
- Introduction to Amazon Elastic File System
- Amazon On-Demand Instance Pricing
- AWS Kinesis
- Amazon Redshift Tutorial
- Amazon SageMaker - AIs Next Game Changer
- AWS Console - Amazon Web Services
- AWS Architect Interview Questions
- AWS Architecture
- Amazon Athena
- Top 11 AWS Certifications List and Exam Learning Path
- How to Create Alarms in Amazon CloudWatch
- AWS CloudWatch Tutorial
- Introduction To AWS CLI
- AWS Configuration
- AWS Data Pipeline Documentation
- AWS EC2 Instance Types
- AWS Elastic Beanstalk
- AWS Elastic Beanstalk Available in AWS GovCloud (US)
- AWS Free Tier Limits and Faq
- AWS EC2 Instance Pricing
- Choosing The Right EC2 Instance Type For Your Application
- AWS Interview Questions and Answers
- AWS Key Management Service
- AWS Lambda Interview Questions
- AWS Lambda Tutorial
- What Is AWS Management Console?
- Complete AWS Marketplace User Guide
- AWS Outage
- AWS Reserved Instances
- AWS SDK
- What is AWS SNS?
- AWS Simple Queue Service
- AWS SysOps Interview Questions
- AWS vs Azure
- AWS Vs Azure Vs Google Cloud Free Tier
- Introduction to AWS Pricing
- Brief Introduction to Amazon Web Services (AWS)
- Clean Up Process in AWS
- Creating a Custom AMI in AWS
- Creating an Elastic Load Balancer in AWS
- How to Deploy Your Web Application into AWS
- How to Launch Amazon EC2 Instance Using AMI?
- How to Launch Amazon EC2 Instances Using Auto Scaling
- How to Sign Up for the AWS Service?
- How to Update Your Amazon EC2 Security Group
- Process of Installing the Command Line Tools in AWS
- Big Data in AWS
- Earning Big Money With AWS Certification
- AWS Certification Without IT Experience. Is It Possible?
- How to deploy a Java enterprise application to AWS cloud
- What is AWS Lambda?
- Top 10 Reasons To Learn AWS
- Run a Controlled Deploy With AWS Elastic Beanstalk
- Apache Spark Clusters on Amazon EC2
- Top 35 AWS Services List
- What is Amazon S3? A Complete AWS S3 Tutorial
- What is AMI in AWS
- What is AWS? Amazon Web Services Introduction
- What is AWS Elasticsearch?
- What is AWS ELB? – A Complete AWS Load Balancer Tutorial
- What is AWS Glue?
- AWS IAM (Identity and Access Management)
- AWS IoT Core Tutorial - What is AWS IoT?
- What is Cloud Computing - Introduction to Cloud Computing
- Why AWS Has Gained Popularity?
- Top 10 Cloud Computing Tools
- AWS Glue Interview Questions
- AWS S3 Interview Questions
- AWS Projects and Use Cases
- AWS VPC Interview Questions and Answers
- AWS EC2 Tutorial
- AWS VPC Tutorial
- AWS EC2 Interview Questions
- AWS DynamoDB Interview Questions
- AWS API Gateway Interview Questions
- How to Become a Big Data Engineer
- What is AWS Fargate?
- What is AWS CloudFront
- AWS CloudWatch Interview Questions
- What is AWS CloudFormation?
- What is AWS Cloudformation
- Cloud Computing Interview Questions
- What is AWS Batch
- What is AWS Amplify? - AWS Amplify Alternatives
- Types of Cloud Computing - Cloud Services
- AWS DevOps Tutorial - A Complete Guide
- What is AWS SageMaker - AWS SageMaker Tutorial
- Amazon Interview Questions
- AWS DevOps Interview Questions
- Cognizant Interview Questions
- Cognizant Genc Interview Questions
- Nutanix Interview Questions
- Cloud Computing Projects and Use Cases
- test info
- AWS Server and Administration
- AWS vs Alternatives
Amazon has provided a broad-gauged, compendious platform named AWS (Amazon Web Services), which is a fusion of various offerings such as platform as a service (PaaS), infrastructure as a service (IaaS), and packaged software as a service (SaaS). AWS services offer many organizational tools: content delivery, computing power, and database storage. These tools are used in the data centers of around 190 different countries.
