Healthcare: SageMaker, with its advanced ML algorithms, supports improved patient health monitoring. Mainly, SageMaker allows rapid scaling to manage any volume of patient data.
- Technology: With SageMaker, technological companies can track workforce behavior patterns. It helps to prevent incidents before they can occur. It is done by making accurate predictions. Further, SageMaker is extensively used in computer vision applications. SageMaker is also used in natural language processing (NLP) and natural language generation.
- Gaming: SageMaker supports rapid scaling. That is why it is highly used in gaming applications. It also helps to predict users’ expectations.
| Related Article: Amazon SageMaker |
Benefits of AWS SageMaker
No wonder AWS SageMaker provides countless benefits to its users. To list a few, AWS SageMaker:
- Quickly scales compute instances based on the demands
- Transforms raw input data into high-quality data
- Processes any volume of data effortlessly
- Offers robust security by detecting errors quickly
- Generates high-quality inferences or predictions
- Improves the efficiency of models using iterations
- Exchanges modeling codes in no time
- Scales up to thousands of GPUs rapidly.
- Reduces costs by running training jobs automatically
Pricing of AWS SageMaker
Following are the various pricing plans offered by AWS SageMaker.
Let’s have a close look at them below:
- Free plan: It is a free plan offered to users with limited features. For example, you can use Studio Notebooks, Data Wrangler, RStudio, Experiments, Canvas, etc.
- Savings plan: It is a unique plan of a SageMaker. As per this plan, the pricing is reduced up to 64 percent from the regular pricing. The significant thing about this plan is that pricing doesn’t change because of the type of instance size, family, or location.
- On-demand plan: This plan's pricing is based on the usage and the type of resources chosen. Also, it varies based on the features of SageMaker.
- TCO Plan: In this plan, SageMaker lowers TCO or Total Cost of Ownership by around 54 percent compared to other cloud-based fully-managed solutions. And this plan includes fixed years of subscription.
AWS SageMaker FAQs
1. What is AWS SageMaker used for?
AWS SageMaker is used for building, training, and deploying highly-sophisticated ML models. Mainly, SageMaker eliminates the complexity of building ML models. And it simplifies the training process. Besides, it scales seamlessly based on demands.
2. What are the advantages of SageMaker?
SageMaker offers many key advantages. It allows using compute resources dynamically. Also, SageMaker has a rich library of ML algorithms with which you can build advanced ML models. SageMaker offers Jupyter notebooks that help to develop, train and deploy ML models quickly.
3. What is the difference between SageMaker and AWS EC2?
SageMaker is the AWS platform used for building and deploying ML models. EC2 is another AWS service that offers virtual compute machines known as instances.
4. Is SageMaker a framework?
SageMaker is a platform that you can use to build, train and implement ML models. SageMaker supports frameworks such as TensorFlow, XGBoost, etc.
5. What is a SageMaker transformer?
It is a class with which you can create and interact with SageMaker transform jobs.
6. What is SageMaker in AWS?
Sagemaker is nothing but a hosted environment where you can create, train, and deploy ML models. Sagemaker supports creating ML models more quickly than any other platform.
7. What languages does SageMaker support?
SageMaker supports Java, Python, and C. It also supports front-end languages such as CSS, HTML, and JavaScript.
Conclusion
At a glance, AWS Sagemaker is the platform that supports creating, training, and deploying ML models in the production-ready environment. You can build cost-effective and sophisticated ML models with the help of SageMaker. Above all, SageMaker can scale rapidly – no matter the training data size. We hope this blog might have helped you learn what is AWS SageMaker and associated things in greater detail. But, if you aspire to learn more about AWS SageMaker, you can enroll in "AWS Training" and get a certification.
 On-Job Support Service
On-Job Support Service
Online Work Support for your on-job roles.

Our work-support plans provide precise options as per your project tasks. Whether you are a newbie or an experienced professional seeking assistance in completing project tasks, we are here with the following plans to meet your custom needs:
- Pay Per Hour
- Pay Per Week
- Monthly
| Name | Dates | |
|---|---|---|
| AWS Training | Aug 04 to Aug 19 | View Details |
| AWS Training | Aug 08 to Aug 23 | View Details |
| AWS Training | Aug 11 to Aug 26 | View Details |
| AWS Training | Aug 15 to Aug 30 | View Details |

Madhuri is a Senior Content Creator at MindMajix. She has written about a range of different topics on various technologies, which include, Splunk, Tensorflow, Selenium, and CEH. She spends most of her time researching on technology, and startups. Connect with her via LinkedIn and Twitter .