Nonprofit private organizations, educational institutions, and government agencies are some organizations that use AWS services.AWS Glue is a managed service by AWS, and it does not require any infrastructure to be set up or managed. AWS Glue can work with structured or even semi-structured data, and its console can be used in querying, transforming, and discovering data. The console can edit and modify the ETL scripts generated and executed.
AWS Glue Tutorial - Table of Content
- What is AWS Glue?
- What is the use of AWS Glue?
- AWS Glue vs Lambda?
- Components of AWS Glue
- Key Features
- AWS Glue Terminology
- How does AWS Glue work?
What is AWS Glue?
AWS Glue is a perfectly and skillfully addressed ETL (extract, transform and load) service to automate the process of data analysis. It has dramatically reduced the time taken for preparing the data for analysis. It automatically discovers and lists the data using AWS Glue Data Catalog, suggests, selects, and generates the Python or Scala code for data transmission from the source, loads and transforms the Job based on the timed events, providing flexible schedules and developing Apache Spark environment that is scalable for a targeted data loading.
Alteration, balancing and security, and monitoring of Complex data streams are provided by AWS Glue service. AWS Glue offers a serverless solution by making the complex operations involved in application development elementary. AWS Glue also provides quick integration procedures for merging various valid data and breakdown and authorizing the data in no time.
AWS Glue is a contended, cost-effective ETL (extract, transform, and load) service used to clean, enhance, categorize, and move the data securely among the data streams and stores. AWS Glue acts as a center of metadata repository called AWS Glue Data Catalog, a flexible scheduler to handle dependency resolution, data retrieval, and job monitoring, and an ETL engine to automatically generate Python or Scala code. As the AWS Glue is serverless, there is no need to set up or manage infrastructure.
What is the use of AWS Glue?
AWS Glue is applicable in all the stages of Data Warehousing, i.e., from the extraction of data to visualization. The Glue in AWS authorizes other tools like Athena, Amazon Redshift, and S3 Data Lake. It helps in highlighting the delivery issues and tracks and creates the ETL pipelines by using monitors and alarms. By integrating data from all the sources, AWS Glue optimizes the data visualization process.
There are various tools and widgets to track the progress, and any issues that may come up in the future are alerted through email and slack notifications. Data is constructed for analytics through AWS Glue with customized cleaning, maintaining, and categorizing data. The significant uses of AWS Glue are
- Cost-Effective
- Less Hassle
- Proper scheduling of Job
- Serverless
- Raised visibility of data
- Pay-as-per-usage
- More Power
- Automatic ETL functioning
| Want to take your Cloud knowledge to next level? Click here to Enroll AWS Online Training Course. |
AWS Glue vs Lambda?
- Lambda runs faster for smaller loads, whereas Glue runs faster for larger workloads.
- Various languages, such as Go, Java, Node.js, Python, etc., are used by Lambda to execute jobs, whereas AWS Glue can only use Python or Scala code.
- The run time of Lambda is very low for smaller tasks, and the initialization of Glue jobs requires more extended time for its distributed processing.
- Triggers execute code in Lambda from other services like DynamoDB, CloudWatch, SQS, Kafka, etc., whereas Glue code is executed and triggered by lambda events, manually or through scheduling the events.
- Lambda needs complex coding to integrate data sources such as DBs running on ECS instances, DynamoDB, S3, Redshift, etc. Glue can easily be combined with any of the sources.
- Glue has additional components such as a scheduler to handle the job execution time, and Data Catalog, which acts as a store, unlike Lambda.
[Related Article: AWS Tutorial]
Components of AWS Glue
The essential components of AWS Glue are
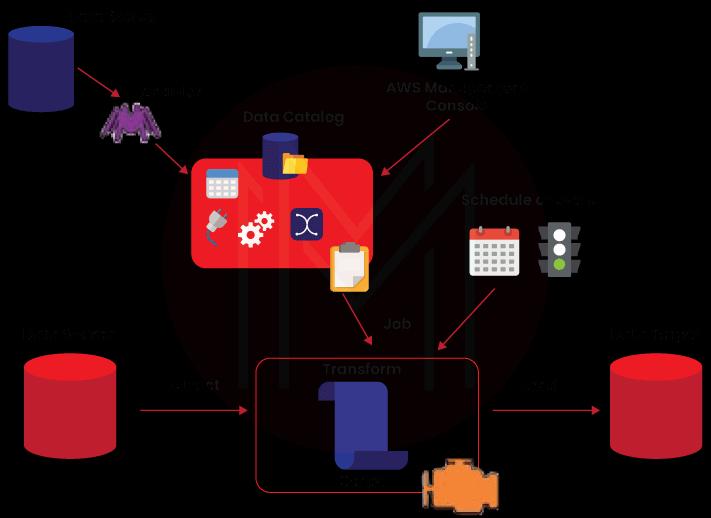
AWS Glue Data Catalog
The data catalog acts as a central metadata storehouse by creating tables to store the metadata information. Every table in this AWS Glue Data Catalog points to a single data store. Precisely, it acts as an index to the schema storing runtime metrics and location, which are very helpful in identifying the sources and targets of the ETL jobs.
Job Scheduling System
This system automates and binds the ETL pipelines. The AWS Glue Job Scheduling System plays a crucial role as it maintains the timing in the system. The scheduler is flexible and can set up triggers based on the events and job execution.
ETL Engine
The component of AWS Glue that addresses the code generation is the ETL engine. The code is automatically presented in Python or Scala, and it is open code allowing the users to customize the code.

Key Features
This approach collected the whole data from various parts of the business and stored it centrally in a data warehouse by storing the business information in a single place. The following are the essential features of AWS Glue.
- The resources are automated to scale the current needs of the situation.
- Schedules, specific events, or triggers decide the execution of ETL jobs.
- The changes made to the database schema and services are easily recognized for quick response.
- Metrics, Logs of ETL procedures, and KPIs (Key Performance Indicators) are reported and monitored by AWS Glue.
- Metadata and the data sources are securely archived in AWS Glue Data Catalog.
- AWS Glue handles the errors with the error handling mechanism and resolves a pile-up of issues.
- ETL scripts are generated for a rich experience when data is transferred from source to target.
[Related Article: ETL Tutorial]
AWS Glue Terminology
The terms used in Amazon Web Services Glue are briefly explained below:
Classifier
The classifier provides information on the schema, i.e., a description of the data. File types such as CSV, XML, JSON, etc., have different classifiers provided by AWS Glue.
AWS Glue Data Catalog
The data catalog is a storehouse of metadata. The reference sources and the targets used in the ETL jobs are stored in the AWS Glue Data Catalog tables. It categorizes the data and saves it in a Data Warehouse or Data Lake. The index to location and schema of the data present in the storehouse is contained by the data catalog and written in the container of tables.
Connection
When there is a need to connect the data catalog to a particular table, the "connection" property is required. When the data source and the target are the same, there is no need to establish any connection.
Database
The database collects data in tables from various sources, and the tables are arranged in separate categories.
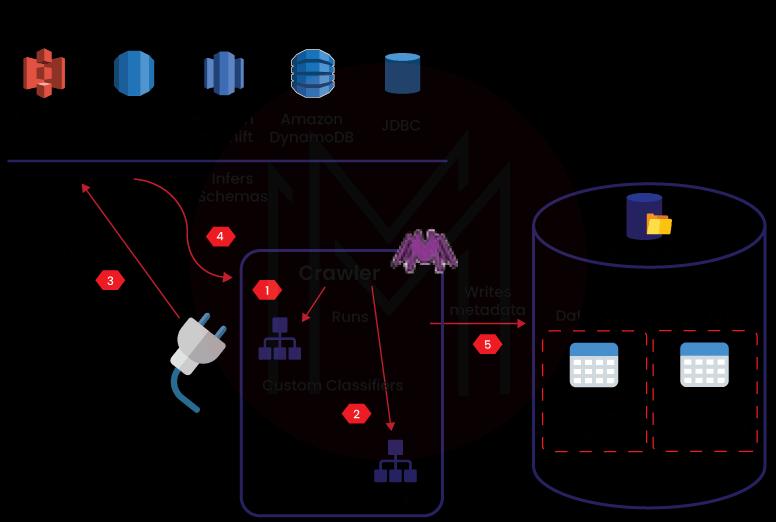
Crawler
The AWS Glue Data Catalog is filled in with metadata using a crawler. The filling is done by pointing the crawler at a data store in the data catalog. Crawlers can turn the semi-structured data into a relational schema.
Data Target, Data Source, and Data Store
Data Store is storing the data in a repository. Though Data Store and Data Source are similar, Data Source is used as input data for transformations. This transformed data is written to a Data Target, a Data Store.
Dynamic Frame
The limitations of Frames in Apache Spark are subdued by the Dynamic Frames used in AWS Glue. Each record describes itself and undergoes advanced transformation operations for ETL and data cleaning. Dynamic Frame can also be converted to Data Frame and reversed.
Script
The data is extracted, worked upon, inserted into the data target, and stored from various data sources using the scripts like Python and Scala.
Job
ETL (Extract, Transform, Load) scripts create a job. Time intervals can be scheduled to run the assignments, and also sometimes, the jobs are run on demand.
Table
Tables contain the definition of the data and can be in any form, i.e., a file like S3 files or a service like an amazon RD service.
| Preparing for AWS Glue Interview? Here Are the Top AWS Glue Interview Questions and Answers |
How does AWS Glue work?
AWS Glue uses AWS services to successfully carry out the ETL (extract, transform, and load) jobs by building data warehouses and data lakes and obtaining the desired output streams. AWS Glue also uses API operations to change, create, and store the data from different sources and set the jobs' alerts.
The services are connected using an application by the AWS Glue console for monitoring the ETL work, which solely carries out all the operations. AWS Glue also creates an infrastructure for the ETL tool to run the workload. In Data Catalog, jobs are created using table definitions. The jobs created contain the scripts used for data transformation, i.e., initiating a job or scheduling an event.
Conclusion
Being a cost-effective and serverless service provider makes AWS Glue, a gem among the providers. AWS Glue gives easy tools to use and can help categorize, sort, validate, enhance, and move data stored in warehouses and data lakes. Semi-structured or clustered data can be worked upon using AWS Glue. This service is amicable in running other Amazon services and offers centralized storage by combining data from various sources and getting ready for different phases like reporting and data analysis. The AWS Glue service cinches high efficiency and performance with its seamless integration with other platforms for easy and speedy data analysis at a low cost.
 On-Job Support Service
On-Job Support Service
Online Work Support for your on-job roles.

Our work-support plans provide precise options as per your project tasks. Whether you are a newbie or an experienced professional seeking assistance in completing project tasks, we are here with the following plans to meet your custom needs:
- Pay Per Hour
- Pay Per Week
- Monthly
| Name | Dates | |
|---|---|---|
| AWS Training | Jul 18 to Aug 02 | View Details |
| AWS Training | Jul 21 to Aug 05 | View Details |
| AWS Training | Jul 25 to Aug 09 | View Details |
| AWS Training | Jul 28 to Aug 12 | View Details |

Madhuri is a Senior Content Creator at MindMajix. She has written about a range of different topics on various technologies, which include, Splunk, Tensorflow, Selenium, and CEH. She spends most of her time researching on technology, and startups. Connect with her via LinkedIn and Twitter .














